一眼看懂
封面预览
针对连续动作视觉-语言-动作(VLA)模型,论文指出现有的均方误差(MSE)监督仅关注逐点预测,忽略了动作误差分布的全局结构。
- 针对连续动作视觉-语言-动作(VLA)模型,论文指出现有的均方误差(MSE)监督仅关注逐点预测,忽略了动作误差分布的全局结构。
- 为了解决该问题,论文引入信息论原则,提出了轨迹级最小误差熵及其两种加权变体,以重塑动作误差分布。
- 研究目标是在不增加推理开销的情况下,提升 VLA 模型在标准、少样本、噪声及数据不平衡等多种设置下的成功率和鲁棒性。
Card 01
研究单位
研究单位
- 西安交通大学 人工智能与机器人研究所
- 北京智源人工智能研究院
- 中国科学院大学 自动化研究所 / 人工智能学院
- 北京大学
Card 02
论文概述
论文概述
- 针对连续动作视觉-语言-动作(VLA)模型,论文指出现有的均方误差(MSE)监督仅关注逐点预测,忽略了动作误差分布的全局结构。
- 为了解决该问题,论文引入信息论原则,提出了轨迹级最小误差熵及其两种加权变体,以重塑动作误差分布。
- 研究目标是在不增加推理开销的情况下,提升 VLA 模型在标准、少样本、噪声及数据不平衡等多种设置下的成功率和鲁棒性。
Card 03
核心贡献
核心贡献
- 首次将最小误差熵(MEE)准则引入 VLA 模型,提出了三种轨迹级变体(T-MEE, Cw-TMEE, Ew-TMEE)来捕获结构化的动作误差分布。
- 提供了深入的理论分析,阐明了 MEE 目标函数的优化行为,包括误差间的相似性加权交互、对非高斯噪声和异常值的鲁棒性以及多任务设置下的耦合机制。
- 在多种 VLA 架构、模型规模(小规模到 2B+ 参数)和训练环境下进行了广泛的实证评估,验证了方法的有效性并分析了其适用范围。
Card 04
方法描述
方法描述
- 将动作预测误差视为从共享误差分布中抽取的样本,通过二次 Renyi 熵来最小化误差分布的熵,鼓励误差分布更加紧凑。
- 提出了统一的轨迹级 MEE(T-MEE)目标函数,该函数聚合了批次、时间和动作块维度的误差。
- 引入了两种加权变体:Chunk-weighted T-MEE (Cw-TMEE) 强调可靠的动作块,Element-weighted T-MEE (Ew-TMEE) 则提供对称的元素级加权。
- 最终训练目标将分布级 T-MEE 损失与标准的逐点 MSE 损失相结合,以同时保证预测精度和误差分布的几何结构。
Card 05
数据集与资源
数据集与资源
- 仿真基准:LIBERO(包含 Spatial, Goal, Object, Long 四个任务套件,共 40 个任务)和 SimplerEnv(WidowX 基准)。
- 模型规模:小规模模型(BC-RNN, BC-Transformer, BC-DP,参数量 10M-100M);大规模模型(GR00T, OFT, $\pi_0$, DS-VLA,基于 Qwen3-VL 骨干网络,参数量约 2.3B)。
- 真实世界实验:使用真实机械臂进行操作任务评估。
- 训练资源:文中未明确提及具体 GPU/TPU 数量,但实验涵盖了大规模模型训练。
Card 06
评估与结果
评估与结果
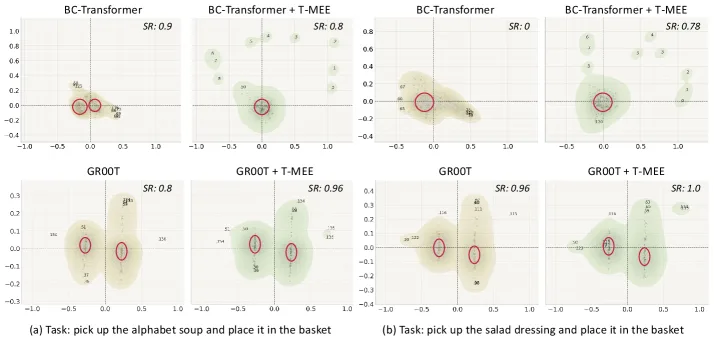
- 评估环境:LIBERO 仿真环境、SimplerEnv 仿真环境以及真实机器人操作平台。
- 主要指标:任务成功率。
- 关键结果:
- 在 LIBERO 基准上,加入 T-MEE 后,BC-Transformer 的平均成功率从 52.6% 提升至 63.5%,GR00T 模型从 96.4% 提升至 97.0%。
- 在 SimplerEnv 基准上,T-MEE 在 2B 和 4B 不同骨干网络规模下均带来了性能提升。
- 在少样本、噪声干扰和数据不平衡的设置下,T-MEE 展现出更强的鲁棒性,且几乎没有增加额外的训练成本,不影响推理效率。