一眼看懂
封面预览
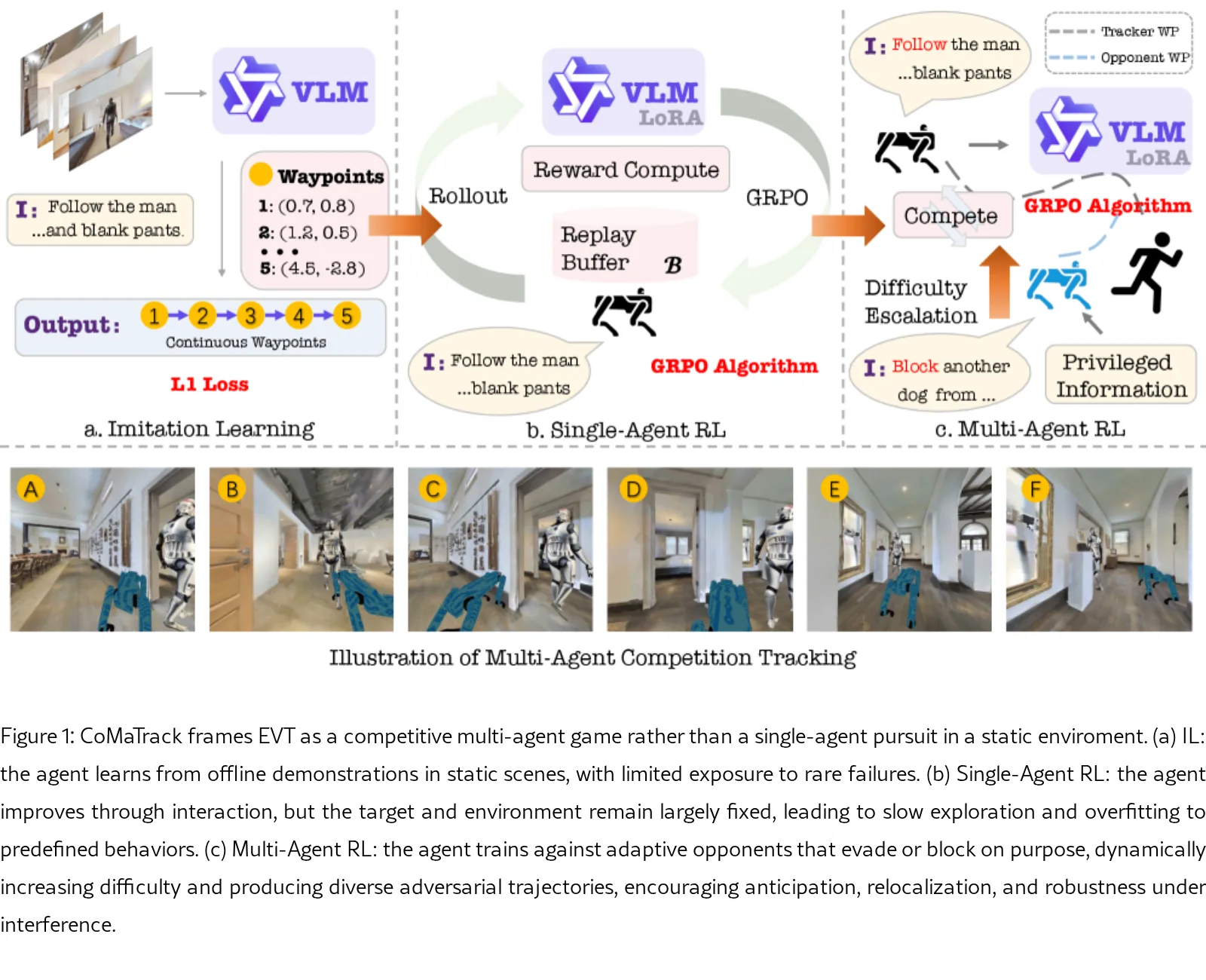
论文提出了 CoMaTrack,一个用于具身视觉跟踪(EVT)的竞争性多智能体博弈论强化学习框架,旨在解决现有单一智能体模仿学习方法依赖昂贵专…
- 论文提出了 CoMaTrack,一个用于具身视觉跟踪(EVT)的竞争性多智能体博弈论强化学习框架,旨在解决现有单一智能体模仿学习方法依赖昂贵专…
- 研究的核心是将EVT任务从静态环境下的单智能体追逐,重新定义为一个动态对抗的多智能体博弈过程,通过对手策略动态提升任务难度,训练出更强健、具有…
- 论文同时发布了 CoMaTrack-Bench,这是首个用于竞争性EVT的开源基准,包含跟踪智能体与自适应对手的动态对抗场景,用于标准化的鲁棒…
Card 01
研究单位
研究单位
- 作者所属机构为 Amap, Alibaba Group。
Card 02
论文概述
论文概述
- 论文提出了 CoMaTrack,一个用于具身视觉跟踪(EVT)的竞争性多智能体博弈论强化学习框架,旨在解决现有单一智能体模仿学习方法依赖昂贵专家数据、泛化能力有限的问题。
- 研究的核心是将EVT任务从静态环境下的单智能体追逐,重新定义为一个动态对抗的多智能体博弈过程,通过对手策略动态提升任务难度,训练出更强健、具有抗干扰能力的跟踪策略。
- 论文同时发布了 CoMaTrack-Bench,这是首个用于竞争性EVT的开源基准,包含跟踪智能体与自适应对手的动态对抗场景,用于标准化的鲁棒性评估。
Card 03
核心贡献
核心贡献
- 首次将多智能体竞争博弈论与强化学习融合到EVT任务中,设计了一个智能体-对手-环境共同进化的训练循环,使紧凑的 3B参数模型 性能超越了此前基于 7B模型 的单智能体方法。
- 开源了 CoMaTrack-Bench,首个多智能体对抗性EVT基准,包含静态障碍、随机干扰和竞争性跟踪三种渐进式对手行为,填补了现有基准缺乏主动对抗场景的空白。
- 提出的竞争博弈训练范式具有良好的可扩展性,可以自然地扩展到其他视觉-语言-动作具身任务,以解决分布外泛化问题。
Card 04
方法描述
方法描述
- CoMaTrack 是一个端到端的视觉-语言-动作模型,基于视频视觉语言模型骨干 Qwen2.5VL-3B 构建,并集成流匹配动作模块来预测未来轨迹。
- 训练流程分为两阶段:首先在多任务导航、跟踪和VQA数据上进行监督微调;然后使用 GRPO 算法进行多智能体竞争性强化学习训练。
- 创新性地设计了不对称奖励函数:跟踪智能体奖励维持标准跟踪目标并增加对手感知安全项;对手智能体奖励鼓励其更激进地接近目标以制造对抗,从而形成自我强化的“军备竞赛”。
Card 05
数据集与资源
数据集与资源
- 使用的数据集包括:用于跟踪任务的 EVT-Bench(包含STT、DT、AT任务)、用于场景的 HM3D 和 MP3D、用于视觉问答的 ScanQA 和 LLaVA-Pretrain、用于语言理解的 RefCOCO 和 Flickr30k,以及用于多任务导航的 R2R-CE、RxR-CE、HM3D ObjectNav 和 HM3D OVON。
- 模型基础为 Qwen2.5VL-3B,参数量为 3B。
- 监督微调阶段使用 48块 NVIDIA H20 GPU,多智能体强化学习阶段使用 4块 NVIDIA L20 GPU。
Card 06
评估与结果
评估与结果
- 评估环境为 EVT-Bench 和本文新提出的 CoMaTrack-Bench。
- 主要评估指标为成功率、跟踪率和碰撞率。
- 关键实验结果显示:
- 在 EVT-Bench 上,CoMaTrack(3B)在STT、DT、AT任务上均达到最优,其中STT成功率为 92.1%,DT为 74.2%,AT为 57.5%,全面超越了此前基于7B模型的最强基线 TrackVLA++。
- 在更具挑战性的 CoMaTrack-Bench 上,CoMaTrack 实现了 85.0% 的成功率和 82.9% 的跟踪率,大幅领先基线方法。
- 消融实验表明,多智能体竞争训练相比单智能体强化学习,能显著降低碰撞率(从 2.2% 降至 0.9%),证明了其在学习安全、鲁棒策略方面的有效性。