一眼看懂
封面预览
研究机器人在共享工作空间中与其他智能体协作时,如何检测协作方在任务执行过程中发生的行为策略转换
- 研究机器人在共享工作空间中与其他智能体协作时,如何检测协作方在任务执行过程中发生的行为策略转换
- 解决现有方法假设行为静止或仅关注平均性能,从而掩盖了安全关键场景下检测可靠性不足的问题
- 提出一种轻量级的信念追踪模块,旨在增强冻结的视觉-语言-动作(VLA)控制骨干网络,实现可靠的转换检测与安全适应
Card 01
研究单位
研究单位
- 论文作者包括 Devashri Naik、Divake Kumar、Nastaran Darabi 和 Amit Ranjan Trivedi
- 注:原文 HTML 片段中未明确列出具体的所属机构名称
Card 02
论文概述
论文概述
- 研究机器人在共享工作空间中与其他智能体协作时,如何检测协作方在任务执行过程中发生的行为策略转换
- 解决现有方法假设行为静止或仅关注平均性能,从而掩盖了安全关键场景下检测可靠性不足的问题
- 提出一种轻量级的信念追踪模块,旨在增强冻结的视觉-语言-动作(VLA)控制骨干网络,实现可靠的转换检测与安全适应
Card 03
核心贡献
核心贡献
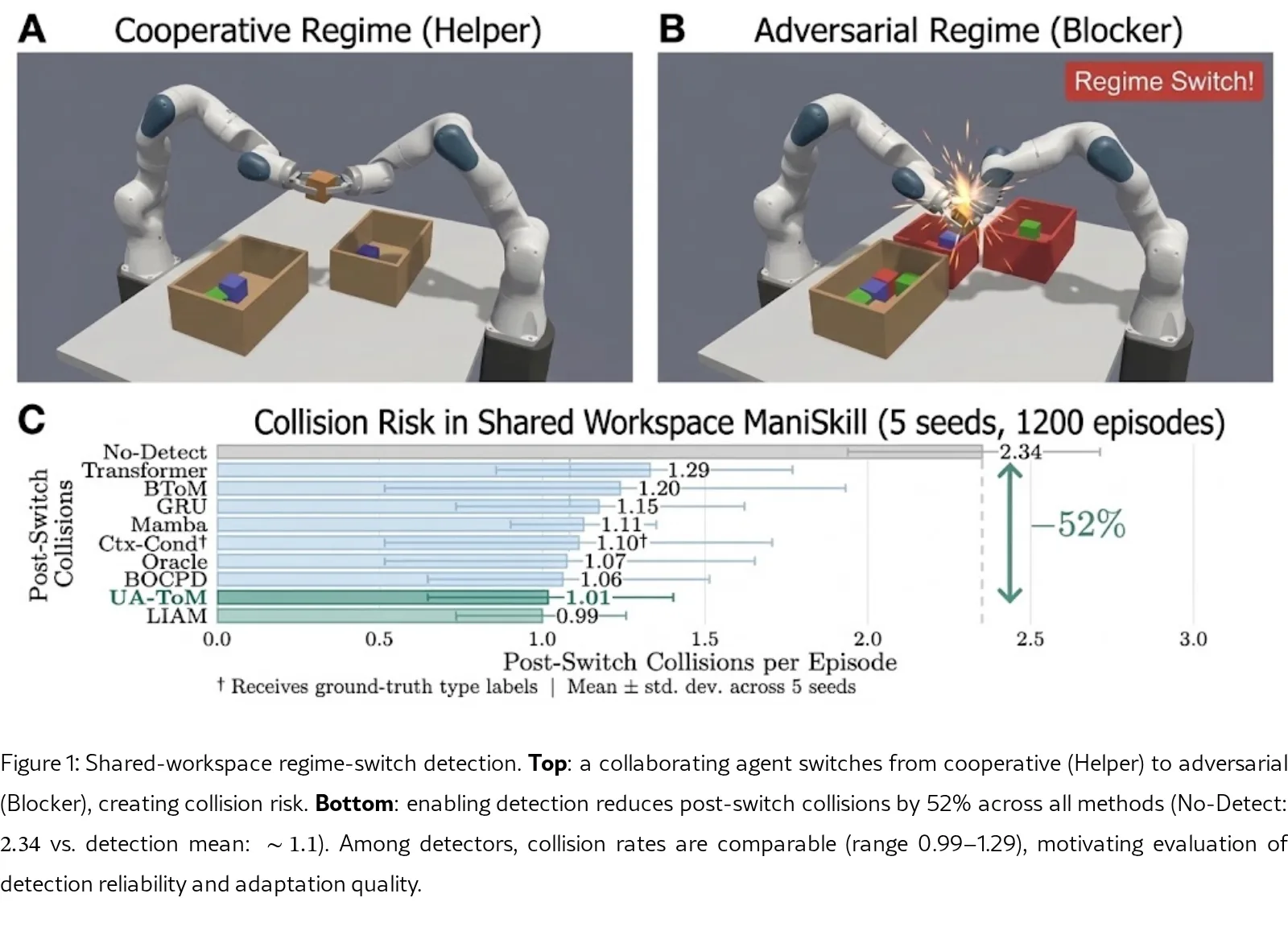
- 证实启用转换检测可将碰撞率降低 52%,并揭示在操作容忍度(±3步)下方法间存在超过50个百分点的可靠性分层,这在常规±5容忍度下不可见
- 提出 UA-ToM 模块(992K参数),在不修改基策略的情况下,实现了无辅助方法中最高的检测率(85.7%)和最低的危险区域停留时间(4.8步)
- 通过机制分析发现,鲁棒性源于选择性状态空间动态:隐状态更新幅度在转换时激增 17×,且离散化步长收敛至常数(≈0.78)
- 跨领域实验表明架构贡献具有领域依赖性:预测误差信号主导连续操作任务,因果注意力主导离散协调任务
Card 04
方法描述
方法描述
- UA-ToM 架构设计为增强冻结的 VLA 骨干网络,包含四个核心通路:选择性状态空间模型(SSM)、因果注意力、预测误差信号和对比记忆原型
- 使用选择性 SSM 维持持久信念状态,通过学习到的动态矩阵控制更新灵敏度,离散化步长在训练中收敛为近常数(约0.78)
- 利用因果注意力机制将信念锚定到近期观测,防止部分可观测性导致的信念漂移
- 融合预测误差信号和原型记忆提供的类别线索,通过门控层输出类型估计、转换概率和动作预测
Card 05
数据集与资源
数据集与资源
- 主要评估环境为 ManiSkill,使用两个 7-DOF Franka Panda 机械臂进行共享空间抓取任务
- 包含四种协作智能体行为类型:Helper、Competitor、Blocker、Passive
- 跨领域评估环境为 Overcooked,包含 Reliable、Lazy、Saboteur、Erratic 四种智能体类型
- 训练使用 RTX 6000 Ada GPU,骨干网络参考了 7B 参数的 VLA 模型(如 OpenVLA)
Card 06
评估与结果
评估与结果
- 在 ±3 步(150ms)的操作容忍度下,方法分为三个层级:快速检测器(>82%)、智能体建模(58-62%)和慢速循环模型(<34%);在 ±5 步下所有方法均为100%
- UA-ToM 实现了无辅助方法中最高的检测率(85.7%)和最低的平均延迟(9.9步),危险区域停留时间(CRT)甚至优于 Oracle(4.8 vs 5.3步)
- 内部动态分析显示,隐状态更新幅度在策略转换点激增约 17 倍,动作预测误差增加 2.3 倍,触发了平滑的信念修正过程
- 在 Overcooked 跨域评估中,UA-ToM 在所有布局和协议变体中均保持了最高的检测下限和最低的变异系数