一眼看懂
封面预览
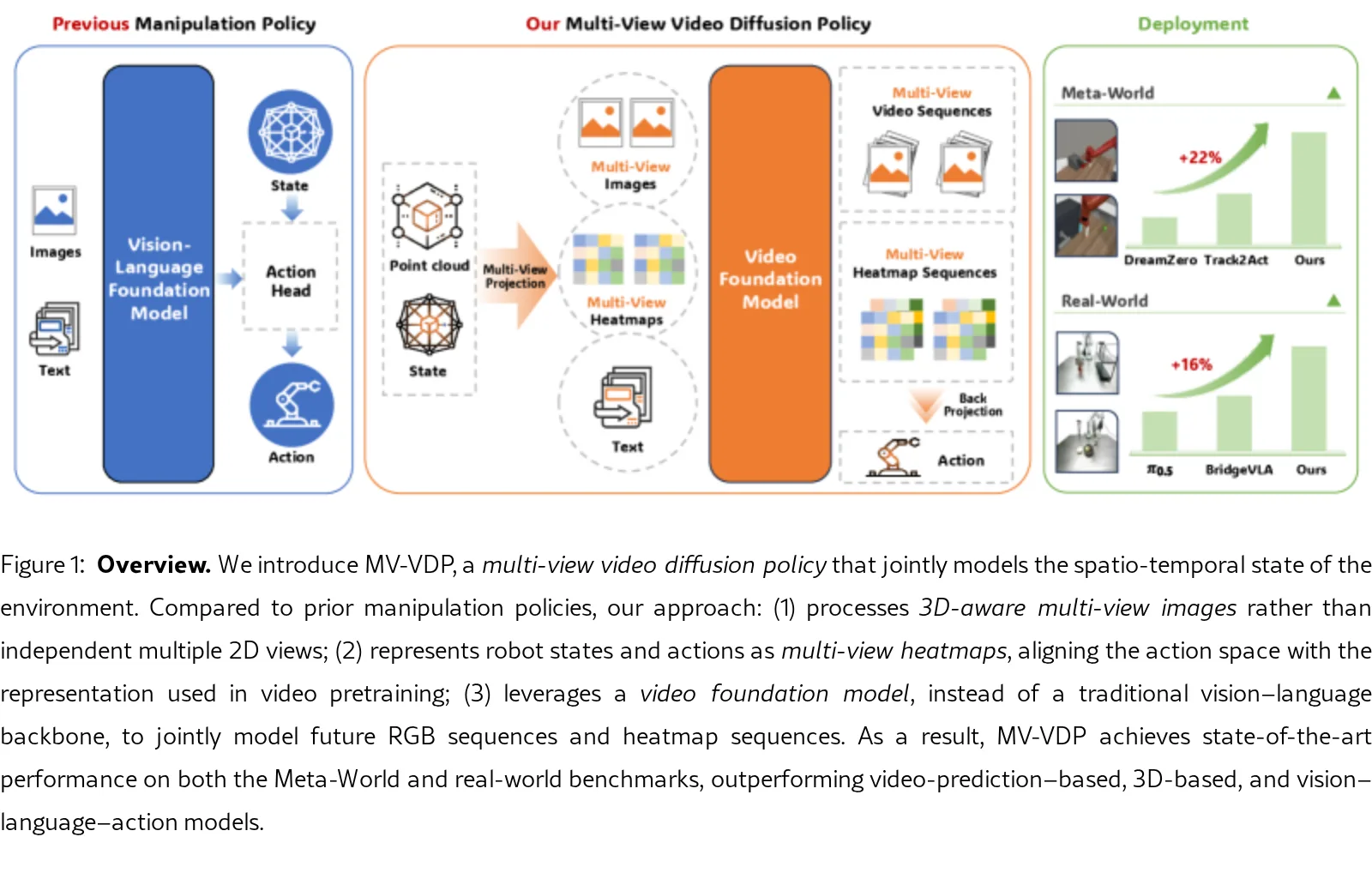
提出了 MV-VDP (多视图视频扩散策略),一种具备 3D 时空感知 的视频动作模型,用于机器人操作任务。
- 提出了 MV-VDP (多视图视频扩散策略),一种具备 3D 时空感知 的视频动作模型,用于机器人操作任务。
- 旨在解决现有视觉-语言-动作 (VLA) 模型依赖 2D 观测和静态图像预训练导致的 数据需求高 和 环境动态理解不足 的问题。
- 通过联合预测多视图热图视频和 RGB 视频,实现了视频预训练与动作微调的表示对齐,显著提升了操作的 数据效率、鲁棒性、泛化能力和可解释性。
Card 01
研究单位
研究单位
- 中国科学院自动化研究所 模式识别国家重点实验室 (NLPR)
- 中国科学院大学 人工智能学院
- 清华大学
- 西安交通大学
- 武汉大学
- 南京大学
- FiveAges 公司
Card 02
论文概述
论文概述
- 提出了 MV-VDP (多视图视频扩散策略),一种具备 3D 时空感知 的视频动作模型,用于机器人操作任务。
- 旨在解决现有视觉-语言-动作 (VLA) 模型依赖 2D 观测和静态图像预训练导致的 数据需求高 和 环境动态理解不足 的问题。
- 通过联合预测多视图热图视频和 RGB 视频,实现了视频预训练与动作微调的表示对齐,显著提升了操作的 数据效率、鲁棒性、泛化能力和可解释性。
Card 03
核心贡献
核心贡献
- 首次提出利用视频基础模型构建 3D Video-Action-Model (3D VAM),实现了空间结构与时序动态的联合建模。
- 设计了将动作表示为多视图热图的方法,成功将视频生成模型的表示空间与机器人动作空间对齐。
- 在极少演示数据(仅 10 条轨迹)下实现了高成功率,无需额外的机器人预训练数据。
- 模型在推理过程中表现出极强的鲁棒性,扩散步数降至 1 步时仍能保持高性能,且能泛化到未见过的场景。
Card 04
方法描述
方法描述
- 多视图投影: 将彩色点云投影为多视图 RGB 图像,并将末端执行器姿态转换为多视图高斯热图,以此隐式编码 3D 结构。
- 多视图视频扩散: 基于 Wan2.2 视频基础模型 (5B 参数),引入视图注意力模块 扩展为多视图架构,联合预测未来 RGB 和热图序列。
- 动作解码: 将预测的热图峰值反投影回 3D 空间获取位置,通过轻量级 Transformer 从去噪潜变量中预测旋转和夹爪状态。
- 训练采用 LoRA 微调策略,以减少计算开销。
Card 05
数据集与资源
数据集与资源
- Meta-World 仿真基准测试(7 个任务,每任务 5 条演示)。
- 真实世界机器人平台:Franka Research 3 机械臂和 ZED 2i 深度相机(包括 Put Lion, Push-T, Scoop Tortilla 等任务,每任务 10 条演示)。
- 模型参数:视频扩散 Transformer 为 5B 参数,旋转与夹爪预测器为 170M 参数。
- 训练推理资源:在 NVIDIA A100 GPU 服务器上进行实验,推荐推理步数为 5 步以实现 5Hz 控制频率。
Card 06
评估与结果
评估与结果
- 仿真评估:在 Meta-World 基准上平均成功率达到 89.1%,显著优于 DreamZero (61.1%) 和 Track2Act (67.4%) 等基线。
- 真实世界评估:在极低数据条件下,真实机器人任务平均成功率为 57.1%,优于最强基线 BridgeVLA (41.4%) 和 DP3 (0%)。
- 鲁棒性分析:模型对扩散步数极具鲁棒性,仅需 1 步去噪 即可达到与 50 步相当的成功率。
- 泛化能力:在未见过的背景、光照、物体高度和物体类别等干扰场景下表现出色,特别是在 Push-L 和 Scoop-C 任务上取得最佳成绩。