一眼看懂
封面预览
本文旨在解决 跨机器人策略学习 的核心挑战,即训练一个单一策略使其能在多种机器人形态(如不同关节结构、自由度)上表现良好。
- 本文旨在解决 跨机器人策略学习 的核心挑战,即训练一个单一策略使其能在多种机器人形态(如不同关节结构、自由度)上表现良好。
- 当前主流的 视觉-语言-动作(VLA)模型(如 π0.5)通常是形态不可知的,必须从观测中隐式学习运动学结构,这限制了其在单一形态内的性能和跨…
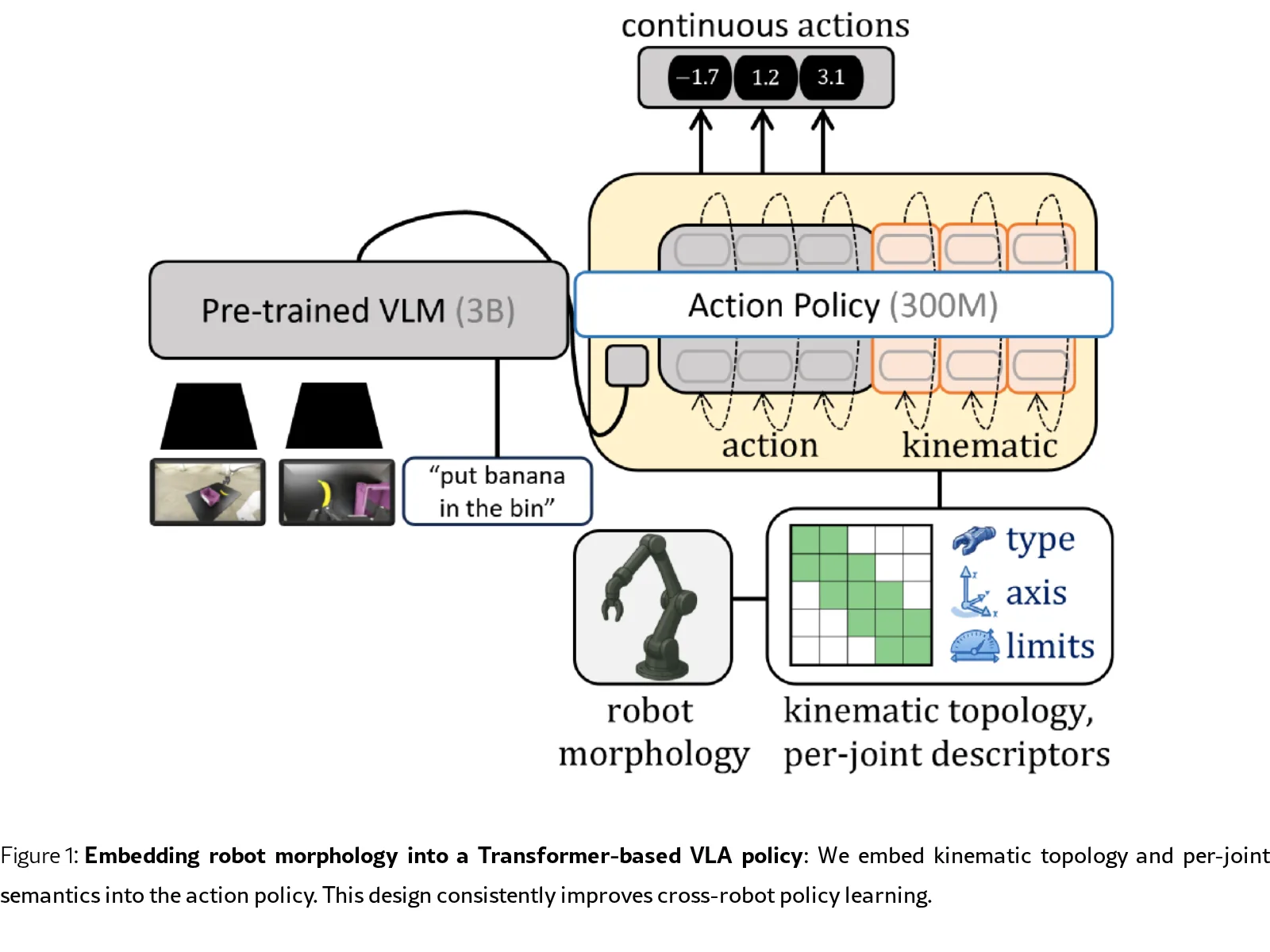
- 论文提出一种 形态感知的Transformer策略,通过显式注入机器人形态信息来提升策略的鲁棒性和泛化能力。
Card 01
研究单位
研究单位
- Kei Suzuki, Jing Liu, Ye Wang, Chiori Hori, Matthew Brand, Diego Romeres, Toshiaki Koike-Akino(原文未明确列出作者所属机构,根据作者姓名与合作模式推断可能涉及多个研究机构)
Card 02
论文概述
论文概述
- 本文旨在解决 跨机器人策略学习 的核心挑战,即训练一个单一策略使其能在多种机器人形态(如不同关节结构、自由度)上表现良好。
- 当前主流的 视觉-语言-动作(VLA)模型(如 π0.5)通常是形态不可知的,必须从观测中隐式学习运动学结构,这限制了其在单一形态内的性能和跨形态的泛化能力。
- 论文提出一种 形态感知的Transformer策略,通过显式注入机器人形态信息来提升策略的鲁棒性和泛化能力。
Card 03
核心贡献
核心贡献
- 提出三种将机器人形态嵌入 VLA 策略的机制:运动学令牌、拓扑感知注意力偏置 和 关节属性条件化。
- 设计了一种 关节层面的动作表示,将动作序列在关节维度分解并通过时间分块压缩,为形态嵌入提供了清晰的接口。
- 在 单一形态 和 多形态 学习设置下,所提方法在多个基准测试(DROID、Unitree G1 Dex1、SO101)上持续优于基准 π0.5 VLA模型,验证了方法的有效性。
Card 04
方法描述
方法描述
- 运动学令牌:将时间序列动作按关节分解,并将时间步长分块压缩,形成每个关节的紧凑表示,作为策略的额外上下文。
- 拓扑感知注意力:在自注意力机制中引入基于运动学图(节点为关节,边为物理连接)的偏置。提出了 Mix-Mask 方法,交替使用拓扑约束的局部注意力和全局注意力,以平衡局部消息传递与全局协调。
- 关节属性条件化:使用 FiLM(特征线性调制) 层,根据每个关节的描述符(如关节类型、轴向、运动范围、摩擦系数等)来调节运动学令牌的嵌入,注入超越连接关系的语义信息。
Card 05
数据集与资源
数据集与资源
- 使用数据集:DROID (Franka Panda机械臂数据集)、Unitree G1 Dex1 仿真数据集、SO101 数据集(来自LeRobot)。
- 模型基于 π0.5 VLA基座模型。微调方式包括 AP-FT(约450M可训练参数)和 Full-FT(约3.5B可训练参数)。
- 训练资源:原文未明确说明具体GPU/TPU资源消耗。
Card 06
评估与结果
评估与结果
- 评估环境:在仿真环境中进行语言条件下的抓取-放置任务评估。
- 主要评估指标:任务成功率,并报告95%置信区间。
- 关键实验结果:
- 在 DROID 单形态评估中,完整模型(KT + Mix-Mask + FiLM)的平均成功率(47.4%)显著高于基准 π0.5 模型(19.7%)。
- 在 Unitree G1 Dex1 单形态评估中,完整模型同样取得了最佳成功率(28.0%)。
- 在 DROID + SO101 多形态联合训练中,提出的方法在训练全程均优于基准模型,显示了更好的跨形态学习效率。