一眼看懂
封面预览
论文提出了 RDT2,一个基于 7B 参数视觉-语言模型(VLM)的机器人基础模型,旨在实现零样本跨硬件平台(cross-embodiment…
- 论文提出了 RDT2,一个基于 7B 参数视觉-语言模型(VLM)的机器人基础模型,旨在实现零样本跨硬件平台(cross-embodiment…
- 研究的核心目标是解决当前视觉-语言-动作模型面临的数据稀缺、架构效率低以及无法泛化到不同硬件平台的关键问题。
- 论文通过重新设计硬件并收集大规模数据,探索数据与模型规模缩放对于提升机器人泛化能力的影响。
Card 01
研究单位
研究单位
- 论文原文未明确列出作者所属的研究机构。
Card 02
论文概述
论文概述
- 论文提出了 RDT2,一个基于 7B 参数视觉-语言模型(VLM)的机器人基础模型,旨在实现零样本跨硬件平台(cross-embodiment)的开放词汇任务部署。
- 研究的核心目标是解决当前视觉-语言-动作模型面临的数据稀缺、架构效率低以及无法泛化到不同硬件平台的关键问题。
- 论文通过重新设计硬件并收集大规模数据,探索数据与模型规模缩放对于提升机器人泛化能力的影响。
Card 03
核心贡献
核心贡献
- 构建了目前最大的开源机器人数据集之一,包含超过 10,000 小时的通用操作接口(UMI)演示数据。
- 提出了 RDT2 模型及其三阶段训练流程,有效结合了离散与连续动作表示的优势,并实现了实时推理。
- 重新设计了 UMI 硬件,提升了数据采集的可靠性、精度和多样性,为大规模数据收集奠定基础。
- 实验证明 RDT2 在零样本任务中能泛化到未见过的物体、场景、指令乃至机器人本体,并在复杂下游任务中超越了现有基线模型。
Card 04
方法描述
方法描述
- 模型训练采用三阶段流程:第一阶段使用残差矢量量化将连续动作离散化为 Token,并预训练 VLM 主干网络;第二阶段冻结 VLM 主干,训练一个基于流匹配的扩散动作专家以生成连续动作;第三阶段通过蒸馏将多步扩散模型转化为单步生成器,大幅提升推理速度。
- 关键创新在于将离散语言知识与连续控制通过 RVQ 和扩散模型相结合,并利用在线蒸馏策略避免策略过拟合。
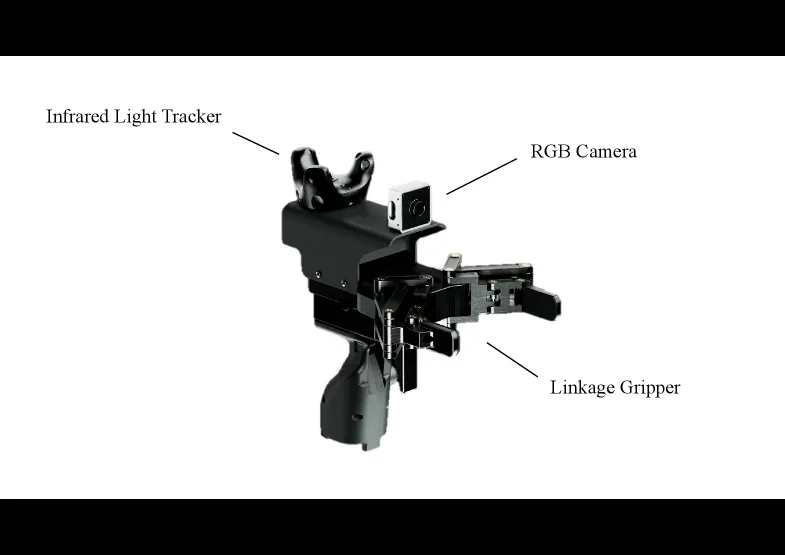
- 硬件方面,通过采用 CNC 加工的高强度材料、红外光追踪系统以及连杆式抓手,重新设计了 UMI,解决了原始方案在可靠性、追踪精度和操作灵巧性上的不足。
Card 05
数据集与资源
数据集与资源
- 使用自建的大规模 UMI 数据集,包含超过 10,000 小时的操作演示,覆盖超过 100 个家庭环境。
- 模型主干为 7B 参数的 Qwen2.5-VL,动作专家模块参数量约为 400M。
- 训练资源方面未在原文摘要中明确说明具体使用 GPU/TPU 数量,但提及模型进行了大规模迭代训练。
Card 06
评估与结果
评估与结果
- 评估环境包括零样本测试场景(未见过的物体、场景、指令和本体)、缩放律实验以及针对复杂真实世界任务的微调实验。
- 主要评估指标包括任务成功率、进度得分以及动作生成频率等。
- 零样本实验结果显示,RDT2 能够完成基础开放词汇任务,证明了其组合泛化能力。微调实验表明,在衣物折叠、收桌、拉拉链和打乒乓球等具有挑战性的任务中,RDT2 在成功率和反应速度上均显著优于 π0-FAST 和 π0.5 等先进基线模型。消融实验验证了所提出训练策略各部分的有效性。