一眼看懂
封面预览
论文关注 Vision-Language-Action (VLA) 模型在资源受限机器人平台上的部署问题,旨在解决高内存和计算需求带来的挑战。
- 论文关注 Vision-Language-Action (VLA) 模型在资源受限机器人平台上的部署问题,旨在解决高内存和计算需求带来的挑战。
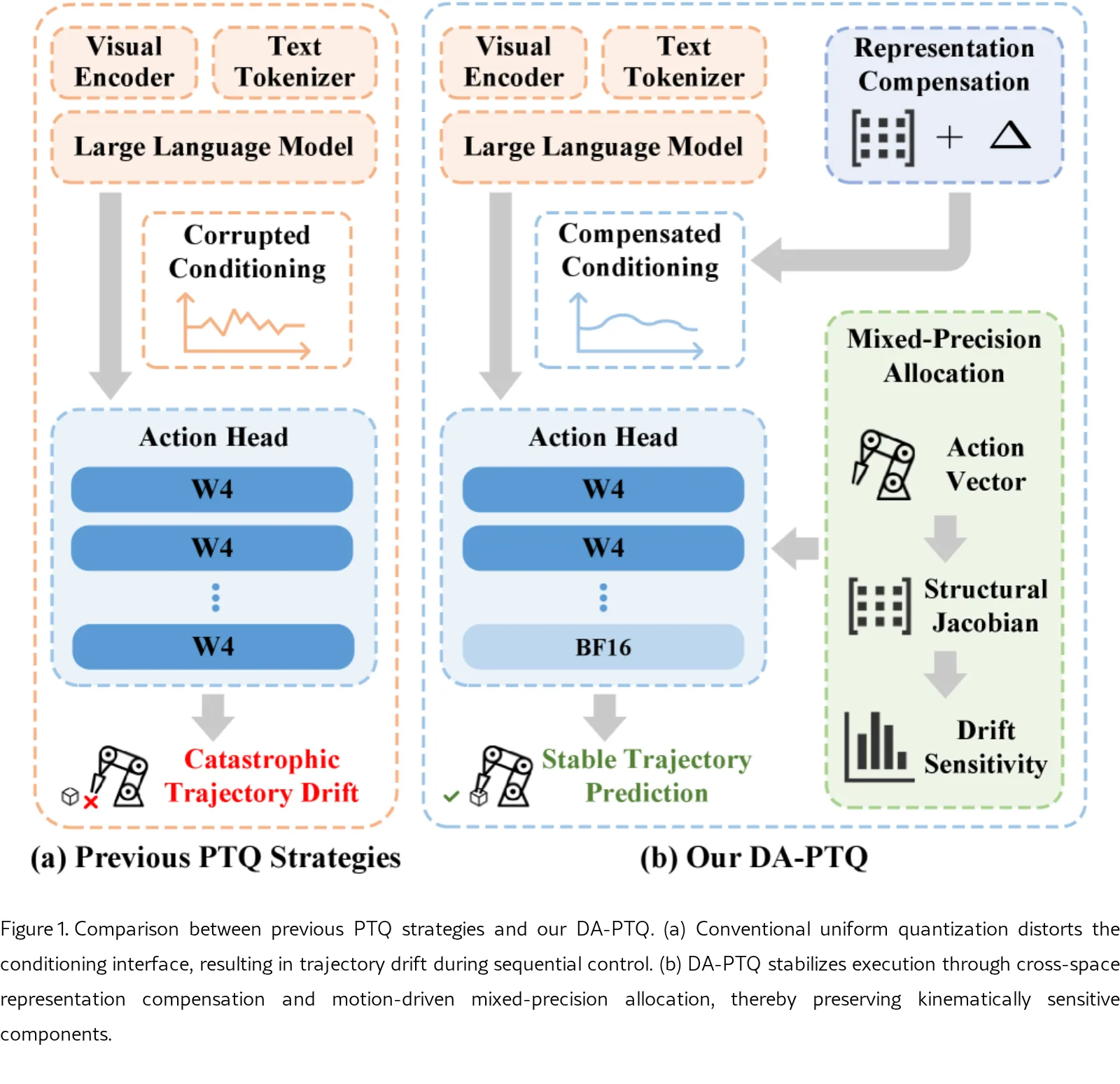
- 指出传统后训练量化(PTQ)在 VLA 模型中会导致严重的性能下降,核心原因在于量化误差在序列控制过程中的时间累积引发了运动漂移。
- 提出了 DA-PTQ 框架,通过漂移感知的优化策略,在无需重训练的情况下实现高效压缩,同时保持控制轨迹的稳定性。
Card 01
研究单位
研究单位
- Tongji University
- University of Technology Sydney
Card 02
论文概述
论文概述
- 论文关注 Vision-Language-Action (VLA) 模型在资源受限机器人平台上的部署问题,旨在解决高内存和计算需求带来的挑战。
- 指出传统后训练量化(PTQ)在 VLA 模型中会导致严重的性能下降,核心原因在于量化误差在序列控制过程中的时间累积引发了运动漂移。
- 提出了 DA-PTQ 框架,通过漂移感知的优化策略,在无需重训练的情况下实现高效压缩,同时保持控制轨迹的稳定性。
Card 03
核心贡献
核心贡献
- 系统分析了 VLA 模型量化中的误差累积机制,揭示了量化扰动与序列具身控制相互作用导致的运动漂移瓶颈。
- 提出了 DA-PTQ 框架,包含跨空间表示补偿(CSRC)和运动驱动的混合精度分配(DA-MPA)两个核心组件,无需引入额外推理开销。
- 实验证明该方法在低比特设置下显著减少了运动漂移,实现了与全精度模型相当的性能,并支持实际的机器人部署。
Card 04
方法描述
方法描述
- 跨空间表示补偿:通过轻量级仿射变换和低秩更新,对齐量化激活与全精度激活的一阶和二阶统计特性,修正感知-动作接口处的分布畸变。
- 运动驱动的混合精度分配:构建虚拟平面串联链模型并推导结构雅可比矩阵,量化各动作维度对长期漂移的敏感度,据此为网络层分配比特宽度。
- 整体流程分为漂移分析、表示补偿校准和精度分配三个阶段,所有补偿参数均被融合进量化权重中。
Card 05
数据集与资源
数据集与资源
- 校准数据集:从 BridgeData V2 中提取的 512 条代表性轨迹。
- 评估基准:SimplerEnv 模拟环境,涵盖 WidowX 机器人和 Google Robot 两种具身形态。
- 基础模型:基于扩散策略的 CogAct VLA 模型。
- 量化设置:采用 W4A8 混合精度量化方案(权重 4-bit,激活 8-bit,敏感层保留 BF16)。
Card 06
评估与结果
评估与结果
- 评估指标包括任务成功率、内存减少比例和推理加速比例。
- 在 SimplerEnv 基准上,DA-PTQ 实现了 42.5% 的内存减少和 54.8% 的推理加速。
- 在 WidowX 任务中,平均成功率达到 48.9%,显著优于基准方法 QuantVLA (43.5%),接近全精度模型性能。
- 消融实验证明了跨空间表示补偿和混合精度分配两个模块在缓解漂移和提升性能方面的协同作用。