一眼看懂
封面预览
提出了一个名为 ThermoAct 的视觉-语言-行动框架,创新性地将热成像信息集成到机器人任务执行中。
- 提出了一个名为 ThermoAct 的视觉-语言-行动框架,创新性地将热成像信息集成到机器人任务执行中。
- 旨在解决现有VLA模型无法感知和处理温度信息的问题,使机器人能够执行基于温度的决策(如选择“最冷的”物体)并识别热安全隐患。
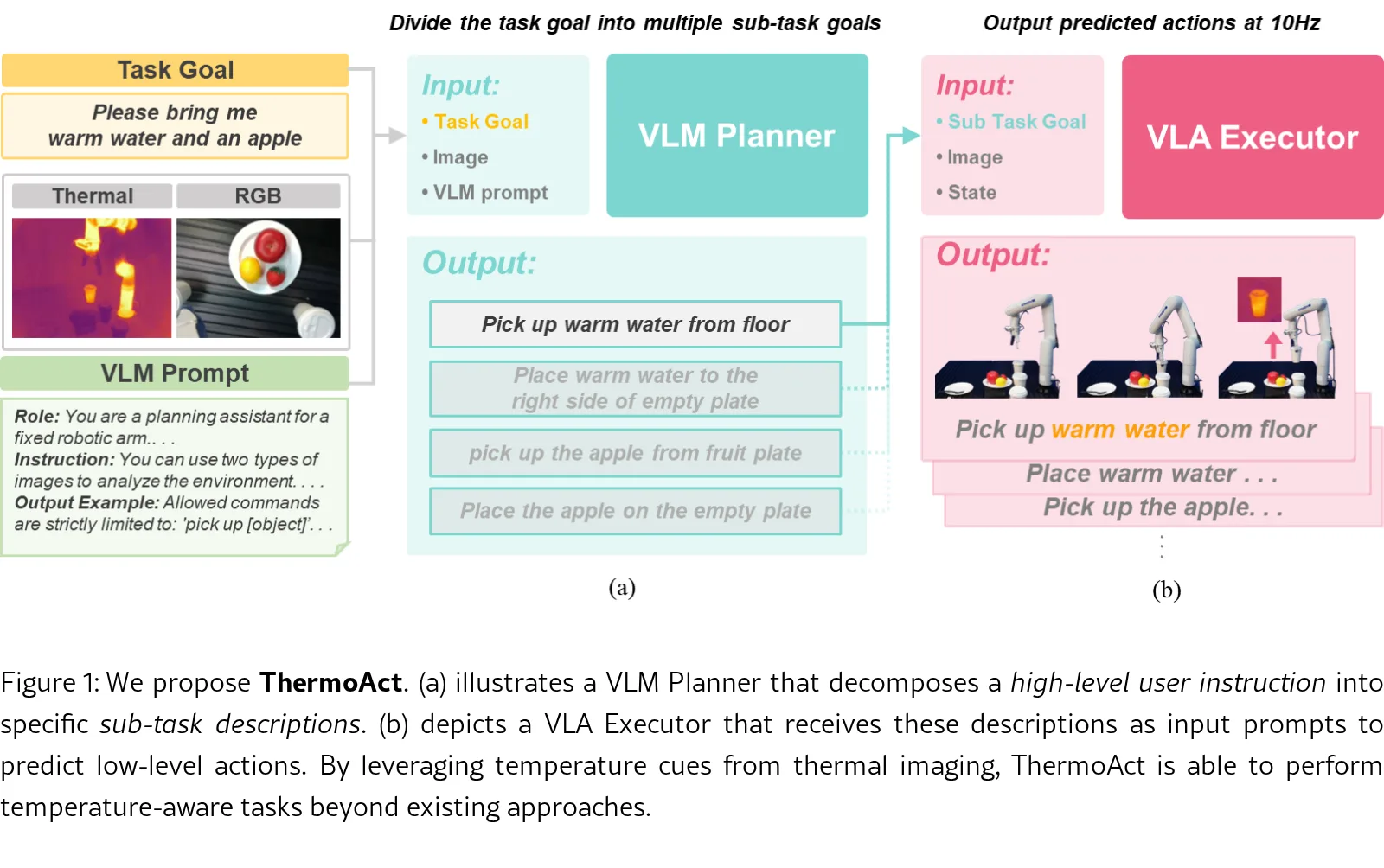
- 采用层次化架构,使用视觉-语言模型作为高级规划器分解复杂任务,再由VLA执行器完成底层动作,以应对热成像数据稀缺的挑战。
Card 01
研究单位
研究单位
- Young-Chae Son, Dae-Kwan Ko, Yoon-Ji Choi, Soo-Chul Lim(韩国研究团队)
Card 02
论文概述
论文概述
- 提出了一个名为 ThermoAct 的视觉-语言-行动框架,创新性地将热成像信息集成到机器人任务执行中。
- 旨在解决现有VLA模型无法感知和处理温度信息的问题,使机器人能够执行基于温度的决策(如选择“最冷的”物体)并识别热安全隐患。
- 采用层次化架构,使用视觉-语言模型作为高级规划器分解复杂任务,再由VLA执行器完成底层动作,以应对热成像数据稀缺的挑战。
Card 03
核心贡献
核心贡献
- 提出了首个将热成像模态集成到VLA框架中的方法,扩展了机器人的环境感知能力。
- 设计了VLM(高级规划器)与VLA(低级执行器)协作的层次化架构,有效解决了复杂、长视野任务的执行问题。
- 构建了包含日常操作与安全场景的热相关任务数据集,并进行了全面的实验验证。
- 实验证明,结合热信息可以显著提升任务成功率和机器人操作安全性。
Card 04
方法描述
方法描述
- 整体采用层次化架构:VLM Planner负责理解指令和热图像,将复杂任务分解为子任务;VLA Executor基于子任务描述和实时图像执行动作。
- VLA Executor 基于 π0模型 进行微调,输入为手腕RGB图像、外部热成像图像、机器人状态向量及自然语言子任务提示。
- 热成像数据处理:将原始热数据(256×192)归一化到室内温度范围(20-35°C),并映射到INFERNO伪彩色图,转换为可供模型学习的RGB格式图像。
- VLM Planner 使用 Gemini 2.0 Flash,输入RGB-Thermal图像和结构化提示词,输出环境分析和分解后的子任务计划。
Card 05
数据集与资源
数据集与资源
- 使用自建数据集,每个任务收集50个演示片段进行LoRA微调。
- 数据集包含四部分:状态(7维)、动作(8维)、图像(RGB与热成像同步于15Hz)、任务提示。
- 实验平台为 7-DoF Kinova Gen3 Lite机械臂,配备两个RGB-D相机和一个热成像相机。
- 训练与评估在20-35°C的室内环境中进行。
Card 06
评估与结果
评估与结果
- 在5个真实世界任务上评估:包括日常操作(如递送温水、冷可乐)和安全场景(如拾取过热电池、关闭加热直发器)。
- 主要评估指标为任务成功率。
- 关键结果:
- 与纯RGB输入的基线模型(RGB-RGB)相比,提出的RGB-T模型在热相关子任务上平均成功率从42%提升至82%。
- 在50个训练片段下,RGB-T模型在多项任务上取得更高成功率,例如“关闭加热直发器”子任务成功率达90%(RGB-RGB为30%)。
- 层次化方法在复杂任务上表现远优于端到端学习的Flat VLA模型(后者成功率接近0%),证明了任务分解策略的有效性。