一眼看懂
封面预览
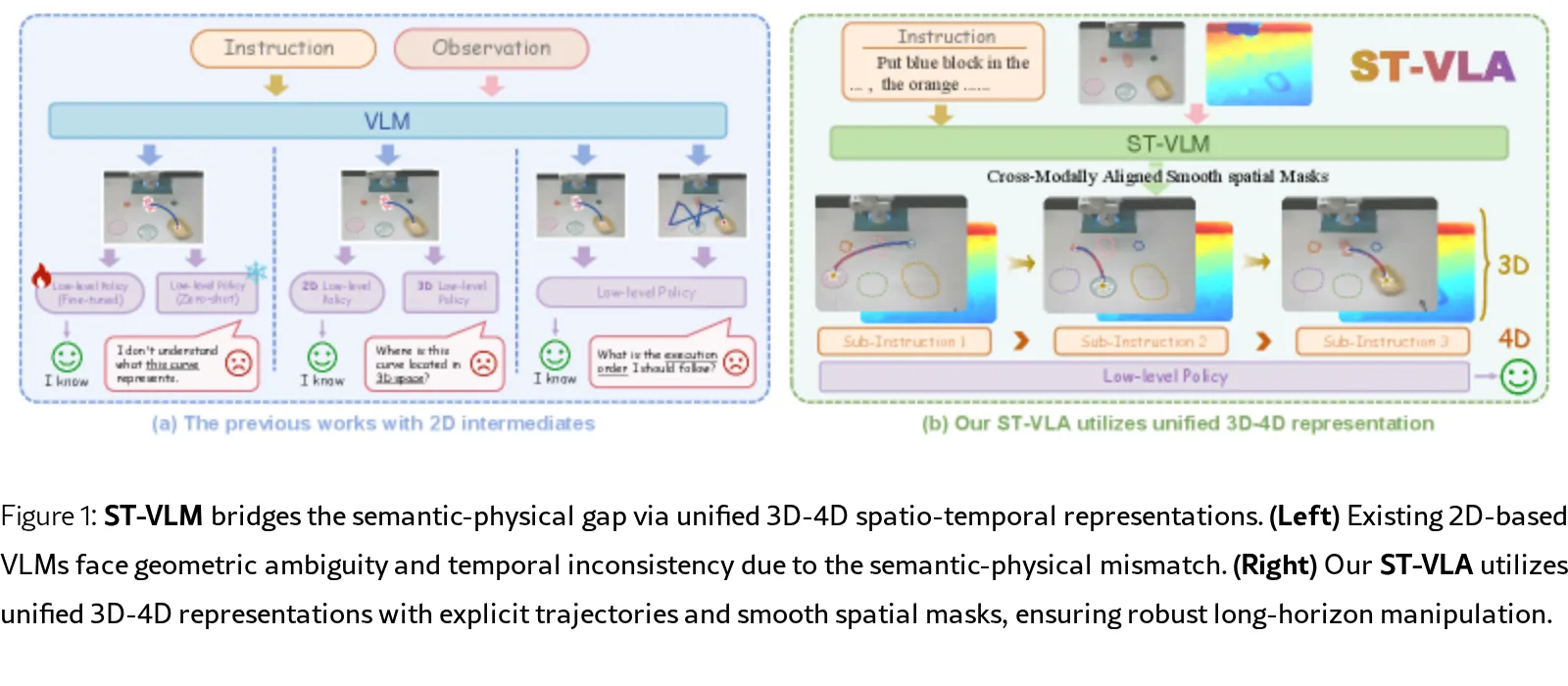
ST-VLA 是一个层次化的视觉-语言-动作(VLA)框架,使用统一的3D-4D表示来弥合感知与动作之间的差距,解决传统2D表示缺乏深度感知和…
- ST-VLA 是一个层次化的视觉-语言-动作(VLA)框架,使用统一的3D-4D表示来弥合感知与动作之间的差距,解决传统2D表示缺乏深度感知和…
- 论文提出ST-Human数据集,包含14个任务和30万条人类操作轨迹,标注了2D、3D和4D监督信号,用于训练具有时空推理能力的视觉语言模型
- 核心目标是实现开放世界环境中机器人的鲁棒操作,通过将语义推理卸载到VLM,使用统一的3D-4D表示显著提高零样本成功率和泛化能力
Card 01
研究单位
研究单位
- 中国科学技术大学(University of Science and Technology of China)
-安徽工业大学(Anhui University of Technology)
Card 02
论文概述
论文概述
- ST-VLA 是一个层次化的视觉-语言-动作(VLA)框架,使用统一的3D-4D表示来弥合感知与动作之间的差距,解决传统2D表示缺乏深度感知和时间一致性的问题
- 论文提出ST-Human数据集,包含14个任务和30万条人类操作轨迹,标注了2D、3D和4D监督信号,用于训练具有时空推理能力的视觉语言模型
- 核心目标是实现开放世界环境中机器人的鲁棒操作,通过将语义推理卸载到VLM,使用统一的3D-4D表示显著提高零样本成功率和泛化能力
Card 03
核心贡献
核心贡献
- 提出ST-VLA:层次化VLA框架,使用统一的3D-4D中间表示替代传统的2D先验,包含显式3D轨迹和潜在4D时空上下文,确保动作稳定性和抑制幻觉
- 构建ST-Human数据集:大规模3D-4D人类操作数据集,包含约43M样本,由60k视频(300k episodes)组成,通过半自动化pipeline生成统一的时空监督
- 训练ST-VLM:基于Qwen3-VL-4B微调的时空视觉语言模型,通过2D-3D-4D任务统一学习框架获得可迁移的3D-4D推理能力
- 实现分层控制:高-level VLM生成3D轨迹和空间掩码,low-level策略使用增强的观测空间进行连续动作执行,支持在线重规划和长时域推理
Card 04
方法描述
方法描述
- 层次化架构:将操作策略解耦为high-level VLM(π_hi)和low-level执行策略(π_lo),VLM生成统一中间表示Z={τ, M},其中τ为3D轨迹,M为空间掩码
- 时空VLM学习:采用两阶段监督微调策略,先使用公共多模态数据集进行通用语义推理,再在ST-Human上进行领域特定微调,学习2D轨迹 grounding、深度估计和长时域规划
- 3D轨迹构建:VLM预测2D轨迹后,结合RGB-D观测和起始深度信息,通过预测相对深度偏移将2D轨迹提升到3D空间
- 平滑空间掩码:使用SAM2生成的平滑边界掩码聚焦任务相关几何特征,稳定特征提取并抑制模型幻觉
Card 05
数据集与资源
数据集与资源
- 训练数据集:ST-Human(~4.3M样本,300k episodes,14个单臂桌面操作任务)
- 辅助数据集:RoboPoint、FSD、SAT等公共数据集
- 评估基准:RLBench(模拟)、真实机器人平台
- 模型规模:基于Qwen3-VL-4B参数规模
- 基线模型:3DDA(3D扩散Actor)、3DFA(3D特征Actor)
Card 06
评估与结果
评估与结果
- 评估环境:RLBench模拟环境和真实世界机器人平台
- 主要基准任务:Close Jar、Light Bulb In、Put Groceries等RLBench任务
- ST-VLM评估指标:在RoboRefit、CVBench、SAT等数据集上2D/3D/4D任务性能
- 关键实验结果:
- RLBench零样本成功率提升44.6%(模拟环境)
- 真实世界长时域任务提升30.3%
- ST-VLA w/ 3DDA (FT)在多任务设置下平均 Seen: 75.4%, Unseen: 67.9%
- 在ST-Human-Pointing达到96.50%,ST-Human-Depth达到46.67%,ST-Human-Planning达到92.00%