一眼看懂
封面预览
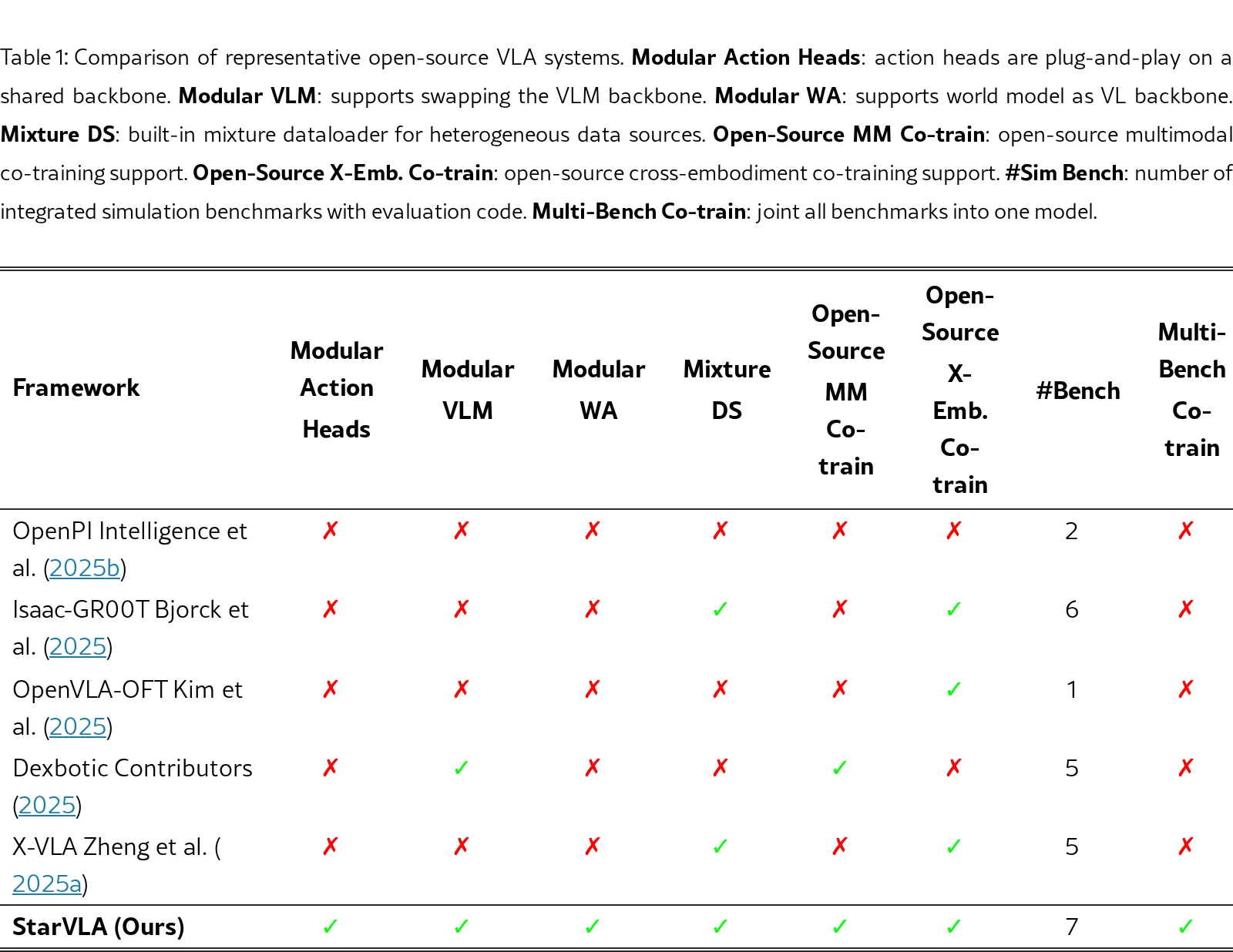
论文提出了StarVLA,一个用于视觉-语言-动作(VLA)模型开发的模块化开源代码库
- 论文提出了StarVLA,一个用于视觉-语言-动作(VLA)模型开发的模块化开源代码库
- 旨在解决现有VLA研究在架构、代码库和评估协议方面存在的碎片化问题
- 目标是提供一个统一的研究平台,支持系统性比较和快速原型开发
Card 01
研究单位
研究单位
- StarVLA社区
- Von Neumann Institute, HKUST
Card 02
论文概述
论文概述
- 论文提出了StarVLA,一个用于视觉-语言-动作(VLA)模型开发的模块化开源代码库
- 旨在解决现有VLA研究在架构、代码库和评估协议方面存在的碎片化问题
- 目标是提供一个统一的研究平台,支持系统性比较和快速原型开发
Card 03
核心贡献
核心贡献
- 提供了模块化的骨干-动作头架构,支持VLM骨干和世界模型骨干的自由组合
- 实现了四种代表性VLA范式:StarVLA-FAST、StarVLA-OFT、StarVLA-π和StarVLA-GR00T
- 提供了可复用的训练策略,包括多目标协同训练和跨具身协同训练
- 集成了五个主流基准:LIBERO、SimplerEnv、RoboTwin 2.0、RoboCasa-GR1和BEHAVIOR-1K
- 在多个基准上实现了接近或超越现有方法的性能,提供了易于复现的基线
Card 04
方法描述
方法描述
- 采用骨干-动作头分解设计,将VLA系统解耦为视觉-语言骨干和可插拔的动作头
- 定义了统一的I/O接口,使训练输入与部署时的原始观测保持一致
- 支持四种动作解码范式:自回归离散化、并行回归、流匹配去噪和双系统推理
- 提供了统一的服务器-客户端评估接口,支持仿真和真实机器人部署
Card 05
数据集与资源
数据集与资源
- 使用了多个标准基准数据集,包括LIBERO、SimplerEnv、RoboTwin 2.0等
- 支持Qwen3-VL-4B和Cosmos-Predict2-2B等多种视觉-语言骨干模型
- 训练使用A100 GPU,分布式训练配置为8或16卡
Card 06
评估与结果
评估与结果
- 在LIBERO基准上,使用Qwen3-VL-4B骨干的StarVLA-OFT达到96.6%平均成功率
- 在SimplerEnv WidowX基准上,StarVLA达到65.3%的平均成功率,超越多个基线方法
- 实验表明不同骨干模型(VLM和世界模型)在相同训练配置下可获得相当的性能
- 提供了单基准和多基准协同训练的完整示例和可复现脚本