一眼看懂
封面预览
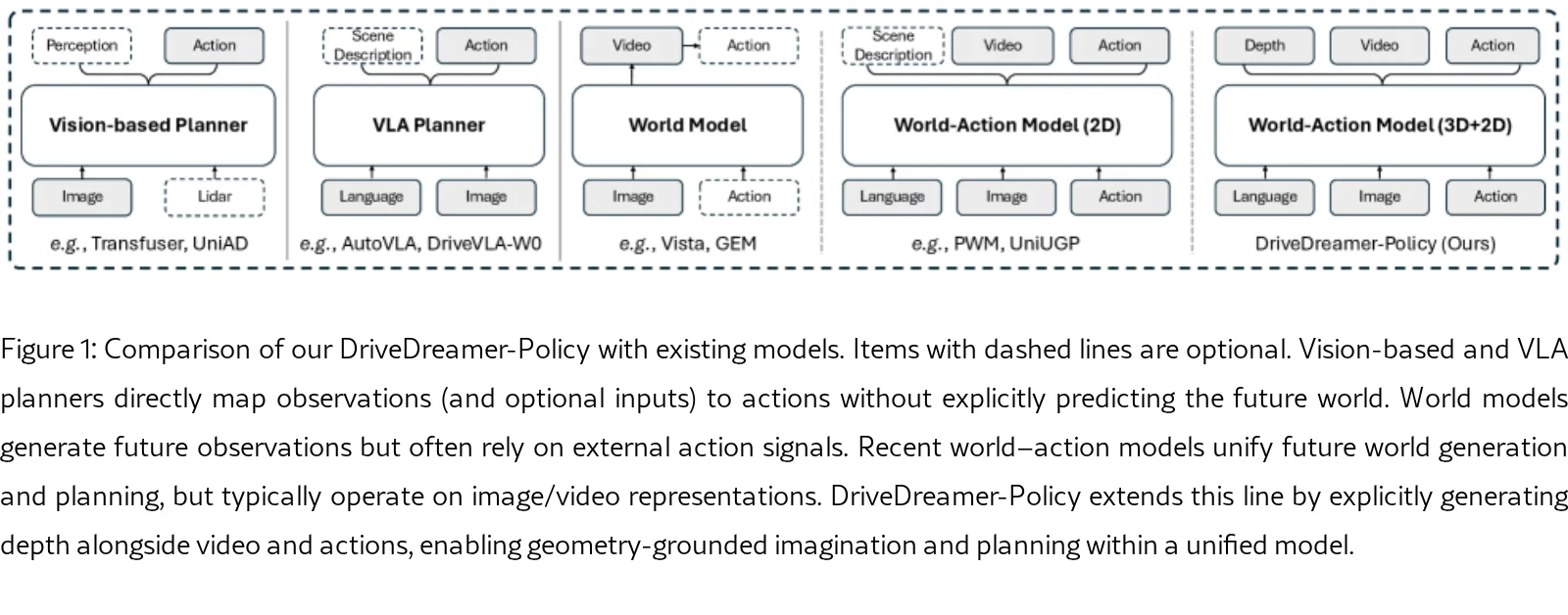
提出一个统一的驾驶世界-动作模型 DriveDreamer-Policy,整合深度生成、未来视频生成与运动规划
- 提出一个统一的驾驶世界-动作模型 DriveDreamer-Policy,整合深度生成、未来视频生成与运动规划
- 解决现有世界-动作模型缺乏几何基础的问题,通过显式深度学习为未来预测和规划提供结构化支持
- 实现在单一模块化架构中同时完成世界理解、生成与决策任务
Card 01
研究单位
研究单位
- GigaAI
- University of Toronto
- CUHK MMLab
Card 02
论文概述
论文概述
- 提出一个统一的驾驶世界-动作模型 DriveDreamer-Policy,整合深度生成、未来视频生成与运动规划
- 解决现有世界-动作模型缺乏几何基础的问题,通过显式深度学习为未来预测和规划提供结构化支持
- 实现在单一模块化架构中同时完成世界理解、生成与决策任务
Card 03
核心贡献
核心贡献
- 提出模块化的世界-动作架构,结合 LLM 与轻量级生成专家,实现可控的计算开销
- 引入显式 3D深度生成模块,并采用因果 3D→2D→1D 条件通路,使几何信息直接引导视频生成和规划
- 在 Navsim v1/v2 基准上达到 SOTA 性能,规划与世界生成质量均超越现有方法
Card 04
方法描述
方法描述
- 使用 大型语言模型(LLM) 处理语言指令、多视角图像和动作,输出世界与动作嵌入
- 设计三个轻量级生成专家:像素空间 深度生成器、潜空间 视频生成器 和 动作生成器
- 采用结构化因果注意力掩码,实现 深度→视频→动作 的单向信息流,确保几何理解引导后续生成与规划
- 使用 流匹配(Flow Matching) 目标训练生成专家,联合多任务损失优化所有组件
Card 05
数据集与资源
数据集与资源
- 训练与评估基于 Navsim v1 和 Navsim v2 基准,使用 navtrain 数据集(100k样本)
- 模型骨干基于 Qwen3-VL-2B,深度生成器从 PPD 初始化,视频生成器从 Wan-2.1-T2V-1.3B 适配
- 训练使用 8张 NVIDIA H20 GPU,单阶段训练100k步,批大小为32
- 深度标签由 Depth Anything 3 (DA3) 基础模型提供
Card 06
评估与结果
评估与结果
- 在 Navsim v1 上达到 89.2 PDMS,超越所有对比的世界模型方法
- 在 Navsim v2 上达到 88.7 EPDMS,比前方法提升 +2.6
- 视频生成质量显著提升,FVD 为 53.59(比前方法降低 32.36)
- 深度预测 AbsRel 为 8.1,优于微调后的 PPD(9.3)
- 消融实验显示:深度与视频联合学习提供互补益处,提升规划鲁棒性