一眼看懂
封面预览
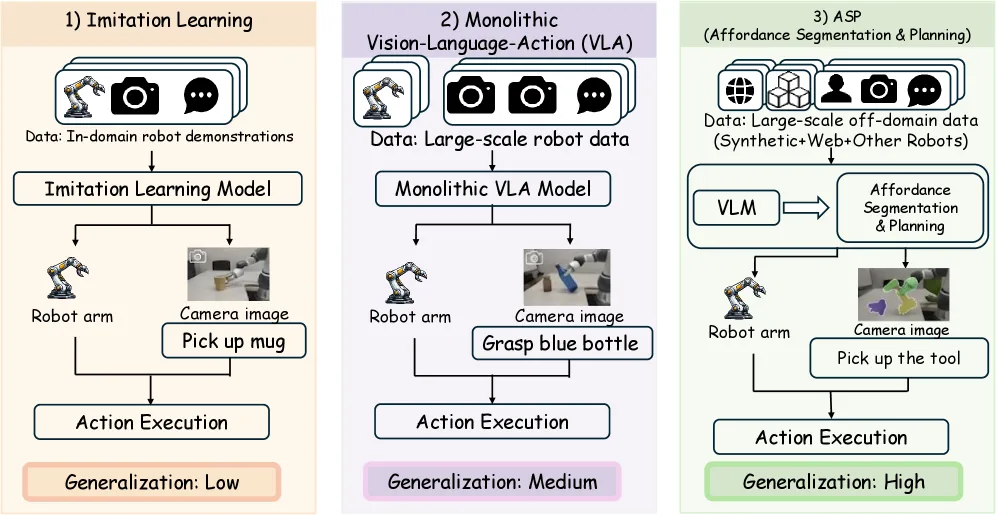
提出了一个名为 GeneralVLA 的层次化视觉-语言-动作模型,旨在利用基础模型的泛化能力,实现零样本机器人操作和自动生成机器人数据。
- 提出了一个名为 GeneralVLA 的层次化视觉-语言-动作模型,旨在利用基础模型的泛化能力,实现零样本机器人操作和自动生成机器人数据。
- 解决现有单一架构VLA模型在零样本泛化能力、精细坐标预测和长时规划方面的不足。
- 该方法无需真实世界机器人数据或人类演示,具有更高的可扩展性。
Card 01
研究单位
研究单位
- CASIA
- 北京大学
Card 02
论文概述
论文概述
- 提出了一个名为 GeneralVLA 的层次化视觉-语言-动作模型,旨在利用基础模型的泛化能力,实现零样本机器人操作和自动生成机器人数据。
- 解决现有单一架构VLA模型在零样本泛化能力、精细坐标预测和长时规划方面的不足。
- 该方法无需真实世界机器人数据或人类演示,具有更高的可扩展性。
Card 03
核心贡献
核心贡献
- 提出了一个零样本 3D轨迹规划框架,通过层次化VLA架构充分利用基础模型的先验知识。
- 设计了 ASM(Affordance Segmentation Module) 和 知识库,前者结合VLM与SAM实现精确的功能可见性分割,后者用于存储和重用跨任务技能。
- 实验证明,该方法在多样化操作任务中实现了高零样本准确率,且其生成的数据质量高、可扩展,可用于训练鲁棒的行为克隆策略。
Card 04
方法描述
方法描述
- 采用三层层次化架构:高层 ASM 负责场景感知与物体关键点定位;中层 3DAgent 进行任务理解、技能调用与轨迹规划,生成3D路径;底层策略根据3D路径执行精确操作。
- ASM 将多模态大语言模型(MLLM)与 SAM 结合,并通过迭代优化机制提升分割精度。
- 引入 知识库 以实现经验的总结、存储与重用,形成闭环学习。
- 设计 HGM 模块融合RGB、深度和3D点信息,以提升抓取姿态估计的精度。
Card 05
数据集与资源
数据集与资源
- 主要使用 RLBench 仿真基准进行评估,涵盖 14 个多样化的操作任务。
- 在真实世界实验中使用 Agilex-2.0 Piper 机械臂和 Intel RealSense L515 RGB-D相机。
- 行为克隆策略的训练在 单张RTX A40 GPU 上完成。
- 使用 Deepseek R1 作为推理和规划的文本大模型。
Card 06
评估与结果
评估与结果
- 在 RLBench 仿真环境的14项任务中进行零样本评估,并在 10项 任务上优于 VoxPoser、Code-as-Policies、Scaling-up 等最先进方法。
- 使用GeneralVLA生成的数据训练的 RVT-2 行为克隆策略,其性能接近使用人类专家演示训练的策略,且优于其他自动生成数据训练的策略。
- 真实世界实验在4项代表性任务(如移动喷壶、开抽屉、开罐子、物体分类)上成功展示了零样本操作能力。