一眼看懂
封面预览
针对 Vision-Language-Action (VLA) 模型中现有的 Chain-of-Thought (CoT) 方法存在的推理开销…
- 针对 Vision-Language-Action (VLA) 模型中现有的 Chain-of-Thought (CoT) 方法存在的推理开销…
- 核心目标是将多模态 CoT 推理内化为连续的潜在表示,在潜在空间中统一进行推理和预测,从而消除推理时的显式 CoT 生成。
- 该方法旨在实现高效、以行动为导向的控制,使其适用于实时机器人操作任务。
Card 01
研究单位
研究单位
- 论文作者包括 Shuanghao Bai, Jing Lyu, Wanqi Zhou, Zhe Li, Dakai Wang, Lei Xing, Xiaoguang Zhao, Pengwei Wang, Zhongyuan Wang, Cheng Chi, Badong Chen, Shanghang Zhang(注:提供的 HTML 原文中未明确列出作者所属的具体研究机构)。
Card 02
论文概述
论文概述
- 针对 Vision-Language-Action (VLA) 模型中现有的 Chain-of-Thought (CoT) 方法存在的推理开销高以及离散表示与连续控制不匹配的问题,提出了 LaRA-VLA 框架。
- 核心目标是将多模态 CoT 推理内化为连续的潜在表示,在潜在空间中统一进行推理和预测,从而消除推理时的显式 CoT 生成。
- 该方法旨在实现高效、以行动为导向的控制,使其适用于实时机器人操作任务。
Card 03
核心贡献
核心贡献
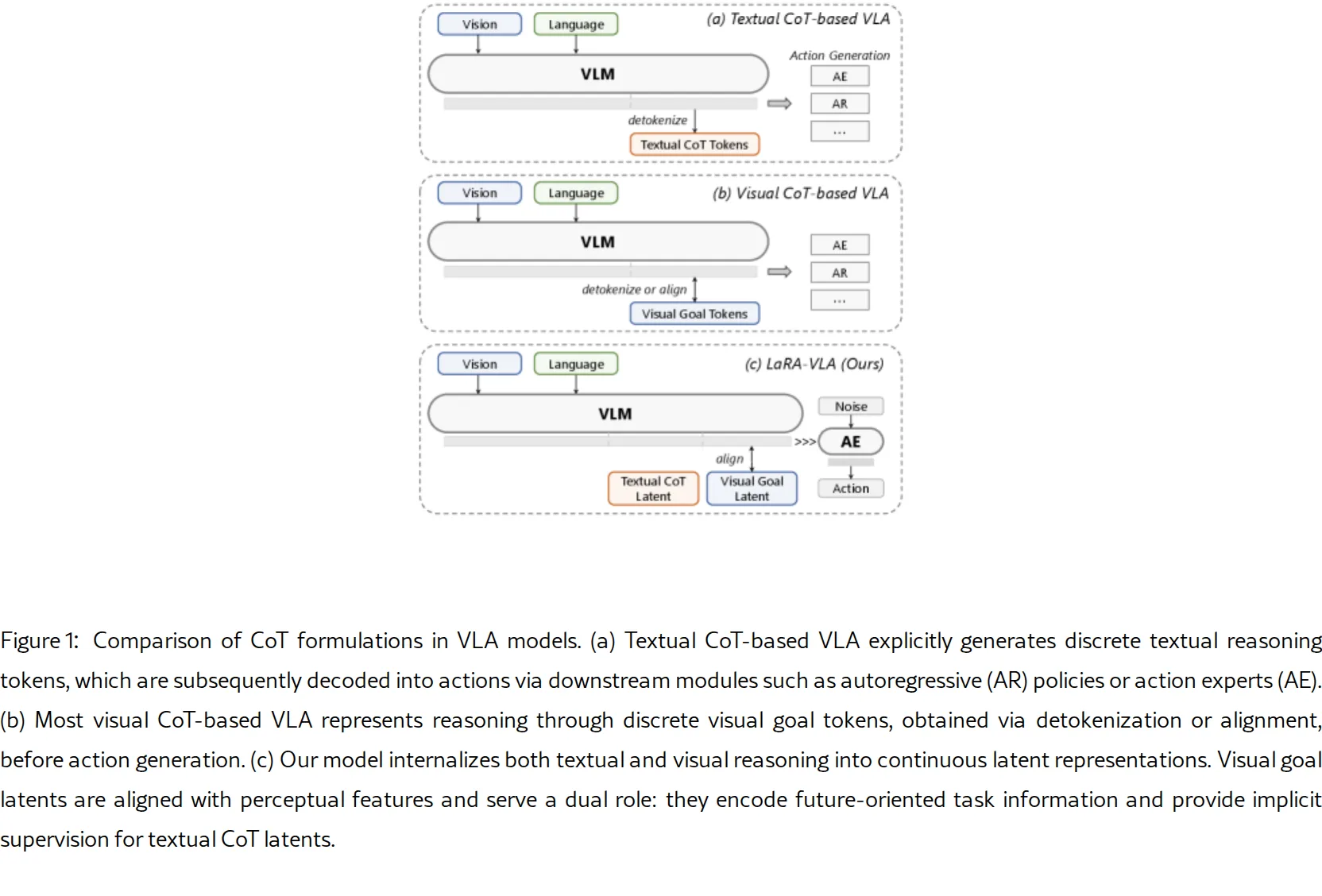
- 提出了一种用于 VLA 模型的 潜在推理范式,将思维链推理内化为跨文本和视觉模态的连续潜在表示,实现了与连续感知和控制一致的推理。
- 设计了 LaRA-VLA 模型,通过基于课程的训练策略,逐步从显式多模态 CoT 监督过渡到潜在具身推理,并利用 EMA 编码器稳定潜在表示学习。
- 构建了两个结构化的思维链数据集 LIBERO-LaRA 和 Bridge-LaRA,提供了具身操作的多模态推理注释。
- 在仿真基准和长视程真实机器人任务上进行了广泛评估,证明了该方法的有效性和鲁棒性。
Card 04
方法描述
方法描述
- 模型架构基于 Qwen3-VL,引入了
标记用于预测未来视觉潜在表示,并使用 16 层 Diffusion Transformer 作为动作专家生成连续动作轨迹。 - 采用三阶段训练流程:阶段 I 进行显式 CoT 微调(包括文本 CoT 和未来视觉预测);阶段 II 通过课程策略逐步用潜在表示替换离散 CoT 标记;阶段 III 通过流匹配目标适应动作生成。
- 引入了 LaRA 注意力机制,显式调节文本、当前图像、未来图像和动作标记之间的信息流,支持从自回归动作生成到潜在条件生成的过渡。
- 为了稳定视觉潜在学习,采用了 指数移动平均 (EMA) 编码器作为目标网络,防止表示坍塌。
Card 05
数据集与资源
数据集与资源
- 仿真数据集:LIBERO-LaRA(基于 LIBERO 基准构建)、Bridge-LaRA(基于 SimplerEnv 基准构建)。
- 真实世界数据集:在 Agilex Cobot Magic 平台上收集的长视程机器人操作数据,包含四个任务类别,每类 100 条轨迹。
- 训练与推理资源:实验在 NVIDIA A100 GPU 上进行推理效率测试。
Card 06
评估与结果
评估与结果
- 评估基准:在 LIBERO(Spatial, Goal, Object, Long 任务套件)和 SimplerEnv-WindowX 上进行仿真评估,并在真实世界长视程任务中进行测试。
- 对比方法:与 OpenVLA, $\pi_{0}$, ThinkAct, CoT-VLA, DreamVLA 等多种先进 VLA 方法进行对比。
- 主要结果:LaRA-VLA 在 LIBERO 上取得了 97.9% 的平均成功率,在 SimplerEnv 上取得了 68.8% 的平均成功率,均达到最优水平。
- 效率表现:与显式 CoT 方法相比,推理延迟降低了高达 90%,实现了高效的实时控制。