一眼看懂
封面预览
研究目标:解决视觉-语言-动作(VLA)模型中的语言忽视(language ignorance)和机器人不稳定性(robotic instab…
- 研究目标:解决视觉-语言-动作(VLA)模型中的语言忽视(language ignorance)和机器人不稳定性(robotic instab…
- 核心问题:
- 现有VLA模型依赖视觉捷径而非指令语义,导致语言不敏感
Card 01
研究单位
研究单位
- University of Illinois Chicago(伊利诺伊大学芝加哥分校),美国
- 主要作者:Nastaran Darabi、Amit Ranjan Trivedi
- 联系方式:(ndarab2, amitrt)@uic.edu
- 项目主页:https://nstrndrbi.github.io/ProGAL
Card 02
论文概述
论文概述
- 研究目标:解决视觉-语言-动作(VLA)模型中的语言忽视(language ignorance)和机器人不稳定性(robotic instability)问题
- 核心问题:
- 现有VLA模型依赖视觉捷径而非指令语义,导致语言不敏感
- 符号化目标与3D场景中可执行实体的对应关系缺乏验证机制
- 控制层操作未验证的表示,产生语义和物理失败
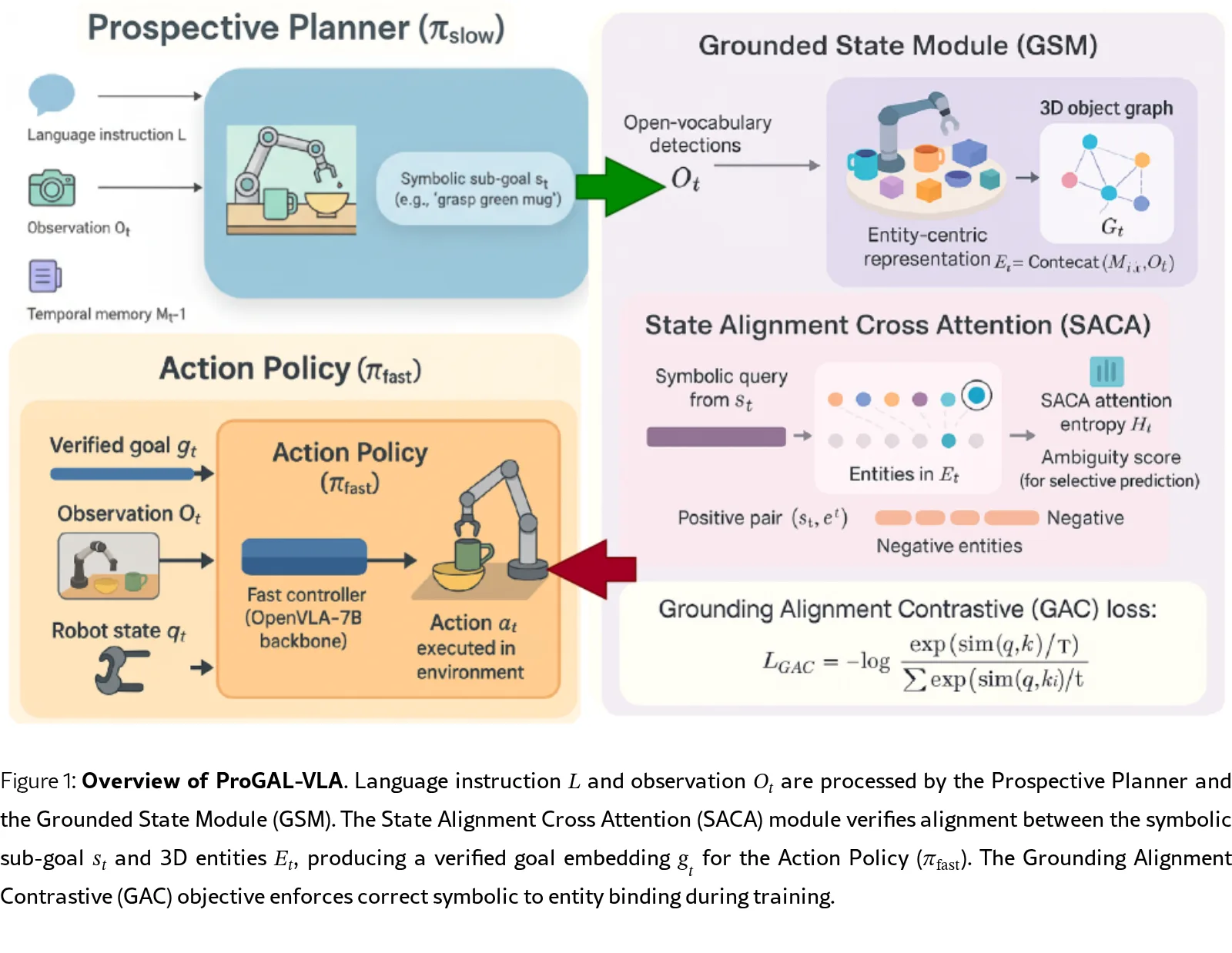
- 研究方法:提出ProGAL-VLA(前瞻性接地与对齐VLA),通过分层架构引入验证瓶颈,确保语言意图在行动执行前已通过3D实体验证
Card 03
核心贡献
核心贡献
- 前瞻性规划器(π_slow):使用Qwen-2.5-VL-Instruct-7B生成符号化子目标,将指令规范化以降低词汇熵
- 接地状态模块(GSM):构建以3D实体为中心的图结构,将对象身份与姿态、外观解耦
- 状态对齐交叉注意力(SACA):执行核心接地验证,将符号目标绑定到具体3D实体,生成验证后的目标嵌入g_t
- 接地对齐对比(GAC)损失:强制符号子目标与3D实体的对齐,优化InfoNCE下界
- 熵值歧义检测:SACA注意力熵提供内在歧义信号,支持选择性预测和校准的不确定性估计
Card 04
方法描述
方法描述
- 分层架构:分离推理(π_slow)与控制(π_fast),通过验证瓶颈连接
- 验证瓶颈机制:任何动作执行前,符号目标必须绑定到可物理到达的实体
- GAC对比学习:将符号子目标 tokens 与3D实体嵌入对齐,解决绑定问题
- 离线对齐对生成:通过教师VLM分割演示生成符号计划,构建3D跟踪器,时空匹配选择接地实体
- 行动策略:仅依赖验证后的目标嵌入g_t和感知证据,不使用原始语言特征
Card 05
数据集与资源
数据集与资源
- 评估基准:
- LIBERO-Plus:VLA语言忽视现象的基准测试
- Custom Ambiguity Benchmark(CAB):自定义歧义检测基准,包含32/8/8个场景(训练/验证/测试),2400条指令(明确/模糊各1200条)
- 模型规模:
- π_fast:OpenVLA-7B(与基线相同)
- π_slow:Qwen-2.5-VL-Instruct-7B(每回合仅调用一次)
- 感知:YOLO-World(开集检测)
- 推理延迟:总计96.4ms(检测器43.0ms + GSM 15.8ms + SACA 10.7ms + π_fast 26.9ms),吞吐量10.31 FPS
Card 06
评估与结果
评估与结果
- LIBERO-Plus鲁棒性:
- 总体得分:85.5%(vs 基线OpenVLA 17.3%)
- 机器人扰动:30.3% → 71.5%
- 布局变化:77.6% → 86.7%
- 语言扰动:85.8% → 93.6%
- 语言忽视降低:简单/空间/关系指令从(0.36, 0.49, 0.57)降至(0.08, 0.14, 0.19),降低3-4倍
- 实体检索:Recall@1从0.41 → 0.71(N=8),从0.15 → 0.41(N=32)
- CAB歧义检测:
- AUROC:0.52 → 0.81,AUPR:0.49 → 0.79
- 模糊输入澄清率:0.09 → 0.81
- 明确指令成功率:0.74 → 0.89
- 消融实验:完整ProGAL-VLA在所有指标上优于各消融变体,验证了分层规划、GSM结构、GAC目标的各自贡献