一眼看懂
封面预览
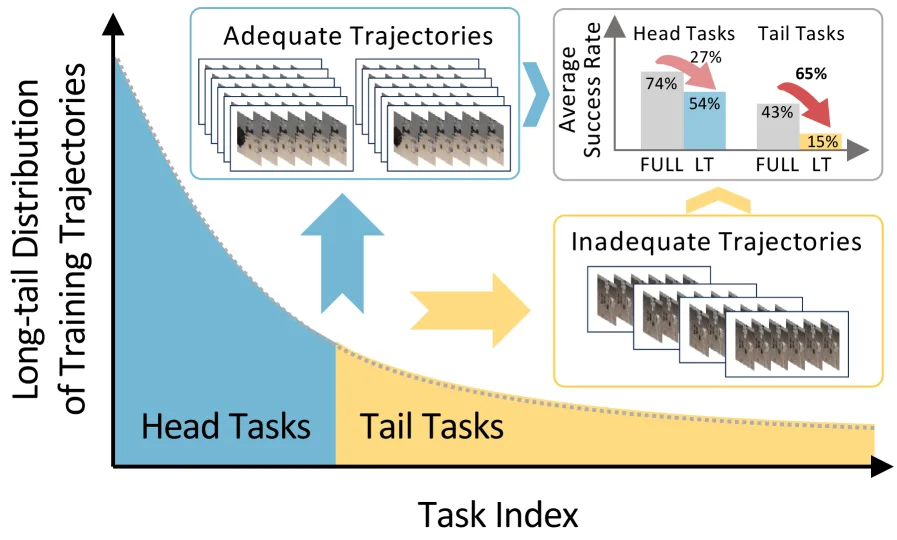
论文针对机器人模仿学习中普遍存在的长尾分布问题展开研究,旨在解决训练数据不平衡导致模型在数据稀少的尾部任务上性能严重下降的挑战。
- 论文针对机器人模仿学习中普遍存在的长尾分布问题展开研究,旨在解决训练数据不平衡导致模型在数据稀少的尾部任务上性能严重下降的挑战。
- 研究发现,传统长尾学习策略(如重采样)在机器人策略学习中失效,其根本原因是数据稀缺损害了策略的空间推理能力。
- 论文提出了接近阶段增强 方法,通过从数据丰富的头部任务向数据稀缺的尾部任务迁移知识,在不依赖外部演示数据的情况下,有效提升模型在尾部任务上的表…
Card 01
研究单位
研究单位
- 电子科技大学
- 西南交通大学
- 同济大学
Card 02
论文概述
论文概述
- 论文针对机器人模仿学习中普遍存在的长尾分布问题展开研究,旨在解决训练数据不平衡导致模型在数据稀少的尾部任务上性能严重下降的挑战。
- 研究发现,传统长尾学习策略(如重采样)在机器人策略学习中失效,其根本原因是数据稀缺损害了策略的空间推理能力。
- 论文提出了接近阶段增强 方法,通过从数据丰富的头部任务向数据稀缺的尾部任务迁移知识,在不依赖外部演示数据的情况下,有效提升模型在尾部任务上的表现。
Card 03
核心贡献
核心贡献
- 构建了一个基于LIBERO环境的长尾模仿学习基准,并通过系统性分析揭示了尾部任务性能下降的核心在于空间推理能力受损。
- 提出了接近阶段增强 方法,该方法简单有效,通过将尾部任务对象嫁接到头部任务的接近轨迹上,生成高质量训练数据以增强策略的空间推理能力。
- 在仿真和真实世界的16个多样化操作任务上进行了广泛实验,验证了APA方法能显著提升尾部任务的成功率,且不影响头部任务性能。
Card 04
方法描述
方法描述
- APA方法包含三个关键步骤:头部任务轨迹分割、尾对头物体嫁接 和 指令格式化与联合训练。
- 创新点在于聚焦“目标接近阶段”进行增强,而非生成完整轨迹。该阶段对空间推理要求最高,且不受后续物理交互约束,使得增强过程简单且有效。
- 技术上,在仿真环境中直接替换对象资源;在真实世界中,利用YOLOv8进行物体检测和图像修复来实现物体嫁接。
Card 05
数据集与资源
数据集与资源
- LIBERO-Core-LT:基于LIBERO环境构建的长尾仿真数据集,包含10个任务,训练演示按帕累托分布采样。
- Real-World-LT:包含6个真实世界操作任务的长尾数据集。
- 主要评估模型:仿真实验使用在LIBERO-90上预训练的miniVLA;真实世界实验使用在OXE数据集上预训练的π0模型。
- 真实世界实验硬件:AGILEX PIPER 6自由度机械臂。
Card 06
评估与结果
评估与结果
- 评估基准:自建的长尾模仿学习基准(仿真与真实世界)。
- 主要评估指标:任务成功率。
- 关键结果:
- 仿真实验中,APA将平均成功率从26.5% 提升至36.1%(相对提升36.2%)。
- 真实世界实验中,APA将平均成功率从39.1% 提升至54.1%(相对提升38.4%)。
- 结果表明APA在显著提升尾部任务性能的同时,对头部任务性能亦有增益,证明了方法的有效性与全面性。