一眼看懂
封面预览
提出了 CaP-X 框架,旨在系统性研究和改进机器人操作中的“代码即策略”智能体。
- 提出了 CaP-X 框架,旨在系统性研究和改进机器人操作中的“代码即策略”智能体。
- 核心包含交互式环境 CaP-Gym、基准测试 CaP-Bench、无需训练的智能体框架 CaP-Agent0 以及强化学习方法 CaP-RL。
- 旨在解决现有视觉-语言-动作(VLA)模型在可解释性和泛化能力上的局限,探究代码生成智能体在不同抽象层级和交互模式下的机器人控制能力。
Card 01
研究单位
研究单位
- Max Fu, Justin Yu, Karim El-Refai, Ethan Kou, Haoru Xue, Huang Huang, Wenli Xiao, Guanzhi Wang, Fei-Fei Li, Guanya Shi, Jiajun Wu, Shankar Sastry, Yuke Zhu, Ken Goldberg, Linxi “Jim” Fan
- 注:原文 HTML 中机构信息因格式错误缺失 (
AUTHORERR: Missing \icmlaffiliation),故仅列出作者名单。
Card 02
论文概述
论文概述
- 提出了 CaP-X 框架,旨在系统性研究和改进机器人操作中的“代码即策略”智能体。
- 核心包含交互式环境 CaP-Gym、基准测试 CaP-Bench、无需训练的智能体框架 CaP-Agent0 以及强化学习方法 CaP-RL。
- 旨在解决现有视觉-语言-动作(VLA)模型在可解释性和泛化能力上的局限,探究代码生成智能体在不同抽象层级和交互模式下的机器人控制能力。
Card 03
核心贡献
核心贡献
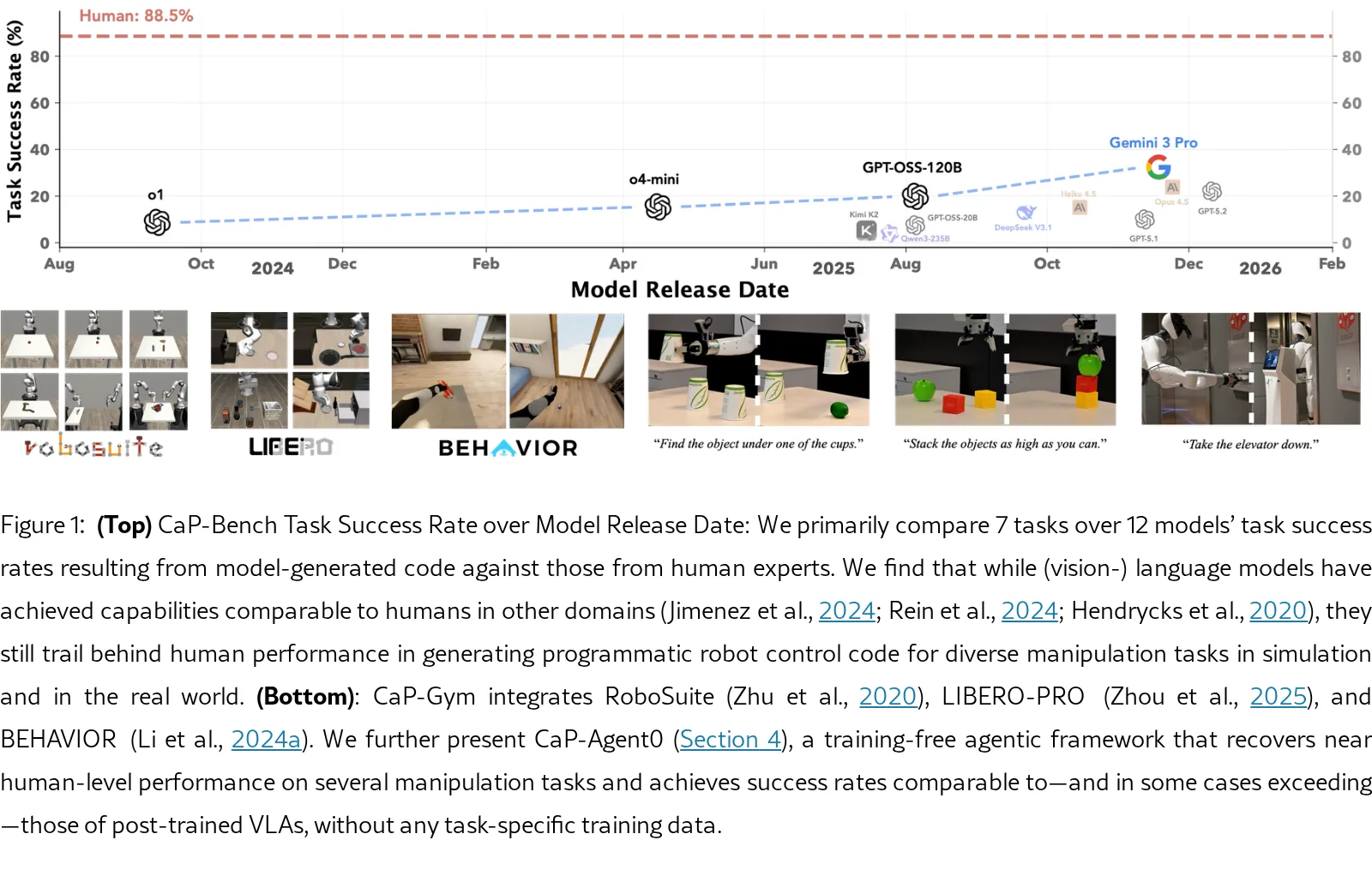
- 构建了 CaP-Gym,一个统一的机器人编程交互环境,集成了 RoboSuite、LIBERO-PRO 和 BEHAVIOR 等仿真器。
- 提出了 CaP-Bench 基准,从抽象层级(高层/低层原语)、时序交互(单轮/多轮)和感知接地三个维度系统评估模型能力。
- 开发了 CaP-Agent0,一种无需训练的框架,通过多轮视觉差分、自动合成技能库和并行推理显著提升了鲁棒性。
- 引入了 CaP-RL,利用强化学习微调代码生成模型,实现了从仿真到真机的有效迁移。
Card 04
方法描述
方法描述
- CaP-Gym 采用分层控制框架和 Read-Eval-Print Loop (REPL) 范式,提供从高层宏(如
stack_objs)到低层原子原语(如solve_ik,sam3_text_prompt)的接口。 - CaP-Agent0 包含三个关键设计:视觉差分模块 (VDM) 将视觉观察转化为结构化文本以解决跨模态对齐问题;自动合成技能库 从成功执行轨迹中提取可复用函数;并行推理 利用多个大模型(如 Gemini, GPT, Claude)生成候选代码并集成。
- CaP-RL 使用 Group Relative Policy Optimization (GRPO) 算法,基于环境奖励对 Qwen2.5-Coder-7B 模型进行强化学习微调。
Card 05
数据集与资源
数据集与资源
- 仿真环境:RoboSuite、LIBERO-PRO、BEHAVIOR。
- 评估任务:包含 7 个核心任务(Cube Lift, Cube Stack 等)及 LIBERO-PRO 和 BEHAVIOR 中的长视界任务。
- 评估模型:Gemini-3-Pro、GPT-5.2、Claude Opus 4.5、DeepSeek-V3.1、Qwen 等 12 个前沿模型。
- 实体机器人:Franka Panda 和 AgiBot G1。
Card 06
评估与结果
评估与结果
- 在 CaP-Bench 上发现,单轮设置下模型仍落后于人类专家,但多轮交互和视觉差分(M4 级别)能显著提升任务成功率。
- CaP-Agent0 在 7 个任务中的 4 个上达到了媲美甚至超越人类专家的性能,并在 LIBERO-PRO 的指令扰动测试中显著优于 OpenVLA 和 $\pi_{0.5}$ 等 VLA 方法。
- CaP-RL 将 Qwen2.5-Coder-7B 的 Cube Lift 任务成功率从 25% 提升至 80%(仿真),且在真机上达到了 84% 的成功率,验证了 Sim-to-Real 迁移能力。