一眼看懂
封面预览
论文提出了 MEM (Multi-Scale Embodied Memory) ,一个为视觉语言动作模型设计的多尺度具身记忆系统
- 论文提出了 MEM (Multi-Scale Embodied Memory) ,一个为视觉语言动作模型设计的多尺度具身记忆系统
- 核心目标是通过结合不同模态的记忆来表示不同抽象层次的事件,解决机器人策略中长期和短期记忆的需求
- 解决了现有VLA模型在长时域任务中记忆表示效率低下、难以处理部分可观测性和上下文适应能力不足的问题
Card 01
研究单位
研究单位
- Physical Intelligence
- Stanford University
- UC Berkeley
- MIT
Card 02
论文概述
论文概述
- 论文提出了 MEM (Multi-Scale Embodied Memory) ,一个为视觉语言动作模型设计的多尺度具身记忆系统
- 核心目标是通过结合不同模态的记忆来表示不同抽象层次的事件,解决机器人策略中长期和短期记忆的需求
- 解决了现有VLA模型在长时域任务中记忆表示效率低下、难以处理部分可观测性和上下文适应能力不足的问题
Card 03
核心贡献
核心贡献
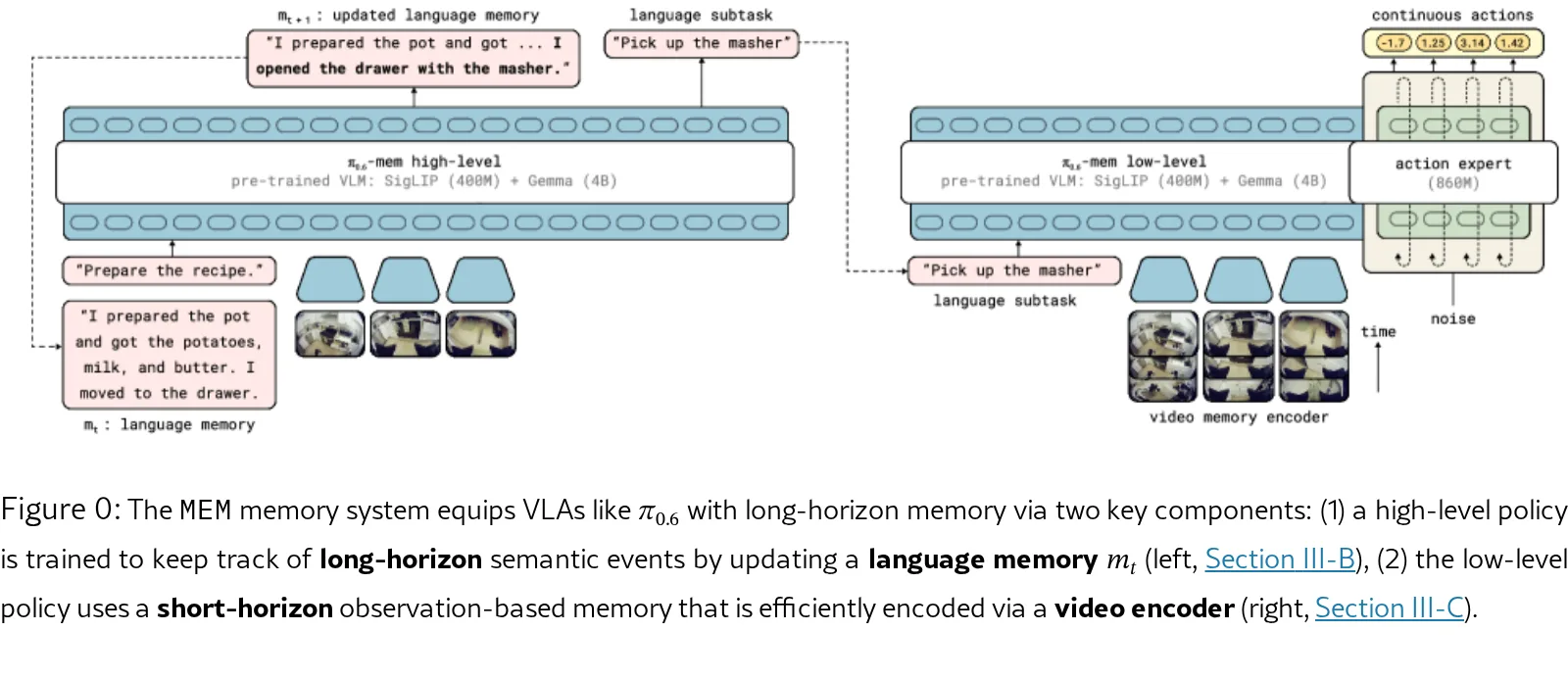
- 提出了 MEM系统 ,将基于视频的短时域记忆与基于语言的长时域记忆相结合
- 设计了高效的 视频编码器架构 ,使用时空可分离注意力机制压缩短期视觉记忆
- 引入了 语言记忆机制 ,通过LLM生成语义事件摘要来跟踪长期记忆
- 在长达15分钟的长时域操作任务中实现了先进的性能
- 展示了记忆系统使策略能够智能地在上下文中适应操作策略
Card 04
方法描述
方法描述
- 使用 视频编码器 处理短期密集视觉记忆:扩展ViT架构,每4层添加因果时间注意力,丢弃过去时间步的token以压缩输入
- 使用 语言记忆机制 处理长期语义记忆:高级策略预测语言记忆摘要mt+1,跟踪已完成步骤和语义事件
- 将系统整合到 π0.6 VLA模型 中,保持与单图像VLA相同的token数量和推理延迟
- 预训练使用包含机器人演示、策略rollout数据、人类纠正、视觉语言任务和视频语言任务的混合数据
Card 05
数据集与资源
数据集与资源
- 预训练数据包括远程操作机器人演示、策略rollout数据、人类纠正数据、视觉语言任务和视频语言任务
- 基于 Gemma3-4B VLM 初始化,包含 860M参数 的流匹配动作专家
- 训练使用 NVIDIA H100 GPU ,输入分辨率为448x448像素,支持最多四个摄像头流
- 预训练使用6帧观测序列(间隔1秒),后训练扩展到最多18帧和54秒的观测记忆
Card 06
评估与结果
评估与结果
- 在多种长时域操作任务上评估,包括食谱准备、厨房清洁、烤奶酪三明治制作等
- 主要评估指标为任务成功率和进度评分
- 在食谱准备任务中,MEM相比无记忆基线显著提高成功率
- 在厨房清洁任务中,MEM能够有效跟踪多步骤清洁过程
- 消融实验显示视频记忆和语言记忆都是必要的,两者结合效果最佳
- 在记忆能力测试中,MEM在处理部分可观测性、计数和空间记忆方面优于其他方法
- MEM在短时域灵巧操作任务上也匹配了无记忆VLA的性能