研究目标:从时间同步的多视角视频中学习动作中心的离散潜在动作(latent actions),用于视觉语言动作(VLA)模型的预训练
- 研究目标:从时间同步的多视角视频中学习动作中心的离散潜在动作(latent actions),用于视觉语言动作(VLA)模型的预训练
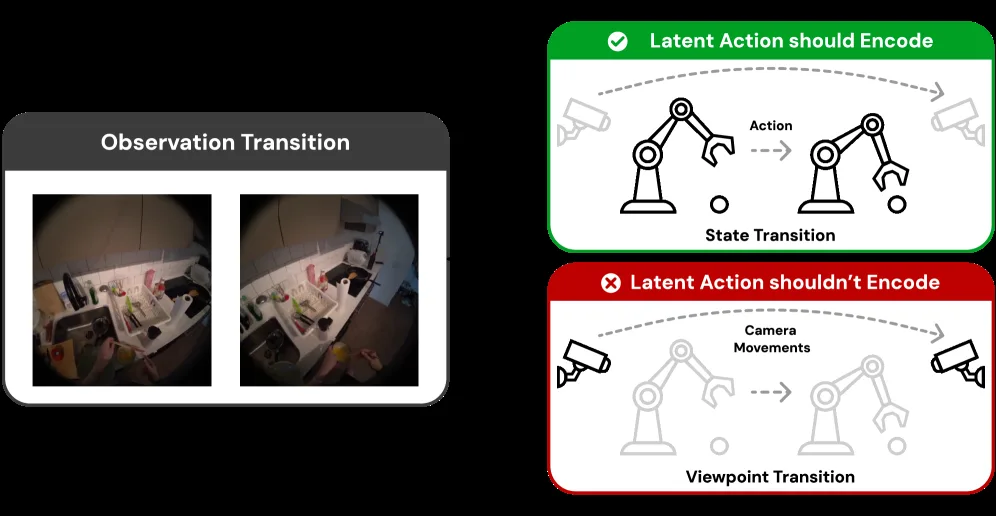
- 核心问题:视角变化作为外生噪声引入干扰,同一底层动作在不同视角下可能产生不同的视觉过渡,导致潜在动作过度拟合视角依赖线索而失去对动作的预测能力
- 研究方案:提出 MVP-LAM(Multi-Viewpoint Latent Action Model),通过跨视角重建目标训练,使从某一视角…
研究单位
- 论文作者列表:Jung Min Lee, Dohyeok Lee, Seokhun Ju, Taehyun Cho, Jin Woo Koo, Li Zhao, Sangwoo Hong, Jungwoo Lee
- 关键词:latent action, vision-language-action model
论文概述
- 研究目标:从时间同步的多视角视频中学习动作中心的离散潜在动作(latent actions),用于视觉语言动作(VLA)模型的预训练
- 核心问题:视角变化作为外生噪声引入干扰,同一底层动作在不同视角下可能产生不同的视觉过渡,导致潜在动作过度拟合视角依赖线索而失去对动作的预测能力
- 研究方案:提出 MVP-LAM(Multi-Viewpoint Latent Action Model),通过跨视角重建目标训练,使从某一视角推断的潜在动作能够解释另一视角的未来观测,从而减少对视角特定线索的依赖
核心贡献
- 贡献点 1:提出 MVP-LAM,使用时间同步的多视角视频和跨视角重建目标学习离散潜在动作,从一个视角推断的潜在动作用于预测另一视角的未来观测
- 贡献点 2:在 Bridge V2 数据集上证明 MVP-LAM 实现了与真实动作的最高互信息估计,并提高了动作预测准确率(包括分布外评估)
- 贡献点 3:证明使用 MVP-LAM 潜在动作作为伪标签进行 VLA 预训练可提升下游操作性能,在 SIMPLER 和 LIBERO-Long 基准测试中优于基线方法
- 贡献点 4:消融实验验证了人类视频数据集和跨视角重建目标对学习动作中心潜在动作的必要性
方法描述
- 技术方法:基于 VQ-VAE(向量量化变分自编码器)架构的潜在动作模型
- 关键创新:
- 自视角重建(Self-viewpoint reconstruction):对每个视角 v,使用 latent action $z_t^v$ 预测同一视角的下一帧观测 $o_{t+1}^v$
- 跨视角重建(Cross-viewpoint reconstruction):跨视角交换 latent tokens(例如 $z_t^{v_1} \leftrightarrow z_t^{v_2}$),用另一视角的 latent action 预测当前视角的未来观测,鼓励 latent action 捕获固有的过渡信息
- 训练目标:$\mathcal{L}_{\text{MVP-LAM}} = \mathcal{L}_{\text{self}} + \mathcal{L}_{\text{cross}} + \mathcal{L}_{\text{quant}} + \mathcal{L}_{\text{commit}}$
- 特征提取:使用冻结的 DINOv2 提取视觉特征,时序 stride 设为 H
数据集与资源
- 训练数据集:Open X-Embodiment(OXE)多视角机器人轨迹 + EgoExo4D 多视角人类操作视频,共 312k 轨迹,训练 160k 步
- 评估数据集:
- Bridge V2:用于动作中心性评估和互信息估计
- SIMPLER:4个任务(StackG2Y、Carrot2Plate、Spoon2Towel、Eggplant2Bask),7-DoF WidowX 机械臂
- LIBERO-Long:10个长程操作任务
- 模型规模:Prismatic-7B VLM,DINOv2 特征提取器,codebook 大小 32k tokens
- VLA 预训练:使用交叉熵(CE)目标预测 MVP-LAM 产生的离散 latent action token
评估与结果
- 评估指标:互信息(MI)估计(KSG、BA、MINE)、线性探测归一化均方误差(NMSE)、成功率(Success Rate)、抓取率(Grasping Rate)
- 关键实验结果:
- 互信息:MVP-LAM 在所有估计器上达到最高 $\mathcal{I}(Z;A)$,显著高于 UniVLA、LAPA、Moto 基线
- 线性探测:MVP-LAM 在 Bridge V2(分布内)和 LIBERO(分布外)上实现最低 NMSE
- SIMPLER 基准:MVP-LAM 平均成功率 60.4%,显著高于 UniVLA(39.6%),抓取率 75.0%
- LIBERO-Long 基准:MVP-LAM 达到 90.8% 成功率,优于 UniVLA Bridge(79.4%)和 OpenVLA(53.7%)
- 视角扰动评估:MVP-LAM 在扰动后保持最低重建误差和最高动作中心性
- 消融实验:移除 $\mathcal{L}_{\text{cross}}$ 导致 MI 从 1.10 降至 0.27,NMSE 从 0.73 升至 0.96,证明跨视角重建目标的关键作用