一眼看懂
封面预览
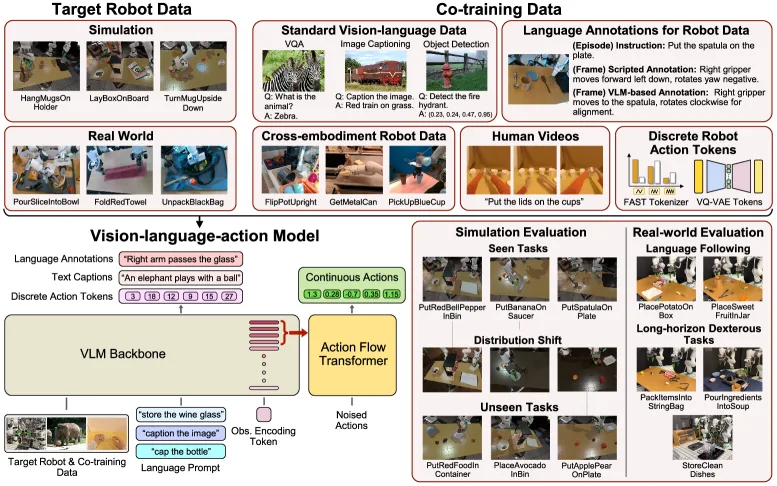
研究如何通过协同训练(co-training)策略,利用异构数据模态来提升大型行为模型(LBMs)在机器人操作任务中的泛化能力
- 研究如何通过协同训练(co-training)策略,利用异构数据模态来提升大型行为模型(LBMs)在机器人操作任务中的泛化能力
- 系统性地评估了五种协同训练数据模态:标准视觉语言数据、机器人轨迹的密集语言注释、跨本体机器人数据、人类视频、以及离散机器人动作 tokens
- 解决了机器人数据不足的问题,通过联合学习目标机器人数据和其他异构数据来扩展模型对物理世界的理解
Card 01
研究单位
研究单位
- Toyota Research Institute (TRI) - 所有作者均隶属于该机构
Card 02
论文概述
论文概述
- 研究如何通过协同训练(co-training)策略,利用异构数据模态来提升大型行为模型(LBMs)在机器人操作任务中的泛化能力
- 系统性地评估了五种协同训练数据模态:标准视觉语言数据、机器人轨迹的密集语言注释、跨本体机器人数据、人类视频、以及离散机器人动作 tokens
- 解决了机器人数据不足的问题,通过联合学习目标机器人数据和其他异构数据来扩展模型对物理世界的理解
Card 03
核心贡献
核心贡献
- 首次大规模系统性地研究不同协同训练数据模态和训练策略对策略性能的影响
- 评估了 89 个 VLA 策略,在模拟环境中完成 58,000 次 rollout,在真实环境中完成 2,835 次 rollout
- 发现标准视觉语言数据和跨本体机器人数据能显著提升对分布偏移、未见任务和语言跟随的泛化能力
- 证明组合有效的协同训练模态可产生累积性能提升,并支持对未见的长程灵巧操作任务的快速适应
- 发现仅在机器人数据上训练会损害 VLM 主干的视觉语言理解能力,而协同训练可恢复此能力
Card 04
方法描述
方法描述
- 采用 VLA(Vision-Language-Action)架构,由预训练的 VLM 主干(PaliGemma2-PT)和 Action Flow Transformer(ActionFT) 动作头组成
- 使用 Flow Matching 预测连续机器人动作,使用 Cross-Entropy Loss 处理离散 tokens
- 探索三种训练策略:单阶段协同训练、两阶段仅第一阶段协同训练、两阶段完整协同训练
- 动作 chunk 预测范围为 16 步
Card 05
数据集与资源
数据集与资源
- TRI-Ramen:523 小时机器人操作数据,403 个任务,53,411 个演示(478 小时真实世界 + 45 小时模拟)
- OXE-Ramen:1,150 小时跨本体机器人数据,12 种机器人设置,924 个任务
- 人类视频:2,271 小时 egocentric 视频(Ego4D、EgoDex、Something-Something V2 等)
- 标准视觉语言数据:约 50M 样本(RoboPoint 1.3M、RefSpatial 2.5M 等)
- 模型规模:约 3B 参数(PaliGemma2-3b-pt-224)
Card 06
评估与结果
评估与结果
- 模拟基准:13 个 seen 任务 + 8 个 unseen 任务, nominal 和 distribution shift 条件
- 真实世界评估:语言跟随(seen objects、instruction generalization、unseen objects)+ 长程灵巧操作任务
- 最终模型结果:
- 模拟 unseen 任务:72.6% 成功率(相比 baseline 提升 36.4%)
- 真实世界语言跟随:69.4% 平均任务完成率(相比 baseline 提升 45.3%)
- 长程灵巧任务微调:90.2% 平均任务完成率(200 个演示)
- 关键发现:标准 VL 数据、VLM 生成的机器人数据注释和人类视频注释最有价值;离散动作 tokens(FAST、VQ-VAE)无统计显著提升