一眼看懂
封面预览
论文提出了一种名为 DualCoT-VLA 的视觉-语言-动作模型,旨在解决现有模型在复杂任务中无法同时兼顾低层视觉细节与高层逻辑规划的问题。
- 论文提出了一种名为 DualCoT-VLA 的视觉-语言-动作模型,旨在解决现有模型在复杂任务中无法同时兼顾低层视觉细节与高层逻辑规划的问题。
- 针对当前基于思维链的 VLA 模型推理延迟高和自回归解码导致的错误累积问题,论文提出了一种并行的隐式推理机制。
- 该模型通过融合视觉思维链和语言思维链,实现了在单一前向传播中进行全面的多模态推理,显著提升了机器人在复杂操作任务中的表现。
Card 01
研究单位
研究单位
- The Hong Kong University of Science and Technology (Guangzhou)
- Huawei Foundation Model Department
Card 02
论文概述
论文概述
- 论文提出了一种名为 DualCoT-VLA 的视觉-语言-动作模型,旨在解决现有模型在复杂任务中无法同时兼顾低层视觉细节与高层逻辑规划的问题。
- 针对当前基于思维链的 VLA 模型推理延迟高和自回归解码导致的错误累积问题,论文提出了一种并行的隐式推理机制。
- 该模型通过融合视觉思维链和语言思维链,实现了在单一前向传播中进行全面的多模态推理,显著提升了机器人在复杂操作任务中的表现。
Card 03
核心贡献
核心贡献
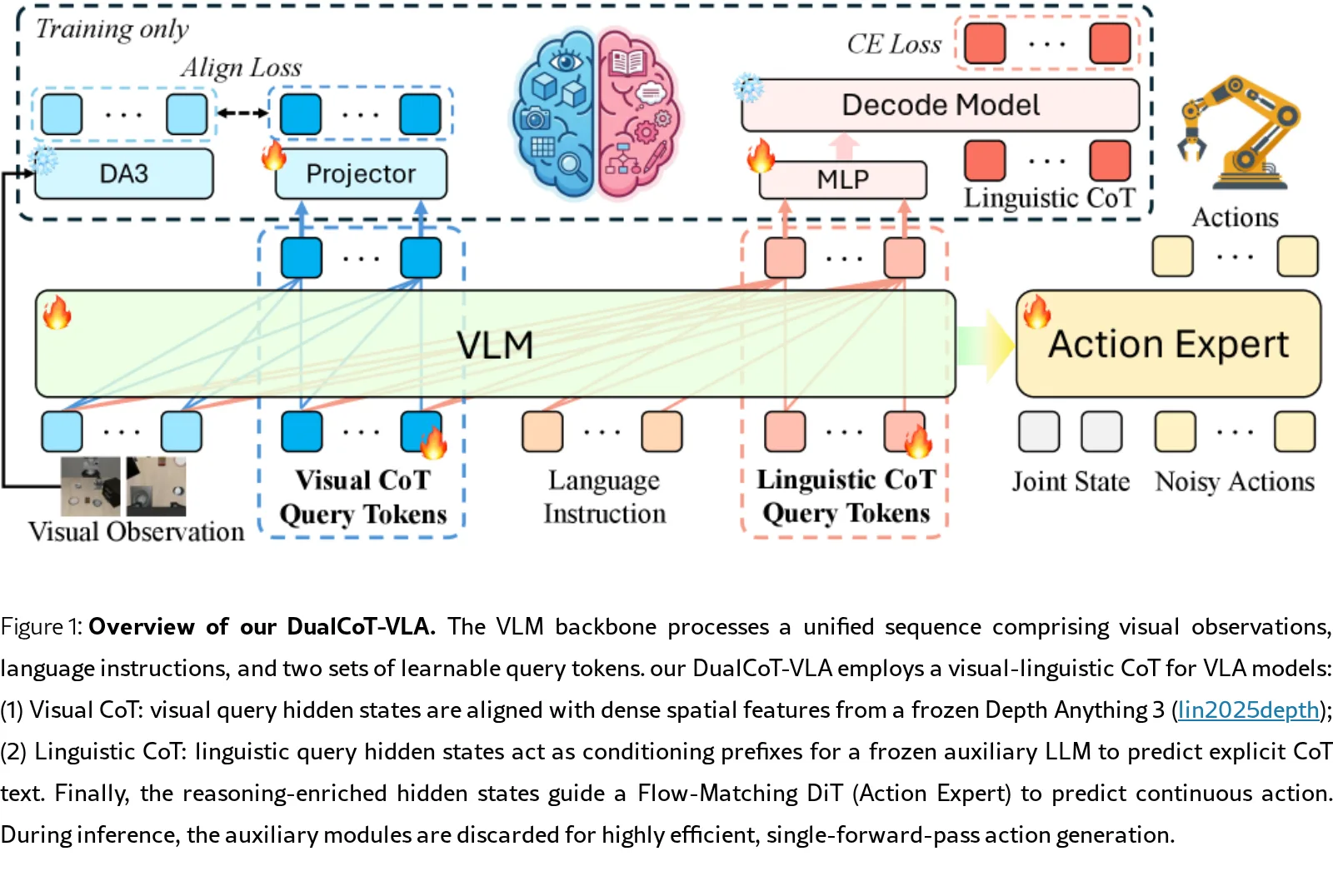
- 提出了 Visual-Linguistic Chain-of-Thought 范式,使 VLA 模型同时具备低层空间感知能力和高层逻辑规划能力。
- 引入了 DualCoT-VLA 架构,利用并行思维链机制绕过缓慢的自回归解码,实现了单步推理,大幅加速了下游动作预测。
- 在 LIBERO 和 RoboCasa GR1 基准测试以及真实机器人平台上取得了最先进的性能表现。
Card 04
方法描述
方法描述
- 模型架构基于 Qwen3-VL-4B 作为 VLM 主干,并包含一个下游的 Diffusion Transformer (DiT) 动作头。
- 引入两组可学习的查询令牌:Visual CoT query tokens 和 Linguistic CoT query tokens,通过单一前向传播生成隐式推理特征。
- Visual CoT 利用冻结的 Depth Anything 3 模型作为几何教师,通过交叉注意力和 MSE 损失对齐深度特征,提取 3D 空间线索。
- Linguistic CoT 使用冻结的 Qwen3-0.6B 作为辅助解码器,将隐状态解码为显式的任务规划文本,并通过交叉熵损失进行监督。
- 动作头采用 Flow Matching 目标进行训练,利用推理增强后的隐状态作为条件生成连续动作块。
Card 05
数据集与资源
数据集与资源
- 使用的数据集包括 LIBERO(包含 Spatial、Object、Goal、Long 四个任务套件)和 RoboCasa GR1 Tabletop Tasks。
- 真实世界实验基于 AgileX Cobot 双臂机器人平台(Mobile ALOHA 系统设计),包含 3 个不同难度的桌面操作任务。
- 训练资源使用 NVIDIA H100 GPUs。
- 模型主干使用 Qwen3-VL-4B,辅助教师模型为 Depth Anything 3 和 Qwen3-0.6B。
Card 06
评估与结果
评估与结果
- 在 LIBERO 基准测试中,模型平均成功率达到 98.8%,在 Spatial、Object 和 Long 套件中均创下新纪录。
- 在 RoboCasa GR1 基准测试中,模型在 24 个任务上取得了 55.1% 的平均成功率,优于所有基线方法。
- 真实世界实验表明,DualCoT-VLA 在 Easy、Medium 和 Hard 三项任务中的成功率均高于 OpenVLA-OFT 和 GR00T-N1.6。
- 相比于自回归思维链模型,并行推理机制显著降低了推理延迟并避免了级联错误。