一眼看懂
封面预览
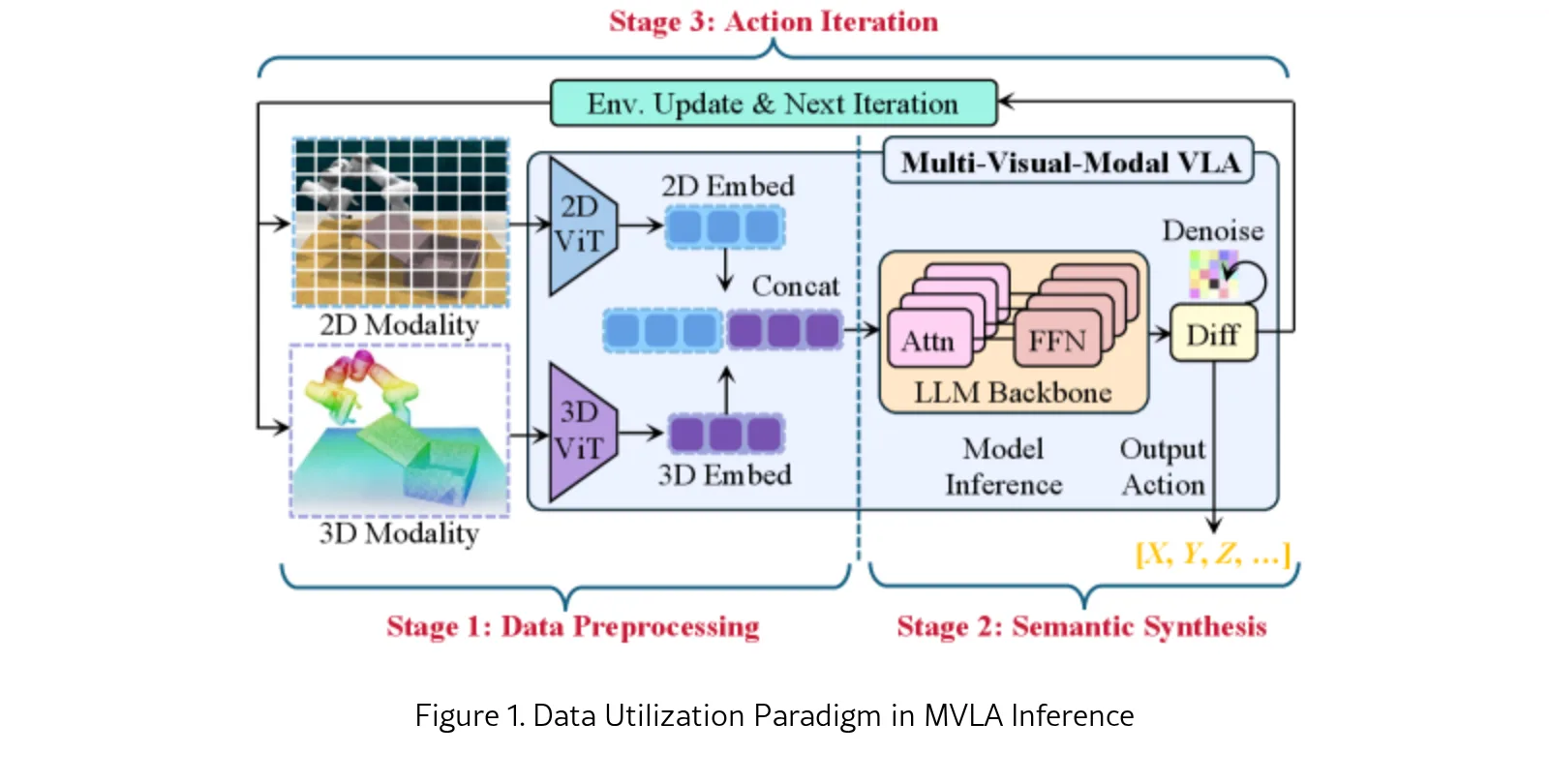
研究针对多视觉模态VLA模型(MVLA)的推理加速问题,MVLA在2D图像基础上整合3D点云数据以增强空间感知能力
- 研究针对多视觉模态VLA模型(MVLA)的推理加速问题,MVLA在2D图像基础上整合3D点云数据以增强空间感知能力
- 核心问题:模态扩展导致输入token数量快速增加,现有的token剪枝方法针对2D单模态VLA设计,忽略了2D/3D模态显著性的差异
- 研究目标:通过三阶段分析揭示2D/3D模态显著性差异和动态变化,并设计相应的三阶段token剪枝框架
Card 01
研究单位
研究单位
- 北京大学计算机学院(Zihao Zheng, Chenyue Li, Ziyun Zhang, Guojie Luo, Xiang Chen)
- 中兴通讯股份有限公司(Hong Gao, Yuchen Huang, Yutong Xu)
- 北京师范大学人工智能学院(Sicheng Tian)
- 中国地质大学(武汉)计算机学院(Zhihao Mao)
- 北京大学电子工程与计算机科学学院(Lingyue Zhang)
Card 02
论文概述
论文概述
- 研究针对多视觉模态VLA模型(MVLA)的推理加速问题,MVLA在2D图像基础上整合3D点云数据以增强空间感知能力
- 核心问题:模态扩展导致输入token数量快速增加,现有的token剪枝方法针对2D单模态VLA设计,忽略了2D/3D模态显著性的差异
- 研究目标:通过三阶段分析揭示2D/3D模态显著性差异和动态变化,并设计相应的三阶段token剪枝框架
Card 03
核心贡献
核心贡献
- 提出三阶段分析(Tri-Stage Analysis),揭示MVLA模型中2D/3D模态显著性的差异和动态变化规律
- 基于分析结果开发三阶段token剪枝框架,自动选择最优剪枝配置,实现高效剪枝
- 在模拟环境和真实机器人任务上验证框架有效性,达到2.55倍推理加速,仅增加5.8%开销
- 发现2D模态在数据预处理阶段显著性更高,而3D模态在目标物体和机器人区域的语义合成阶段具有更高的独特信息贡献
Card 04
方法描述
方法描述
- 第一阶段(数据预处理):利用模型输出特征的L1范数量化2D/3D模态显著性,设置双阈值机制确定剪枝候选集
- 第二阶段(语义合成):通过注意力分数聚类将token划分为背景、机器人主体、目标物体三个语义集,实现跨语义集的显著性分解
- 第三阶段(动作迭代):引入时间分割和显著性预测机制,捕捉动作迭代过程中模态显著性的动态波动
- 三个阶段的机制融合形成最终的token剪枝决策
Card 05
数据集与资源
数据集与资源
- 模拟基准:RLBench机器人学习基准
- 真实世界环境:实际机器人操作任务
- 测试模型:MLA(Multi-sensory Language-Action Model)等MVLA模型
- 评估任务:Close Box、Close Fridge、Close Laptop、Sweep Dustpan、Phone on Base等
Card 06
评估与结果
评估与结果
- 在模拟基准上,框架在多个任务中实现最高2.55倍加速,任务成功率(SR)保持稳定或略有提升
- 相比仅剪枝2D或仅剪枝3D的方法,三阶段框架能够更合理地分配剪枝预算
- 框架开销仅为5.8%,验证了其轻量级设计
- 在真实世界任务中同样表现出色,验证了方法的泛化能力