一眼看懂
封面预览
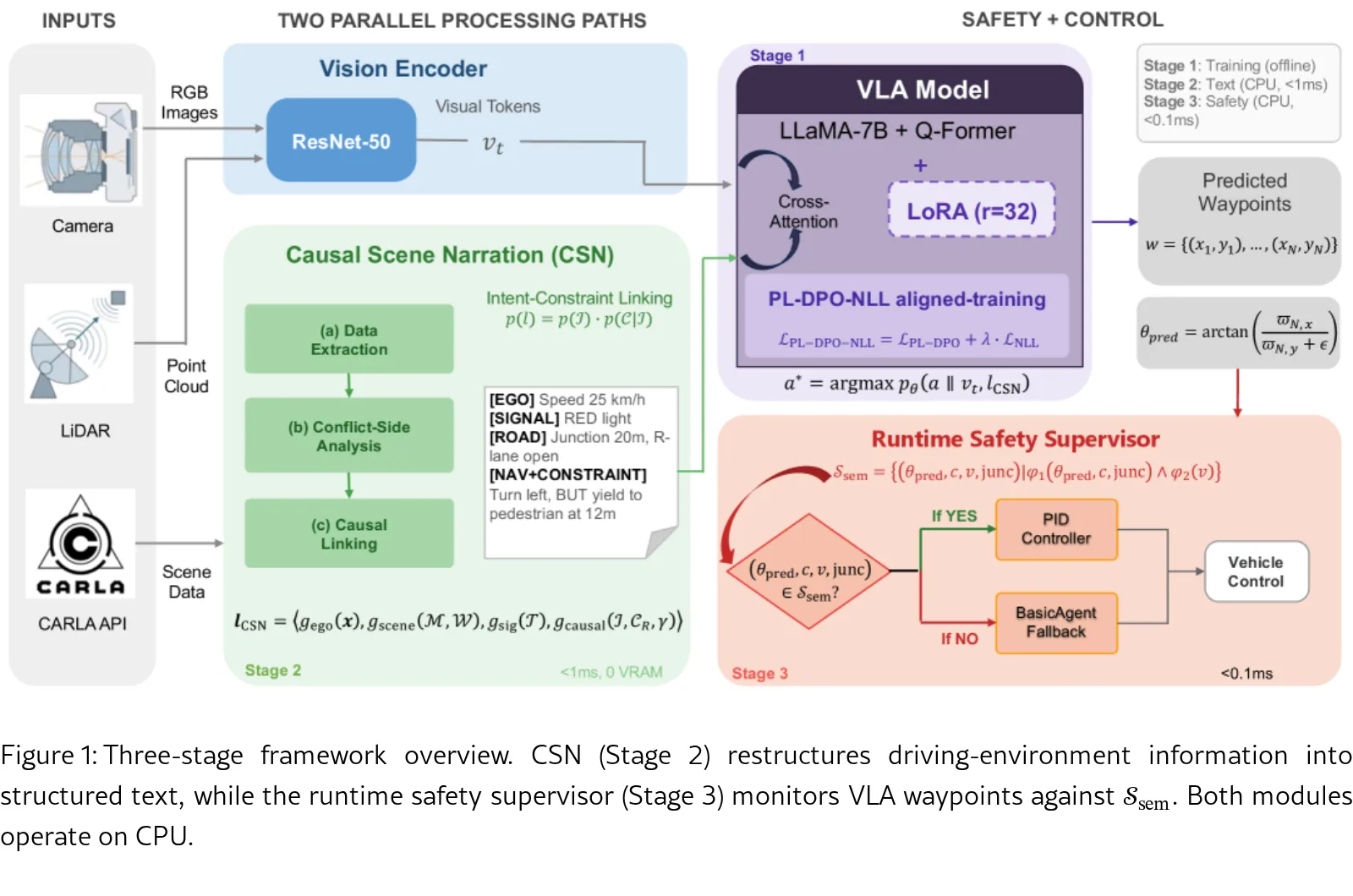
论文提出 Causal Scene Narration (CSN) 框架,通过意图-约束对齐、定量物理锚定和结构化信息分离来重构视觉语言动作…
- 论文提出 Causal Scene Narration (CSN) 框架,通过意图-约束对齐、定量物理锚定和结构化信息分离来重构视觉语言动作…
- 论文引入基于 Simplex 架构 的运行时安全监督机制,监控 VLA 输出并在检测到潜在不安全动作时进行干预,提供训练时对齐无法提供的安全保障
- 论文解决三个关键问题:现有 VLA 系统文本输入呈因果断裂碎片、缺乏运行时安全保证、偏好对齐模型存在分布偏移
Card 01
研究单位
研究单位
- 东京大学 信息科学与技术研究生院
- TIER IV, Inc.
Card 02
论文概述
论文概述
- 论文提出 Causal Scene Narration (CSN) 框架,通过意图-约束对齐、定量物理锚定和结构化信息分离来重构视觉语言动作 (VLA) 模型的文本输入,在推理时以零 GPU 成本运行
- 论文引入基于 Simplex 架构 的运行时安全监督机制,监控 VLA 输出并在检测到潜在不安全动作时进行干预,提供训练时对齐无法提供的安全保障
- 论文解决三个关键问题:现有 VLA 系统文本输入呈因果断裂碎片、缺乏运行时安全保证、偏好对齐模型存在分布偏移
Card 03
核心贡献
核心贡献
- 提出 CSN 框架,将现有方法按因果结构级别 (L0-L3) 分类,构建零 VRAM 文本增强管道
- 设计 运行时安全监督器,基于 Simplex 架构实现语义级安全包络监控和方向一致性检测
- 开发 PL-DPO-NLL 训练时安全对齐方法,结合 Plackett-Luce 多偏好排序与 NLL 正则化
- 进行十配置多城镇消融实验 (16 路线、8 城镇),证明 CSN 在不同权重配置下的鲁棒性
- 通过经验分解证明因果结构贡献了 39.1% 的性能提升,而非仅信息量增加
Card 04
方法描述
方法描述
- CSN 采用三原则:(1) 定量物理锚定 将模糊描述替换为精确度量值;(2) 结构化信息分离 按感知-预测-规划链组织;(3) 意图-约束因果对齐 使用显式因果连接词 (BUT, YIELD_BEFORE, BECAUSE) 链接意图与约束
- 运行时安全监督采用 Simplex 架构:高级控制器 为 VLA 模型,基线控制器 为 CARLA Traffic Manager,决策模块 监控语义安全包络并在违规时切换控制权
- 安全规范使用信号时序逻辑 (STL) 定义方向一致性 φ₁ 和停滞检测 φ₂,仅在不进入路口时评估方向一致性以避免误报
Card 05
数据集与资源
数据集与资源
- CARLA 0.9.10 模拟器,16 条路线覆盖 8 个城镇,包含夜间、雨天、浓雾和晴天场景
- Town01 用于收集偏好数据,共 51,124 个 Plackett-Luce 样本,涵盖转弯、正常驾驶、制动等场景
- 模型骨干为 LLaMA-7B,视觉编码器为 ResNet-50
- PL-DPO-NLL 训练使用 3× NVIDIA RTX 6000 Ada GPU,推理在 NVIDIA RTX 3090 Ti 上进行
- LoRA 配置:秩 r=32,alpha=32,应用于所有注意力和 MLP 投影层
Card 06
评估与结果
评估与结果
- 评估指标:Driving Score (DS) 为主要指标,Route Completion (RC) 和 Infraction Score (IS) 为辅助指标
- CSN 在原始 LMDrive 上提升 DS +31.1%,在偏好对齐变体上提升 +24.5%
- Flat Text (仅信息无因果结构) 提升 +18.9%,证明因果结构贡献 39.1% 的增益
- 语义安全监督 改善 Infraction Score,而反应式 TTC 监控导致性能下降 -32.3%
- PL-DPO-NLL 单独使用时因分布偏移未见改进,但与 CSN 结合后获得显著增益