一眼看懂
封面预览
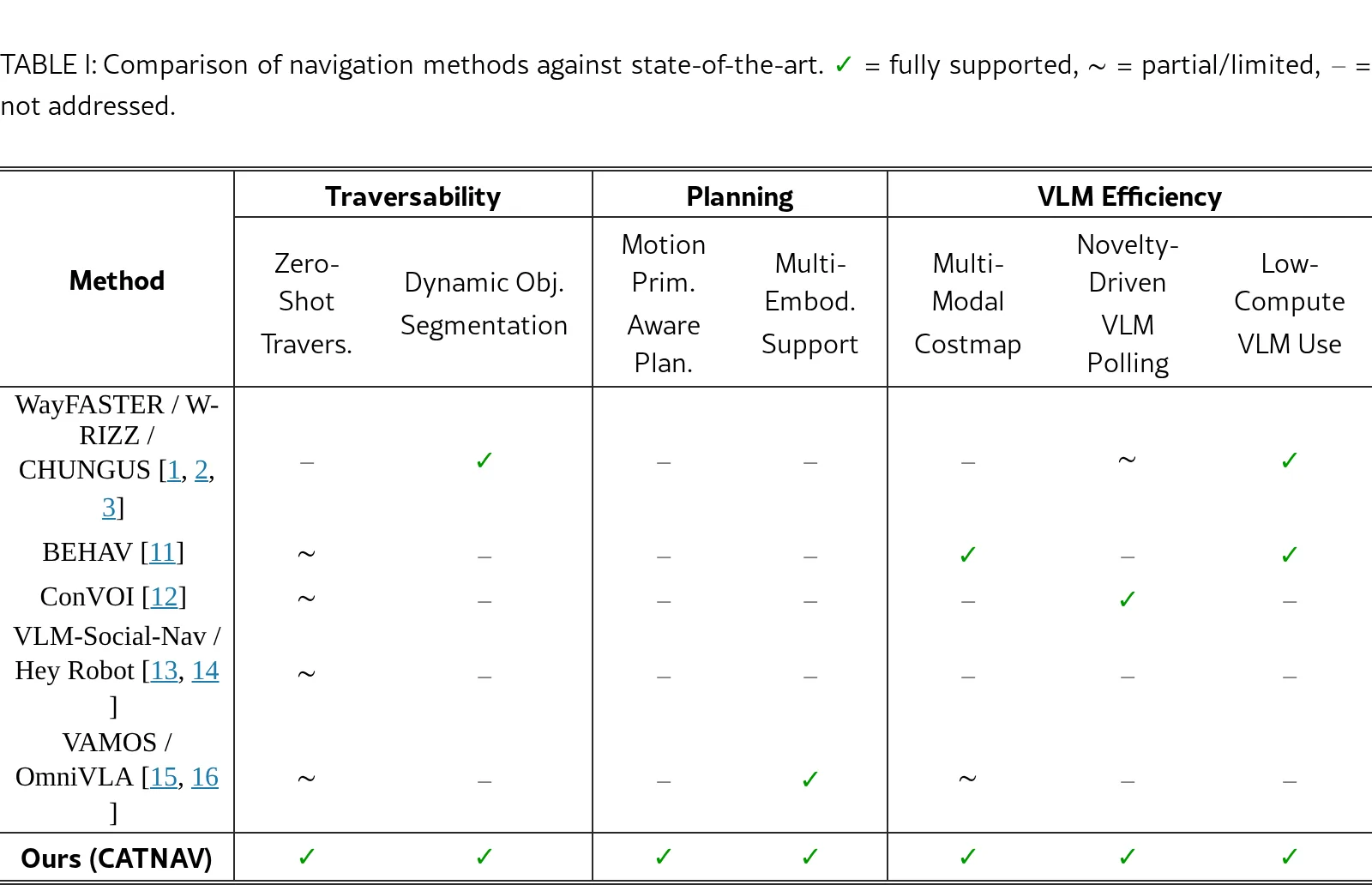
论文提出了 CATNAV,这是一个基于缓存视觉-语言的可通行性导航框架,旨在解决机器人在非结构化环境中的零样本导航问题。
- 论文提出了 CATNAV,这是一个基于缓存视觉-语言的可通行性导航框架,旨在解决机器人在非结构化环境中的零样本导航问题。
- 该框架利用多模态大语言模型(VLM)进行语义后果推理,无需针对特定任务进行训练即可生成感知机器人形态的代价地图。
- 论文主要解决了现有 VLM 导航方法中在线查询延迟高、计算成本大以及缺乏行为约束推理的问题。
Card 01
研究单位
研究单位
- Field Robotics Engineering and Science Hub (FRESH), Illinois Autonomous Farm, University of Illinois at Urbana-Champaign (UIUC)
Card 02
论文概述
论文概述
- 论文提出了 CATNAV,这是一个基于缓存视觉-语言的可通行性导航框架,旨在解决机器人在非结构化环境中的零样本导航问题。
- 该框架利用多模态大语言模型(VLM)进行语义后果推理,无需针对特定任务进行训练即可生成感知机器人形态的代价地图。
- 论文主要解决了现有 VLM 导航方法中在线查询延迟高、计算成本大以及缺乏行为约束推理的问题。
Card 03
核心贡献
核心贡献
- 提出了一个零样本、感知形态的代价地图生成框架,利用 VLM 的常识推理能力推断物体的通行风险。
- 设计了一种视觉语义缓存机制,通过检测场景新颖性来复用缓存的风险评估,将在线 VLM 查询减少了 85.7%。
- 引入了一个基于 VLM 的轨迹推理模块,能够根据行为约束在多个路径提案中选择最安全的轨迹。
Card 04
方法描述
方法描述
- 利用 Gemini 3.0 Flash 多模态大模型分析 RGB 图像,根据机器人物理形态和语义内容生成风险评分表。
- 使用 CLIP 图像编码器将帧嵌入向量空间,通过 K 近邻检索判断场景是否新颖;若场景相似则复用缓存,否则查询 VLM。
- 采用 CLIPSeg 进行开放词汇分割,将风险评分投影到图像域并生成 2D 代价地图。
- 使用 TRRT (Transition-based RRT) 路径规划器生成多条候选轨迹(左、中、右、风险路径)。
- 通过 VLM 视觉评估覆盖在 RGB 图像上的路径提案,结合自然语言行为约束选择最优轨迹。
Card 05
数据集与资源
数据集与资源
- 硬件平台:Unitree Go1 四足机器人,配备 NVIDIA Jetson Orin 计算单元和 Stereolabs ZED 2i 相机。
- 模型资源:使用 Gemini 3.0 Flash 作为核心推理模型,CLIP 用于图像嵌入,CLIPSeg 用于分割。
- 测试环境:包含室内和室外环境的 5 个导航任务(人行道、障碍物、动态行人、室内纸张避障)。
Card 06
评估与结果
评估与结果
- 评估基准:与最先进的视觉-语言-动作模型 OmniVLA 进行对比。
- 评估指标:目标到达率、距目标距离、碰撞率、行为约束违规率。
- 关键结果:在五项导航任务中,CATNAV 的平均目标到达率比基线高出 10 个百分点,行为约束违规率减少了 33%。
- 效率提升:视觉语义缓存机制将 VLM 场景查询延迟降低,缓存利用率提高了 86.5%。