一眼看懂
封面预览
论文针对 Vision-Language-Action (VLA) 模型在真实世界部署中对传感器级图像损坏(如噪声、坏点、水滴)缺乏鲁棒性的问…
- 论文针对 Vision-Language-Action (VLA) 模型在真实世界部署中对传感器级图像损坏(如噪声、坏点、水滴)缺乏鲁棒性的问…
- 指出现有文献主要关注物理遮挡,而忽视了直接影响视觉信号完整性的图像损坏问题,导致模型性能出现灾难性下降。
- 提出了一种即插即用的修复模块,旨在无需微调底层模型的情况下恢复受损的视觉输入,提升 VLA 模型的鲁棒性。
Card 01
研究单位
研究单位
- Daniel Yezid Guarnizo Orjuela, Leonardo Scappatura, Veronica Di Gennaro
- Riccardo Andrea Izzo, Gianluca Bardaro, Matteo Matteucci
- 作者所属机构为 AIRLab-POLIMI (Artificial Intelligence and Robotics Laboratory, Politecnico di Milano),依据文中提供的 Hugging Face 链接推断。
Card 02
论文概述
论文概述
- 论文针对 Vision-Language-Action (VLA) 模型在真实世界部署中对传感器级图像损坏(如噪声、坏点、水滴)缺乏鲁棒性的问题进行研究。
- 指出现有文献主要关注物理遮挡,而忽视了直接影响视觉信号完整性的图像损坏问题,导致模型性能出现灾难性下降。
- 提出了一种即插即用的修复模块,旨在无需微调底层模型的情况下恢复受损的视觉输入,提升 VLA 模型的鲁棒性。
Card 03
核心贡献
核心贡献
- 量化分析了最先进的 VLA 模型(如 $\pi_{0.5}$ 和 SmolVLA)在多种图像损坏场景下的性能退化程度。
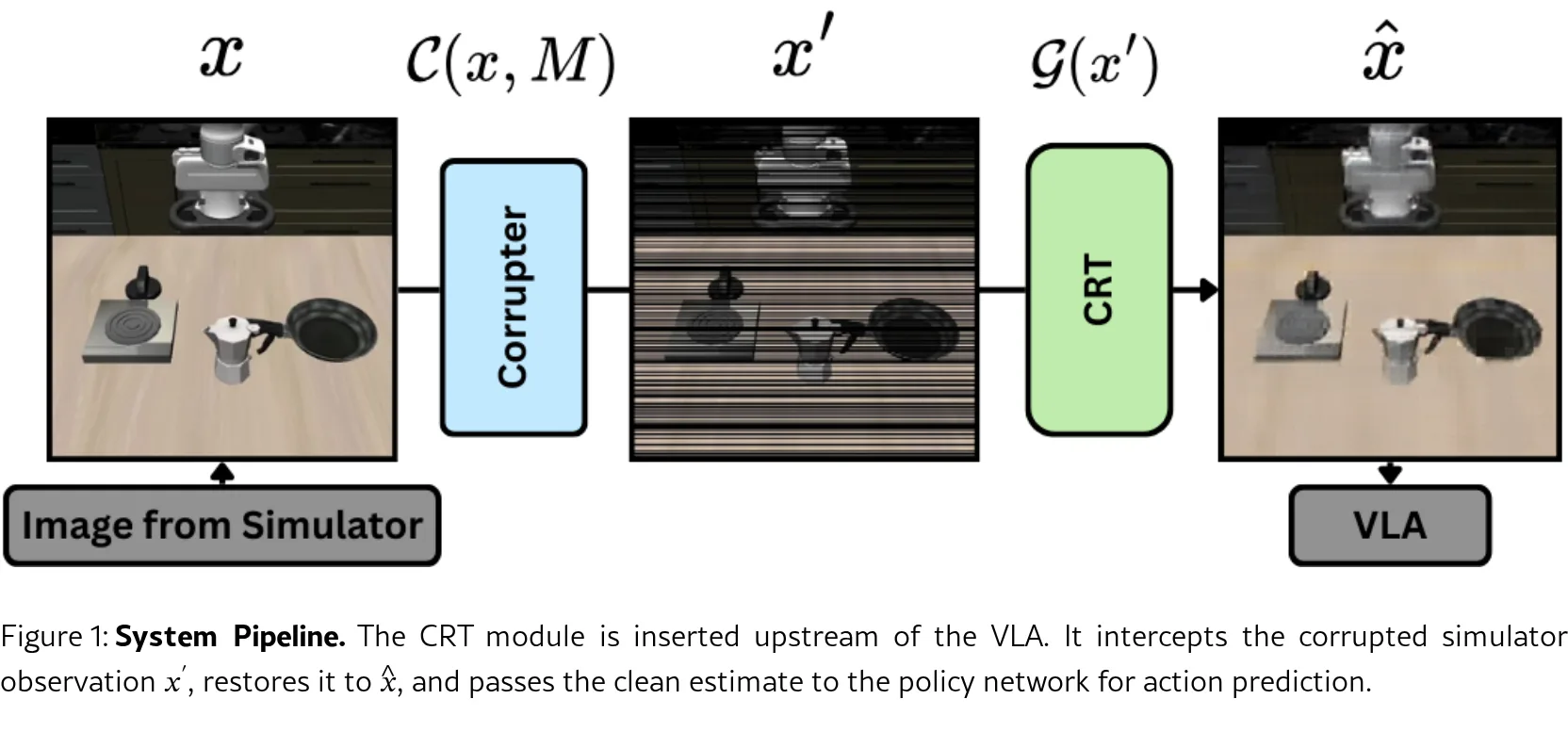
- 提出了 Corruption Restoration Transformer (CRT),这是一个轻量级、模型无关的模块,用于在视觉输入进入策略网络前恢复其清晰度。
- 采用对抗训练目标,结合 L1、SSIM 和对抗损失,有效重建受损图像的高频细节。
- 开源了代码、模型和数据集,促进了该领域的可复现性研究。
Card 04
方法描述
方法描述
- 设计了 Corruption Restoration Transformer (CRT) 作为 VLA 流程上游的修复模块。
- 架构基于增强型 Vision Transformer,引入了 Shifted Patch Tokenization (SPT) 以保留空间关系,Rotary Position Embeddings (RoPE) 用于位置编码,以及 Locality Self-Attention (LSA) 以聚焦局部纹理。
- 扩展了基础架构的深度和容量,以适应机器人操作任务中高分辨率(最高 480x480)图像的处理需求。
- 训练策略采用生成对抗网络 (GAN) 框架,通过多目标损失函数优化,从受损输入中重建干净的观测图像。
Card 05
数据集与资源
数据集与资源
- 使用 LIBERO-10 和 Meta-World MT50 基准数据集进行实验。
- 构建了包含 48,660 张图像对的训练数据集(干净图像与受损图像对)。
- 评估模型包括 SmolVLA 和 $\pi_{0.5}$。
- 训练硬件使用单块 NVIDIA RTX Quadro 6000 GPU。
- 训练时间根据基准不同约为 1.3 天至 3 天。
Card 06
评估与结果
评估与结果
- 评估环境为 LIBERO 和 Meta-World 模拟器,测试了中心方块遮挡、高斯噪声、水平条纹和水滴等五种图像损坏类型。
- 主要评估指标为平均成功率。
- 实验结果显示 VLA 模型在严重损坏下性能急剧下降(例如 $\pi_{0.5}$ 成功率从 90% 降至 2%)。
- 集成 CRT 后,模型性能显著恢复,例如 $\pi_{0.5}$ 在严重水平条纹干扰下成功率回升至 87%,接近基线水平。
- CRT 模块推理开销极小(10-50ms,约 1GB 显存),证明了其作为轻量级解决方案的有效性。