一眼看懂
封面预览
论文针对在高度复杂动态环境(如3D开放世界、大规模PvP游戏)中,现有 视觉-语言-行动 (VLA) 模型难以从冗余传感器流中高效提取关键决策…
- 论文针对在高度复杂动态环境(如3D开放世界、大规模PvP游戏)中,现有 视觉-语言-行动 (VLA) 模型难以从冗余传感器流中高效提取关键决策…
- 提出了 MAIN-VLA 框架,通过显式建模 意图抽象 和 环境语义抽象,使决策基于深度语义对齐,而非表面的模式匹配。
- 核心目标是将冗长的指令和复杂的视觉流过滤、对齐为稀疏、可执行的原语,从而提升在复杂动态环境中的决策质量、泛化能力和推理效率。
Card 01
研究单位
研究单位
- 作者所属机构在原文HTML中未明确标注。
Card 02
论文概述
论文概述
- 论文针对在高度复杂动态环境(如3D开放世界、大规模PvP游戏)中,现有 视觉-语言-行动 (VLA) 模型难以从冗余传感器流中高效提取关键决策信号的问题。
- 提出了 MAIN-VLA 框架,通过显式建模 意图抽象 和 环境语义抽象,使决策基于深度语义对齐,而非表面的模式匹配。
- 核心目标是将冗长的指令和复杂的视觉流过滤、对齐为稀疏、可执行的原语,从而提升在复杂动态环境中的决策质量、泛化能力和推理效率。
Card 03
核心贡献
核心贡献
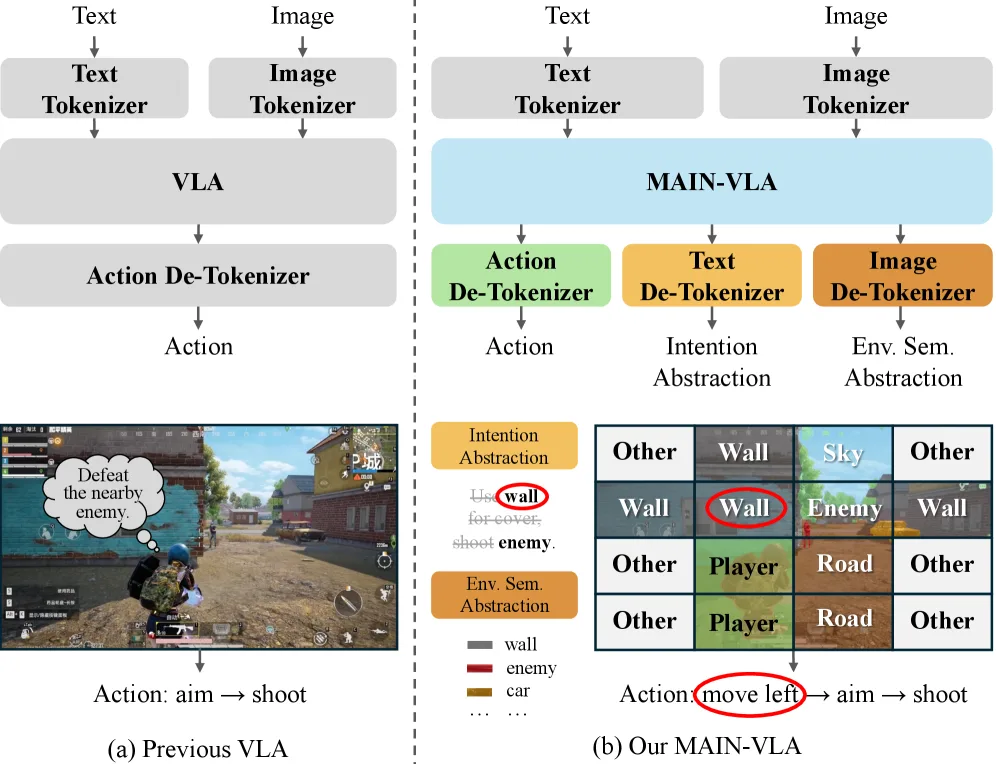
- 提出了 MAIN-VLA 框架,该框架通过双路径抽象机制(IA和ESA),模仿人脑的“意识瓶颈”,将决策建立在深度语义对齐之上。
- 设计了 意图抽象 (IA) 模块,将冗长的指令和推理过程压缩为紧凑、明确的语义原语,使智能体能理解潜在的战略意图,而非依赖短语匹配。
- 设计了 环境语义抽象 (ESA) 模块,将高维视觉流投影为结构化的、稀疏的拓扑功能表示(如语义地图),优先编码任务关键的 affordance,舍弃无关的纹理细节。
- 框架自然涌现出参数无关的 令牌修剪 能力,能在推理时过滤感知冗余,实现实时推理速度且性能损失可忽略。
Card 04
方法描述
方法描述
- 采用统一因果 Transformer 作为骨干网络,通过在动作令牌之后放置抽象令牌来实现“事后监督”,迫使模型在执行动作前的隐藏状态中嵌入推理逻辑。
- 意图抽象 (IA) 通过专家模型自动生成意图关键词序列作为训练目标,并通过“事后意图对齐”目标函数迫使模型内部表征包含充足的语义信息以恢复意图。
- 环境语义抽象 (ESA) 使用开放词汇分割模型生成语义地图,并通过基于战术优先级的语义池化策略下采样为低分辨率语义网格,最后将其标记化为序列令牌进行自回归重建。
- 涌现令牌修剪 基于注意力集中效应,计算每个视觉令牌的连通性得分,在推理时仅保留top-k个高分令牌,以过滤背景噪声。
Card 05
数据集与资源
数据集与资源
- 使用 Minecraft (MCU基准,超800个任务) 、 Game for Peace (和平精英,6项原子任务) 和 Valorant (战术射击基准) 作为评估环境。
- 基础模型为 Qwen2-VL-7B,在不同环境分别使用约50小时和200小时的游玩数据进行微调。
- 训练分布在 8个 NVIDIA H20 GPU 上,推理在 单个 NVIDIA L40S GPU 上进行评估。
Card 06
评估与结果
评估与结果
- 在 Minecraft 所有任务类别(Embodied, Combat, GUI)上,MAIN-VLA 在成功率和执行步数上均达到 SOTA,尤其在战斗任务中成功率领先近10%。
- 在 Game for Peace 基准上,MAIN-VLA 平均成功率达 67.9%,推理延迟仅 0.3秒,显著优于GPT-4o等专有模型和开源VLA基线。
- 消融实验证实,IA 和 ESA 模块对性能提升均有关键贡献,且模型在启用了涌现令牌修剪后仍能保持高性能。
- 模型在 零样本泛化 和对抗视觉干扰的鲁棒性测试中表现出色,证明了其学习到的语义表示具有较好的泛化能力。