一眼看懂
封面预览
提出了 DriveWorld-VLA,一个用于端到端自动驾驶的统一框架,将视觉-语言-动作(VLA)模型与世界模型(WM)紧密集成在统一的潜在…
- 提出了 DriveWorld-VLA,一个用于端到端自动驾驶的统一框架,将视觉-语言-动作(VLA)模型与世界模型(WM)紧密集成在统一的潜在…
- 旨在解决现有方法中未来场景演化与动作规划无法有效统一、潜在状态共享不足的问题,从而增强视觉想象力对动作决策的影响。
- 通过在潜在空间进行世界建模,支持可控的、动作条件的想象,避免了昂贵的像素级展开,实现了前瞻性的因果推理。
Card 01
研究单位
研究单位
- 作者:Feiyang Jia, Lin Liu, Ziying Song, Caiyan Jia, Hangjun Ye, Xiaoshuai Hao, Long Chen(原文片段未提供具体所属机构名称)
Card 02
论文概述
论文概述
- 提出了 DriveWorld-VLA,一个用于端到端自动驾驶的统一框架,将视觉-语言-动作(VLA)模型与世界模型(WM)紧密集成在统一的潜在空间中。
- 旨在解决现有方法中未来场景演化与动作规划无法有效统一、潜在状态共享不足的问题,从而增强视觉想象力对动作决策的影响。
- 通过在潜在空间进行世界建模,支持可控的、动作条件的想象,避免了昂贵的像素级展开,实现了前瞻性的因果推理。
Card 03
核心贡献
核心贡献
- 提出了 DriveWorld-VLA 框架,将世界模型作为连接动作与前瞻想象的推理引擎,实现了紧密耦合。
- 引入了 Feature-Level Sharing,利用 LLM 隐藏状态作为共享潜在空间,帮助模型内化物理规律和环境动态。
- 开发了基于动作条件的“what-if”推理机制,利用 Diffusion Transformer (DiT) 生成和评估候选轨迹,实现了前瞻性的决策优化。
- 提出了三阶段渐进式训练范式,依次对齐多模态感知、动作可控性和闭环动作精炼。
Card 04
方法描述
方法描述
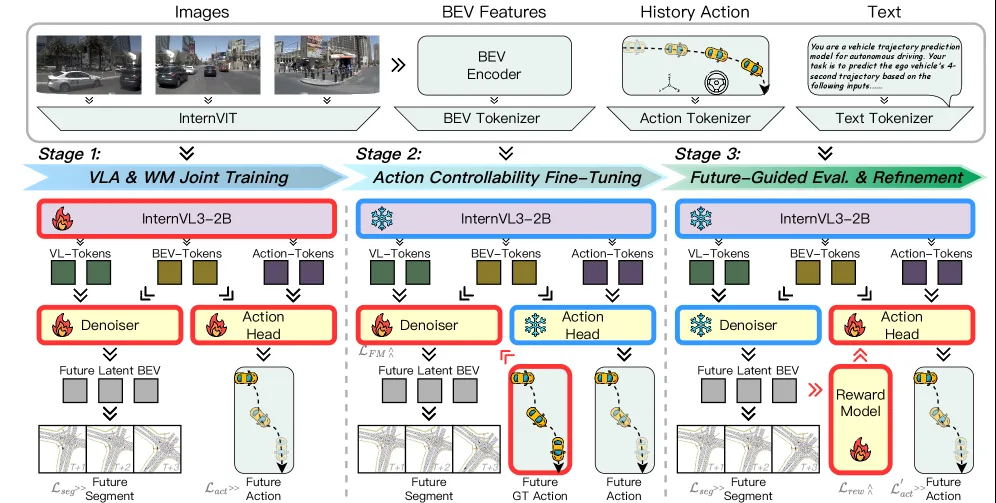
- 采用三阶段训练范式:第一阶段联合训练 VLA 与世界模型,利用共享潜在表示进行未来 BEV 想象和动作预测;第二阶段通过流匹配去噪微调动作可控性;第三阶段建立闭环,通过奖励反馈精炼动作预测。
- 模型架构基于 InternVL 进行多模态 Tokenization,使用 BEVFormer 提取 BEV 特征,并使用 DiT 架构进行未来 BEV 状态的去噪生成。
- 核心创新在于将世界模型的潜在状态作为 VLA 规划器的核心决策变量,实现了动作对未来场景演化影响的直接评估。
Card 05
数据集与资源
数据集与资源
- 使用的数据集:NAVSIMv1、NAVSIMv2、nuScenes。
- 骨干网络:NAVSIM 实验使用 ResNet-34,nuScenes 实验使用 Swin-T。
- 训练资源:使用 8 张 NVIDIA H20 GPU 进行训练。
Card 06
评估与结果
评估与结果
- 评估环境:NAVSIMv1 和 NAVSIMv2 进行闭环评估,nuScenes 进行开环规划评估。
- 主要指标:PDMS、EPDMS、L2 误差、碰撞率(CR)。
- 关键结果:在 NAVSIMv1 上达到 91.3 PDMS,在 NAVSIMv2 上达到 86.8 EPDMS,在 nuScenes 上达到 0.16% 的平均碰撞率,均显著优于现有基线模型。