一眼看懂
封面预览
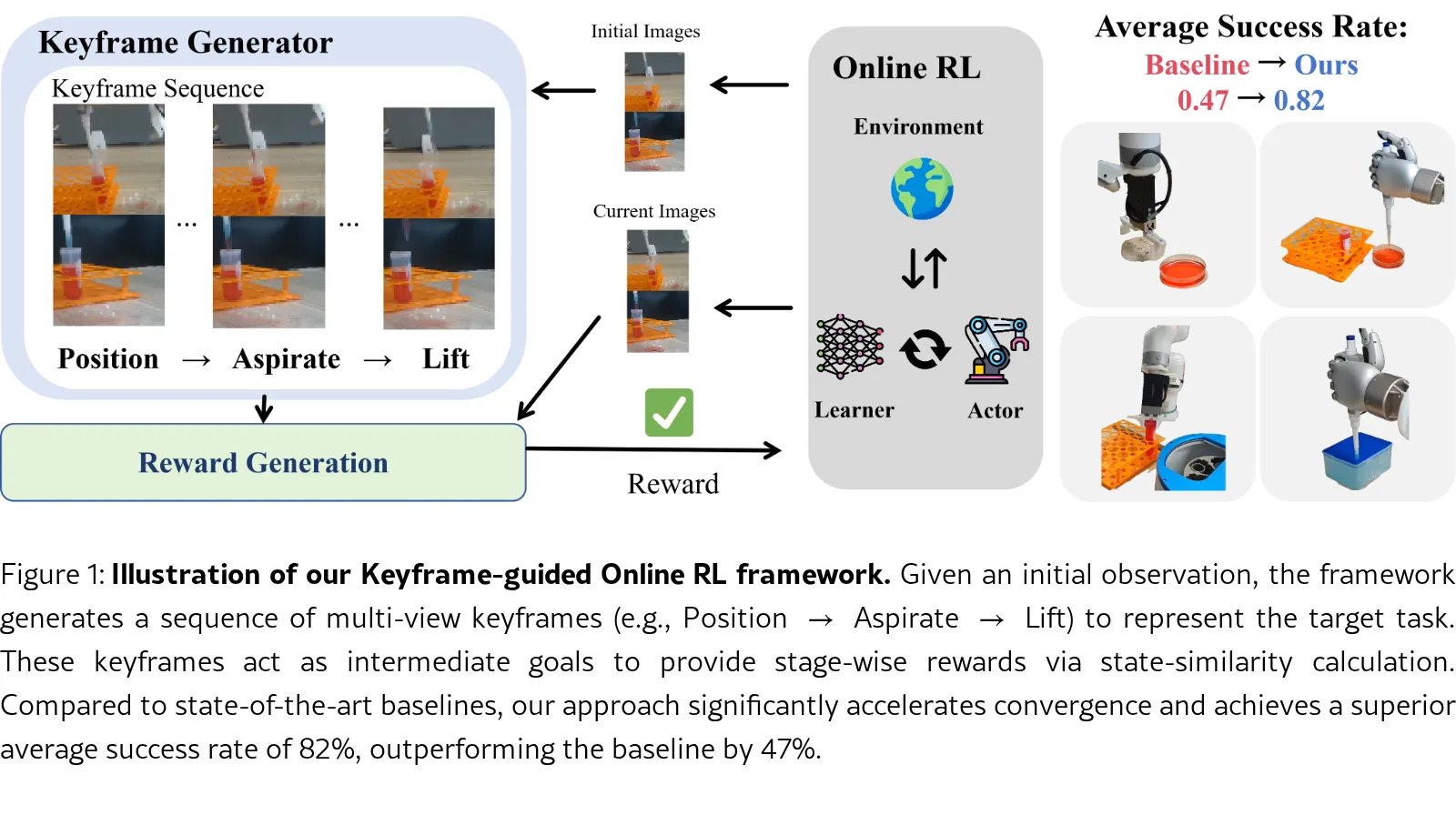
论文提出一个关键帧引导的奖励生成框架,用于解决实验室自动化中长时域、高精度操作(如移液器尖端安装、液体转移)面临的奖励稀疏、多阶段结构约束及演…
- 论文提出一个关键帧引导的奖励生成框架,用于解决实验室自动化中长时域、高精度操作(如移液器尖端安装、液体转移)面临的奖励稀疏、多阶段结构约束及演…
- 核心目标是通过自动从演示中提取关键帧并转化为阶段性的密集奖励信号,提升强化学习在长时域任务中的样本效率与收敛稳定性。
- 该方法旨在无需人工设计奖励函数或高质量专家演示的情况下,实现策略优化与生物实验流程内在逻辑的对齐。
Card 01
研究单位
研究单位
- 中国科学技术大学苏州高等研究院,苏州,江苏,中国
- 中国科学技术大学生命科学与医学部生物医学工程学院,合肥,安徽,中国
Card 02
论文概述
论文概述
- 论文提出一个关键帧引导的奖励生成框架,用于解决实验室自动化中长时域、高精度操作(如移液器尖端安装、液体转移)面临的奖励稀疏、多阶段结构约束及演示数据不完美的挑战。
- 核心目标是通过自动从演示中提取关键帧并转化为阶段性的密集奖励信号,提升强化学习在长时域任务中的样本效率与收敛稳定性。
- 该方法旨在无需人工设计奖励函数或高质量专家演示的情况下,实现策略优化与生物实验流程内在逻辑的对齐。
Card 03
核心贡献
核心贡献
- 提出一种运动感知的关键帧提取机制,能够自动从非专家演示中识别结构关键状态。
- 设计一种基于潜在相似性的阶段性奖励公式,将提取的关键帧转化为进度感知的密集奖励,用于长时域强化学习。
- 实现了多视图感知、关键帧引导奖励与人机交互微调在视觉-语言-动作主干模型上的集成,用于真实世界实验室操作。
- 在四个真实实验室任务上进行了广泛验证,证明了该方法在收敛速度和成功率上的显著提升。
Card 04
方法描述
方法描述
- 潜在动力学关键帧提取:分析演示序列中特征的速度与加速度,通过转折点挖掘和固定预算选择,自动提取代表关键操作节点(如定位、吸取、提升)的关键帧。
- 生成式扩散奖励系统:训练一个扩散模型,根据初始观测和任务指令生成潜在空间中的阶段目标序列。通过计算当前状态与目标序列在潜在空间的余弦相似度,跟踪任务进度并计算基于几何级数的阶段性奖励。
- 在线策略演化:基于Octo视觉-语言-动作模型,使用一致性策略进行高效推理。采用Hil-ConRFT框架进行训练,结合在线回放缓冲区和演示缓冲区的混合采样,并通过人机交互收集修正数据。
Card 05
数据集与资源
数据集与资源
- 任务数据:包含四个真实世界实验室操作任务:培养皿揭盖、离心管加载、精准液体转移、移液器尖端安装。每个任务包含少量非专家演示数据用于离线训练。
- 模型规模:策略主干使用预训练的Octo模型(大型视觉-语言-动作模型)。
- 训练资源:所有训练与推理在配备 NVIDIA RTX 5880 Ada GPU 的工作站上进行。
Card 06
评估与结果
评估与结果
- 评估环境:在Jaka Minicobo机器人上开展四个真实的实验室操作任务,涉及物体搬迁、高精度接触丰富操作和动态液体处理。
- 主要评估指标:任务成功率、人机干预率、训练曲线。
- 关键实验结果:
- 方法在四个任务上平均成功率达到 82%,显著优于基线方法:HG-DAgger (42%)、Hil-ConRFT (47%) 和 Hil-SERL (0%)。
- 在最具挑战性的“精准液体转移”任务上,方法成功率达到 100%,而所有基线方法均近乎失败。
- 消融实验证明,关键帧提取机制能将“核心里程碑召回率”从 0.525 提升至 0.938,关键帧引导奖励对任务成功至关重要。