一眼看懂
封面预览
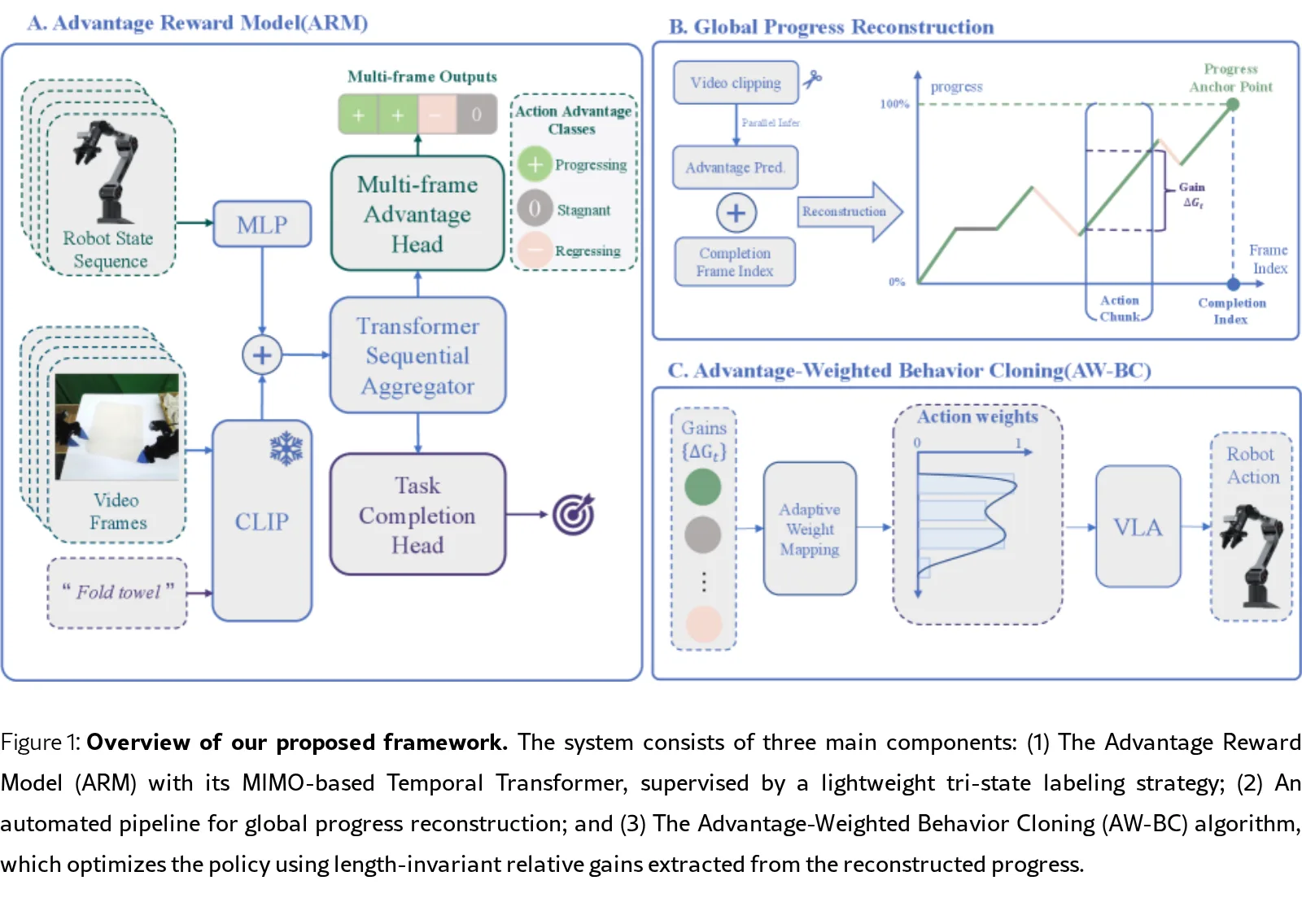
论文针对长视野机器人操作任务中的“奖励工程瓶颈”,提出了 优势奖励建模 (ARM) 框架
- 论文针对长视野机器人操作任务中的“奖励工程瓶颈”,提出了 优势奖励建模 (ARM) 框架
- 核心思想是从难以量化的绝对进度建模转向估计状态间的相对优势,以提供更稳定、直观的中间监督信号
- 通过引入低成本的三态标注策略,解决了现有密集奖励标注成本高、难以处理非单调行为(如回溯、恢复)的问题
Card 01
研究单位
研究单位
- LimX Dynamics
- 北京邮电大学
- 浙江大学
Card 02
论文概述
论文概述
- 论文针对长视野机器人操作任务中的“奖励工程瓶颈”,提出了 优势奖励建模 (ARM) 框架
- 核心思想是从难以量化的绝对进度建模转向估计状态间的相对优势,以提供更稳定、直观的中间监督信号
- 通过引入低成本的三态标注策略,解决了现有密集奖励标注成本高、难以处理非单调行为(如回溯、恢复)的问题
Card 03
核心贡献
核心贡献
- 提出任务无关、低认知负载的 三态标注策略,将状态转移分为 *进步*、*退步*、*停滞* 三类
- 开发基于 MIMO Transformer 的 优势奖励模型 (ARM),融合视觉序列与本体感知状态以估计轨迹片段的相对进度增益
- 提出 优势加权行为克隆 (AW-BC) 算法,利用重建的密集进度信号对样本进行自适应重加权,有效过滤次优样本
Card 04
方法描述
方法描述
- ARM 模型 采用 MIMO 架构,在因果窗口内并行处理历史观测序列,通过 CLIP 视觉特征、本体状态和任务指令的多模态融合进行序列建模
- 使用双头学习目标:多头优势分类头监督三态标签,任务完成头使用 Focal Loss 解决类不平衡问题
- 三态标注策略 简化了标注流程,仅需判断状态转移是进步、退步或停滞,降低了人工标注成本并提高一致性
- 全局进度重建 将离散的三态预测与任务完成锚点结合,积分生成全局一致的密集进度曲线
- AW-BC 采用长度自适应增益公式,通过统计加权机制将原始增益转换为训练权重,最小化加权负对数似然损失
Card 05
数据集与资源
数据集与资源
- 数据集:包含 972 个毛巾折叠轨迹片段(总计 20 小时),其中 809 个专家演示,163 个 DAgger 增强片段
- 硬件:使用 AgileX ALOHA 双手遥操作系统进行数据收集
- 训练资源:推理测试使用 NVIDIA A100 GPU
Card 06
评估与结果
评估与结果
- 评估基准:与 SARM 模型进行对比,并在下游任务中与标准 BC 和 RA-BC 基线比较
- 主要评估指标:进度重建的均方误差 (MSE)、轨迹分类准确率、下游任务成功率、任务吞吐量、折叠精度
- 关键结果:
- ARM 的 MSE 显著低于 SARM (0.0014 vs 0.0059),且在成功和失败轨迹识别上达到 100% 准确率
- 在下游毛巾折叠任务中,AW-BC (GR00T + ARM) 达到 99.4% 的成功率,显著优于 BC 基线 (62.1%) 和 RA-BC (78.5%)
- 三态标注策略的人工标注效率比子任务分割提升 2.5 倍,自动化标注吞吐量超过 2,000 样本/8小时
- ARM 的 MIMO 架构推理速度达 14.1 it/s,比 VLM 标注快 13.7 倍