一眼看懂
封面预览
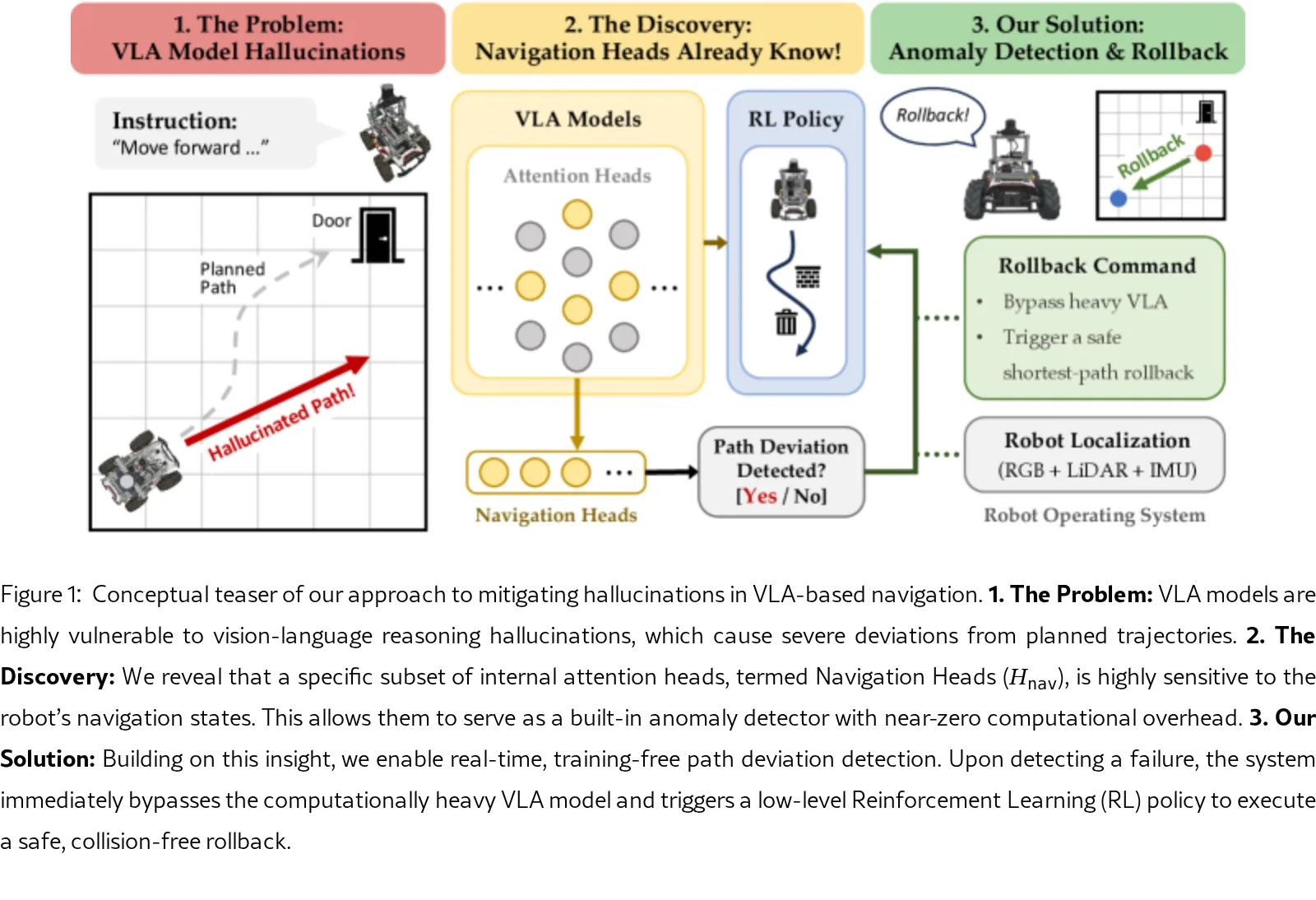
论文发现冻结的视觉-语言-动作模型内部存在少量“导航注意力头”,能够无需额外计算开销地实时检测路径偏差。
- 论文发现冻结的视觉-语言-动作模型内部存在少量“导航注意力头”,能够无需额外计算开销地实时检测路径偏差。
- 研究旨在解决VLA模型因视觉推理幻觉导致轨迹偏差的问题,避免传统方法中训练外部评论模块或复杂不确定性启发式方法的需求。
- 提出了一个无需训练的异常检测框架,并集成了轻量级强化学习策略,用于在检测到偏差时执行安全的回滚操作。
Card 01
研究单位
研究单位
- Korea University
- University of California, Los Angeles
- NVIDIA
Card 02
论文概述
论文概述
- 论文发现冻结的视觉-语言-动作模型内部存在少量“导航注意力头”,能够无需额外计算开销地实时检测路径偏差。
- 研究旨在解决VLA模型因视觉推理幻觉导致轨迹偏差的问题,避免传统方法中训练外部评论模块或复杂不确定性启发式方法的需求。
- 提出了一个无需训练的异常检测框架,并集成了轻量级强化学习策略,用于在检测到偏差时执行安全的回滚操作。
Card 03
核心贡献
核心贡献
- 识别并定义了“导航注意力头”,它们能够捕获视觉序列与语言指令间的时空因果关系,并揭示模型内部的导航状态。
- 提出了一个无训练的路径偏差检测框架,仅通过监控三个注意力头的动态信号,即可实现实时异常检测。
- 开发并集成了一个轻量级强化学习策略,用于在检测到异常时执行防碰撞的最短路径回滚,实现了完整的“检测-恢复”流程。
- 在真实世界机器人平台上成功部署并验证了整个系统的有效性与鲁棒性。
Card 04
方法描述
方法描述
- 以 NaVILA 模型为骨干,分析了其内部注意力头的功能特化,并提出了时空对齐评分和认知异常敏感性来筛选关键的导航注意力头。
- 提出了一种基于注意力熵相对得分变化的实时异常检测方法,通过监控导航注意力头信号的突变来识别路径偏差。
- 设计了一个轻量级演员-评论家架构的强化学习策略,以LiDAR代价地图和子目标状态为输入,实现防碰撞导航和回滚。
- 整个系统通过ROS 2框架部署,集成了VLA模型(0.3 Hz)进行高层推理和RL策略(10 Hz)进行底层控制。
Card 05
数据集与资源
数据集与资源
- 主要使用 VLN-CE R2R 数据集进行实验和评估。
- 使用的VLA模型基于 VILA-8B 架构,RL策略具有轻量级网络结构。
- 实验训练使用 NVIDIA RTX 6000 Ada GPU,真实机器人部署使用 NVIDIA Jetson AGX Orin (64 GB) 作为计算平台。
Card 06
评估与结果
评估与结果
- 在VLN-CE虚拟环境和真实机器人平台上进行了全面评估,对比了基于规则的启发式方法。
- 主要评估指标包括剧集检测率、错误剧集率、步骤级的精确率、召回率和F1分数。
- 实验表明,仅使用 3个导航注意力头 的组合,即可在 Val-Unseen 分割上实现 44.6%的EDR 和 11.7%的低FER,步骤级F1分数达 76.4%。
- 真实世界部署验证了该系统在动态环境中可靠导航与恢复的实用性和鲁棒性。