一眼看懂
封面预览
研究了视觉语言动作(VLA)模型中动作表示的选择如何影响视觉编码器升级的效果
- 研究了视觉语言动作(VLA)模型中动作表示的选择如何影响视觉编码器升级的效果
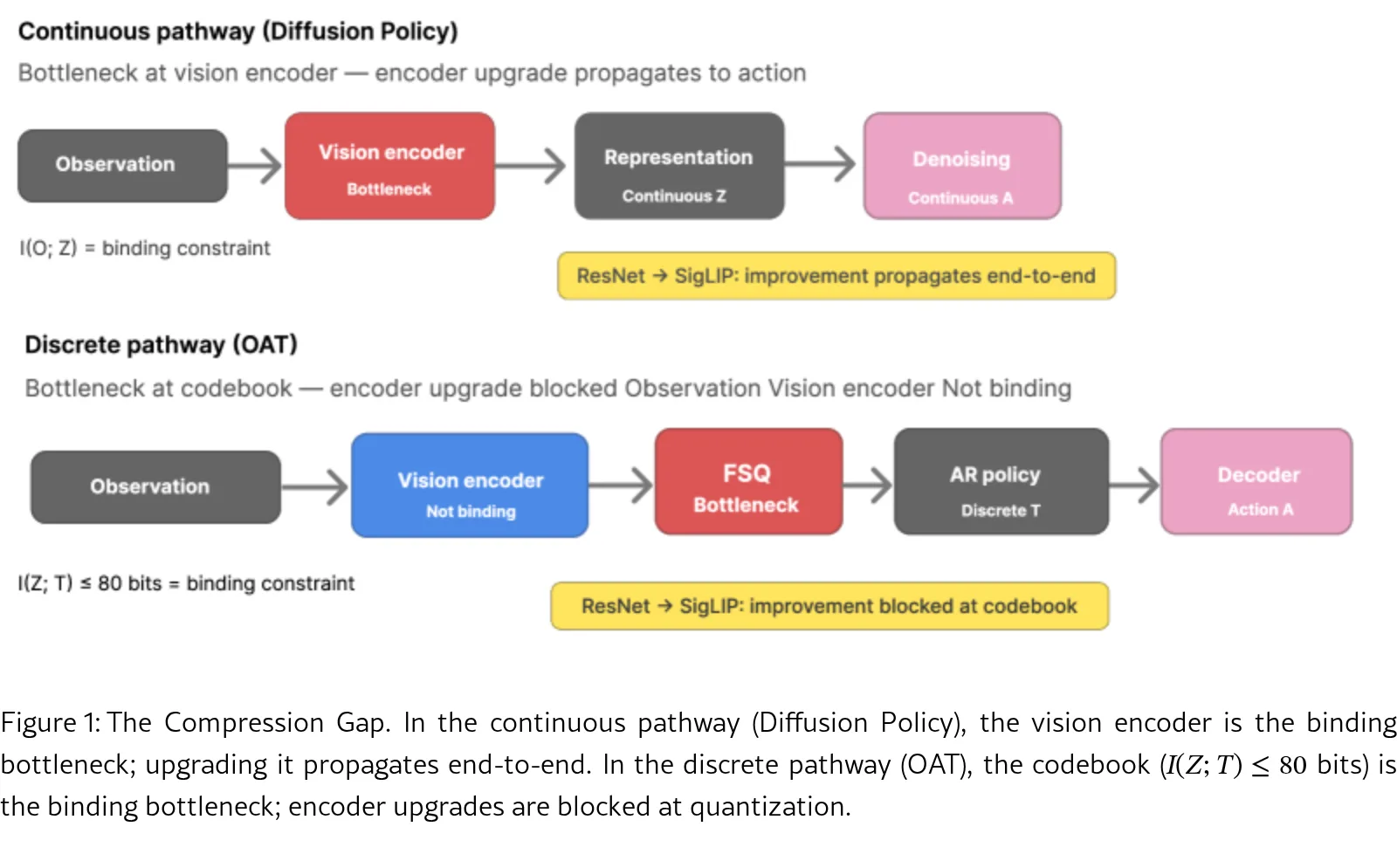
- 发现压缩间隙(Compression Gap)现象:连续动作表示(如Diffusion Policy)可以充分利用编码器升级,而离散动作表示(…
- 通过信息理论框架(数据处理不等式)解释了这一现象:离散tokenization引入了固定容量的码本瓶颈,阻止了上游编码器信息的传递
Card 01
研究单位
研究单位
- Takuya Shiba - Shibattic Inc.
Card 02
论文概述
论文概述
- 研究了视觉语言动作(VLA)模型中动作表示的选择如何影响视觉编码器升级的效果
- 发现压缩间隙(Compression Gap)现象:连续动作表示(如Diffusion Policy)可以充分利用编码器升级,而离散动作表示(如OAT)则无法受益
- 通过信息理论框架(数据处理不等式)解释了这一现象:离散tokenization引入了固定容量的码本瓶颈,阻止了上游编码器信息的传递
Card 03
核心贡献
核心贡献
- 提出压缩间隙(Compression Gap)概念:描述了离散tokenization导致VLA模型缩放行为发散的现象
- 建立信息理论基础:使用数据处理不等式证明离散码本成为信息瓶颈,阻止编码器改进传播到任务性能
- 因子实验验证:在LIBERO基准上证明Diffusion Policy从ResNet-18升级到SigLIP提升21.2%(M尺寸)和26.0%(L尺寸),而OAT仅提升3.6%和10.4%
- 编码器质量梯度实验:验证Diffusion Policy性能随编码器质量单调增长,OAT保持在狭窄范围内
- 码本大小实验:提供因果证据表明增加码本容量可部分恢复OAT对编码器质量的敏感性
Card 04
方法描述
方法描述
- 对比两种动作表示:OAT(离散有序动作tokenization,使用FSQ量化,码本大小1000)和Diffusion Policy(连续去噪过程)
- 视觉编码器:ResNet-18(64维)和SigLIP(1152维)作为主要对比,以及DINOv2 ViT-L/14和SigLIP 2用于梯度实验
- 模型规模:M尺寸(4层transformer,嵌入维度256)和L尺寸(6层,嵌入维度384)
- 信息瓶颈分析:建立O→Z→A(连续路径)和O→Z→Q→T→A(离散路径)的信息流框架
Card 05
数据集与资源
数据集与资源
- 基准数据集:LIBERO-10(10个任务,每个任务50条演示)
- 机器人平台:Franka Emika Panda
- 动作空间:7维(3D位置+3D姿态+1D夹爪)
- 动作分块:H_a=32,执行前16步后重新推理
- 训练配置:300个epochs,AdamW优化器,学习率5e-5(策略)和1e-5(编码器)
- 硬件:单张NVIDIA A100 GPU
Card 06
评估与结果
评估与结果
- 评估指标:峰值成功率(peak success rate),每次评估500条rollout
- 关键发现:
- Diffusion Policy + SigLIP (L)达到70.0%成功率,比ResNet-18提升26.0个百分点
- OAT + SigLIP (L)为58.4%,仅比ResNet-18提升10.4个百分点
- 编码器质量梯度:DP从36.4%(ResNet)→63.8%(DINOv2),OAT在44.2%-57.4%之间波动无明显趋势
- 码本实验:\|V\|=1920时,ResNet下降到42.6%,接近DP的ResNet性能(36.4%),显示瓶颈缓解后编码器质量开始显现
- 结论:连续路径使编码器改进能够端到端传播,而离散路径的固定容量码本限制了信息流