一眼看懂
封面预览
论文针对 Vision-Language-Action (VLA) 模型在开放世界环境中的终身学习问题,提出了 CRL-VLA 框架。
- 论文针对 Vision-Language-Action (VLA) 模型在开放世界环境中的终身学习问题,提出了 CRL-VLA 框架。
- 研究旨在解决持续强化学习中的关键挑战:在获取新技能(可塑性)与保留旧技能(稳定性)之间取得平衡,防止灾难性遗忘。
- 核心思想是将稳定性-可塑性困境重新定义为一种非对称调节问题,通过控制目标条件优势幅度来实现权衡。
Card 01
研究单位
研究单位
- Qixin Zeng, Shuo Zhang, Hongyin Zhang, Renjie Wang, Han Zhao, Libang Zhao, Runze Li, Donglin Wang, Chao Huang(注:原文 HTML 片段中未明确列出作者所属具体机构名称)
Card 02
论文概述
论文概述
- 论文针对 Vision-Language-Action (VLA) 模型在开放世界环境中的终身学习问题,提出了 CRL-VLA 框架。
- 研究旨在解决持续强化学习中的关键挑战:在获取新技能(可塑性)与保留旧技能(稳定性)之间取得平衡,防止灾难性遗忘。
- 核心思想是将稳定性-可塑性困境重新定义为一种非对称调节问题,通过控制目标条件优势幅度来实现权衡。
Card 03
核心贡献
核心贡献
- 提出了 CRL-VLA 框架,这是首个针对 VLA 模型的持续性后训练框架,具有严格的理论界限。
- 发现并证明了 目标条件优势幅度 是决定稳定性-可塑性权衡的关键量,并推导出了统一的性能界限。
- 设计了带有 目标条件价值公式 (GCVF) 的双评论家架构,通过冻结评论家和可训练评论家实现非对称调节。
Card 04
方法描述
方法描述
- 基于理论推导(定理 4.1),建立了性能变化与优势幅度 ($M$) 及策略散度 ($D$) 之间的联系。
- 提出了 双评论家架构:一个冻结的 GCV 评论家 用于锚定旧任务的价值语义以保持稳定性,一个可训练的 MC 评论家 用于新任务的自适应学习。
- 引入了 目标条件价值公式 (GCVF),将语言嵌入与状态表征拼接,增强模型对语言目标的跟随能力。
- 提出了一套综合训练目标,包含 PPO 损失、KL 正则化、GCV 一致性损失 和 MC 评论家损失,以拉格朗日松弛法实现约束优化。
Card 05
数据集与资源
数据集与资源
- 使用了 LIBERO 基准测试集,通过从共享任务池中随机采样任务构建持续学习场景。
- 基础模型使用了 OpenVLA-OFT 模型进行微调和评估。
- 训练资源信息(如 GPU 型号和数量)在提供的原文片段中未明确提及。
Card 06
评估与结果
评估与结果
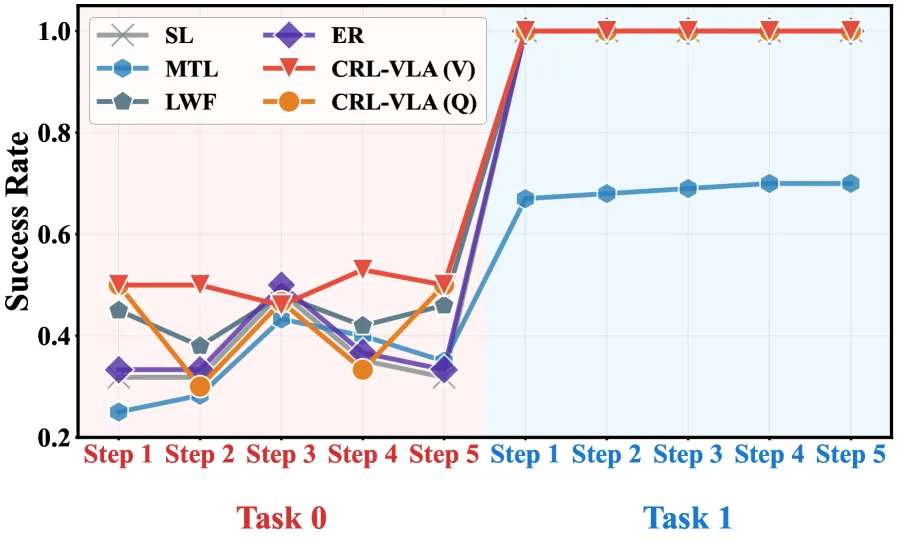
- 评估环境包括单任务学习场景和多任务学习场景,对比了 SL, LwF, ER, MTL 等基线方法。
- 主要评估指标包括 最终平均回报 (FAR)、后向迁移 (BWT)(衡量遗忘程度)和 前向迁移(衡量可塑性)。
- 实验结果表明,CRL-VLA 在抗遗忘和前向适应方面均优于基线算法,有效协调了稳定性与可塑性的冲突。