一眼看懂
封面预览
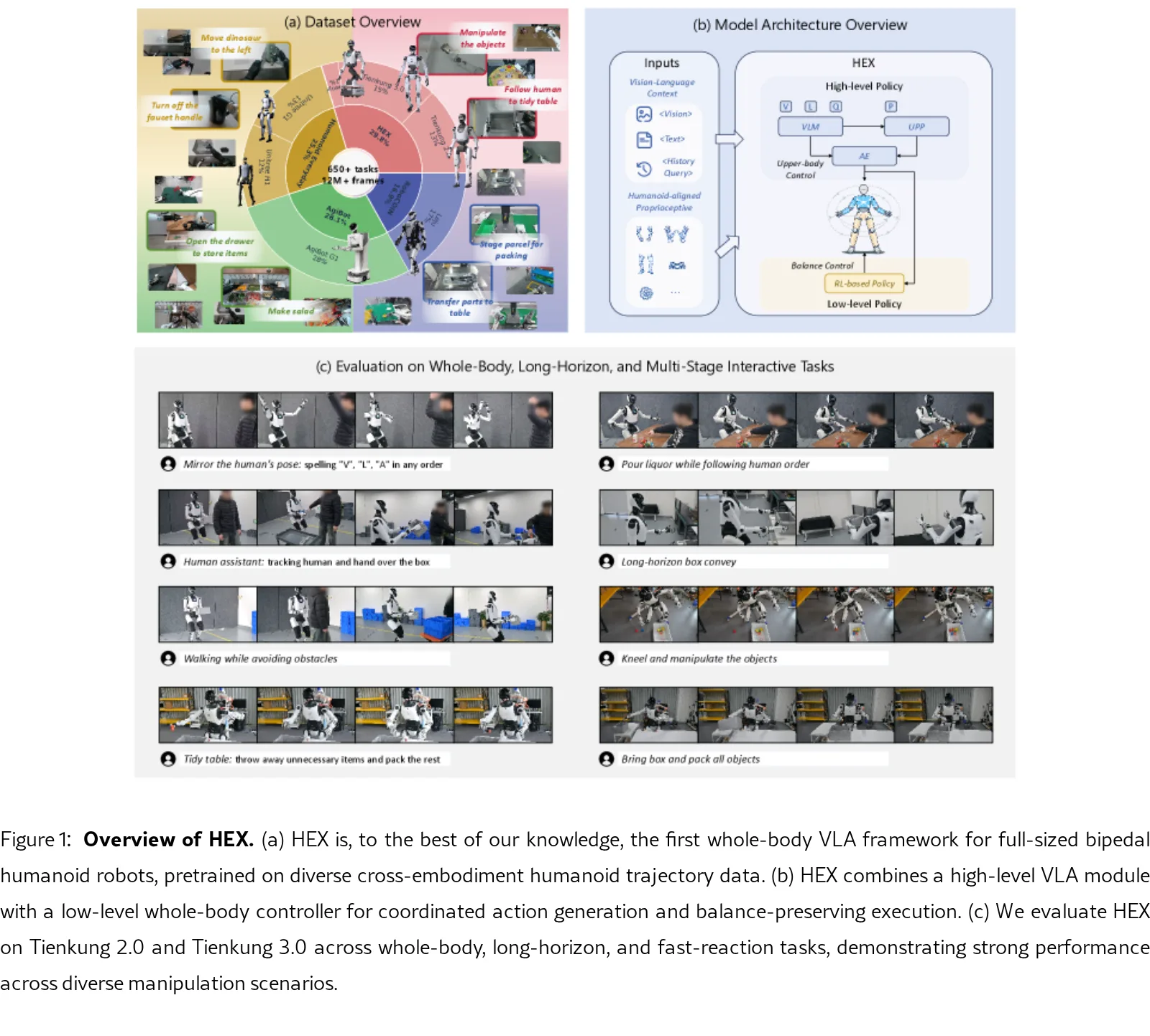
提出名为 HEX 的框架,是首个用于全尺寸双足人形机器人全身操作的视觉-语言-动作(VLA)框架。
- 提出名为 HEX 的框架,是首个用于全尺寸双足人形机器人全身操作的视觉-语言-动作(VLA)框架。
- 旨在解决现有VLA模型将机器人身体部位独立处理,导致高自由度人形控制困难和不稳定的问题。
- 通过引入人形对齐的通用状态表示和预测性本体感受建模,实现跨异构具身的可扩展学习与协调的全身操控。
Card 01
研究单位
研究单位
- Beijing Innovation Center of Humanoid Robotics
- Xi’an Jiaotong University
- Nankai University
- Peking University
Card 02
论文概述
论文概述
- 提出名为 HEX 的框架,是首个用于全尺寸双足人形机器人全身操作的视觉-语言-动作(VLA)框架。
- 旨在解决现有VLA模型将机器人身体部位独立处理,导致高自由度人形控制困难和不稳定的问题。
- 通过引入人形对齐的通用状态表示和预测性本体感受建模,实现跨异构具身的可扩展学习与协调的全身操控。
Card 03
核心贡献
核心贡献
- 提出了首个针对全尺寸双足人形机器人的全身VLA框架。
- 设计了跨具身人形对齐状态表示与 Unified Proprioceptive Predictor (UPP) 用于可扩展的全身预训练。
- 引入“回顾与预测”范式,结合轻量级视觉历史总结、未来状态预测与自适应多模态融合来生成动作。
- 在真实世界人形操作基准上进行了大量实验,展示了超越现有最先进方法的性能,特别是在快速反应和长视野场景。
Card 04
方法描述
方法描述
- 采用分层架构:高层 VLA 策略输出任务相关动作,底层 RL 全身控制器生成保持平衡的动态可行全身运动。
- 高层策略包含三个核心组件:Visual-Language Model (VLM) 模块编码当前视觉语言上下文;UPP 使用基于形态学的 Mixture-of-Experts (MoE) 模块建模全身协调和预测未来状态动态;动作专家通过自适应融合机制整合视觉语言与本体感受特征生成动作。
- 使用轻量级历史查询特征缓存,避免推理时重复编码历史图像,有效利用时间视觉上下文。
Card 05
数据集与资源
数据集与资源
- 预训练数据集:包含超过 12M 帧,来自七个异构人形具身(如 Tienkung 2.0/3.0、Unitree G1/H1、AgiBot 等),涵盖自建 HEX 数据集、Humanoid Everyday 数据集、AgiBot World Colosseo、RoboCOIN 等。
- 模型规模:总参数量约 2.4B,基于 Qwen3-VL-2B-Instruct;UPP为4层Transformer,动作头为16层 DiT-B。
- 训练资源:预训练约需 1K A100 GPU小时。
Card 06
评估与结果
评估与结果
- 评估环境:在真实世界人形机器人 Tienkung 2.0 和 Tienkung 3.0 上进行,包含七个所见任务(如姿势模仿、倒酒、整理桌面等)和一个长视野任务(盒子传送)。
- 主要评估指标:任务成功率。
- 关键实验结果:
- 在所见场景中,HEX 平均成功率达 79.8%,超越所有基线(如 ACT、GR00T N1.5、π0.5)。
- 在长视野盒子传送任务中,HEX 在最终“放置盒子”阶段成功率达 53.3%,比最强基线高出约 15%。
- 在泛化测试(包含视觉干扰、光照变化、动态场景等)中,HEX 平均成功率达 61.8%,显著优于其他方法。