一眼看懂
封面预览
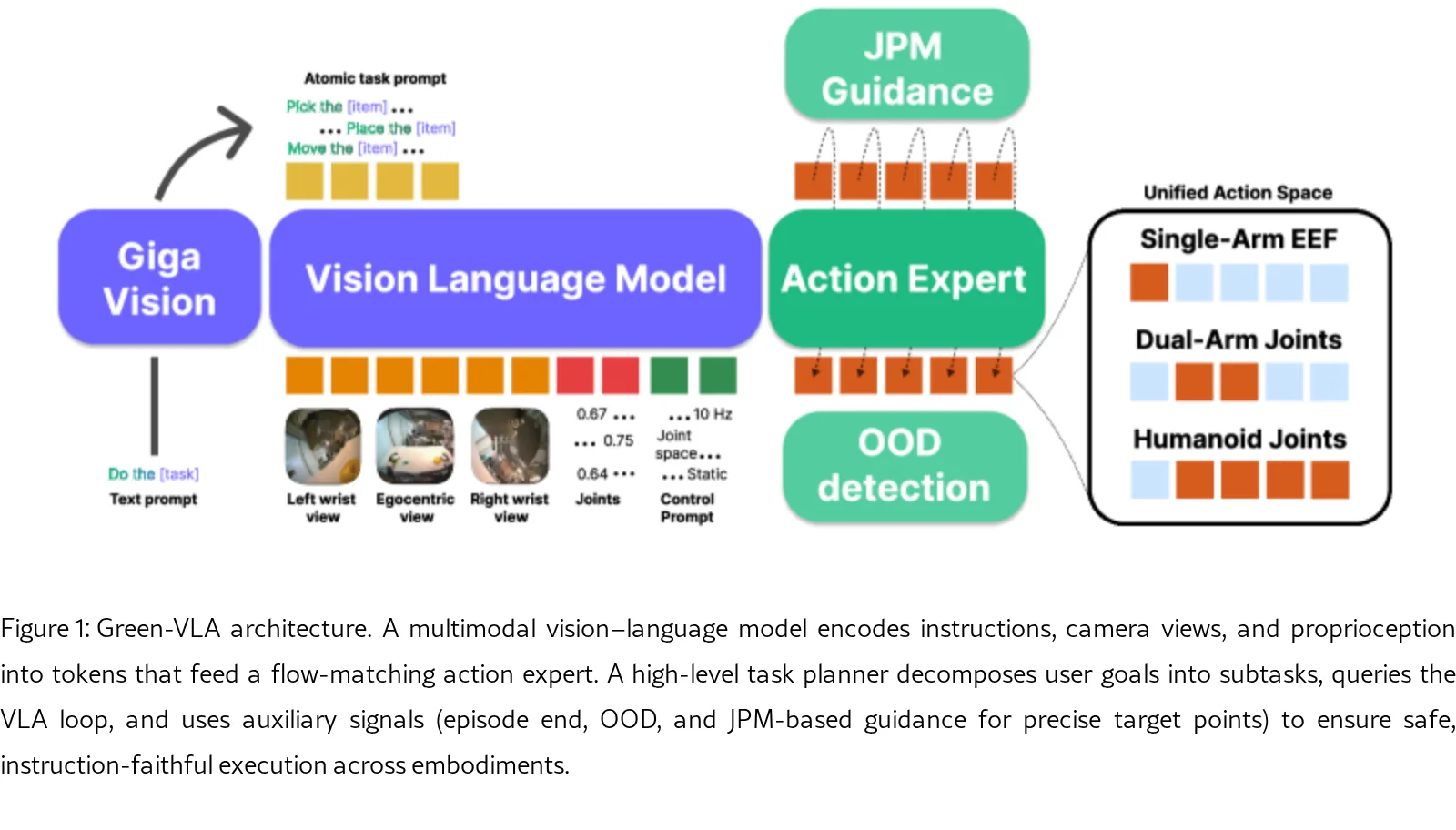
提出了 Green-VLA,一个分阶段的 Vision-Language-Action 框架,用于在 Green 人形机器人上进行真实世界部署…
- 提出了 Green-VLA,一个分阶段的 Vision-Language-Action 框架,用于在 Green 人形机器人上进行真实世界部署…
- 论文采用五阶段课程学习:L0(基础 VLM)→ L1(多模态预训练)→ R0(多形态预训练)→ R1(形态特定微调)→ R2(RL 对齐),从…
- 核心目标是解决现有 VLA 模型在真实世界部署中的三大挑战:数据异质性、数据质量差异、以及行为克隆在长程任务中的局限性
Card 01
研究单位
研究单位
- Sber Robotics Center( Manipulation Team)
Card 02
论文概述
论文概述
- 提出了 Green-VLA,一个分阶段的 Vision-Language-Action 框架,用于在 Green 人形机器人上进行真实世界部署,同时保持对不同形态机器人(humanoids、mobile manipulators、fixed-base arms)的泛化能力
- 论文采用五阶段课程学习:L0(基础 VLM)→ L1(多模态预训练)→ R0(多形态预训练)→ R1(形态特定微调)→ R2(RL 对齐),从网络规模多模态数据逐步迁移到真实机器人部署
- 核心目标是解决现有 VLA 模型在真实世界部署中的三大挑战:数据异质性、数据质量差异、以及行为克隆在长程任务中的局限性
Card 03
核心贡献
核心贡献
- DataQA 数据质量保证模块:提出基于抖动 (J)、清晰度 (S)、多样性 (D)、状态方差 (σ²) 的轨迹质量评估与过滤pipeline,结合轨迹平滑和光流速度对齐,确保数据规模与质量并重
- 分阶段 VLA 训练配方:提供从通用多模态预训练到真实机器人部署的清晰路径(L0→L1→R0→R1→R2),各阶段解决不同瓶颈
- 统一动作空间设计:提出 64 维统一语义布局 A_u,通过显式映射 Φ_e 和二元掩码 m_e 实现多形态控制,避免naive padding导致的跨形态负迁移
- 联合预测与引导模块 (JPM):通过 2D 指向机制预测目标点,结合伪逆引导 (ΠGDM) 改进精确目标定位,尤其适用于电子商务货架等视觉密集场景
- RL 对齐阶段 (R2):将行为克隆与强化学习目标结合,提升长程任务成功率、鲁棒性和恢复能力
Card 04
方法描述
方法描述
- 架构:基于统一 Transformer 的架构,视觉-语言编码器融合 RGB 观测、本体感受状态和自然语言指令,流匹配动作专家预测统一动作块,使用 SDPA 高效注意力核和轻量级头实现低延迟部署
- 任务规划器:基于 GigaVision VLM 的高级规划器,将用户高级目标(如"set the table for lunch")分解为原子子任务序列,预测剧集进度并判断子任务完成状态
- 统一动作空间:将异构机器人动作空间(关节空间、笛卡尔空间、夹爪等)映射到 64 维统一空间,使用语义布局保持物理含义一致性,支持动态形态和控制类型提示
- 动作对齐:使用光流幅度估计执行速度,通过单调三次样条插值/重采样标准化动作时间尺度,引入速度因子 v 进行条件调制以支持长短程控制
- OOD 检测器:基于高斯混合模型 (GMM) 的在线分布外检测,预测动作导致低密度状态时进行梯度修正
- R2 RL 微调:结合行为克隆先验与 RL 对齐,使用轨迹优化和源分布改进提升策略稳定性
Card 05
数据集与资源
数据集与资源
- L1 预训练数据:2400 万非机器人互联网规模多模态样本(包括 RefSpatial、AgiBotWorld、RoboPoint、ShareRobot、Robo2VLM、PixMo-Points、MS COCO、A-OKVQA、OpenSpaces、Sun RGB-D)
- R0 机器人数据:1.84 亿样本,超过 3000 小时,涵盖多种形态数据集
- Humanoid:AgiBotWorld_twofinger (774h)、ActionNet (143h)、Robomind (33h)、AgiBot dexhand (82h)、Green Humanoid 167h
- ALOHA:Galaxea (477h)、BiPlay (31h)、RDT (59h)、ALOHA any_pick (11.2h)
- 单臂:DROID (501h)、Fractal (351h)、Bridge (105h)
- 数据增强:对 Green Humanoid 数据通过左右镜像和时间反转扩展到 167 训练小时
- 模型规模:使用流匹配动作专家,支持 32 DoF 全身控制(头部、躯干、双臂、灵巧手)
Card 06
评估与结果
评估与结果
- 评估环境:在 Green 人形机器人上部署,支持双手机器人、单臂 manipulator 和多种形态
- 主要评估指标:成功率 (SR)、平均链长 (ACL)、剧集完成效率
- 关键实验结果:
- R0 阶段:与此前预训练模型相当或更优
- R1 阶段:形态微调后与其他 VLA 模型竞争力相当
- R2 阶段:最大提升,尤其在长程成功率、恢复能力和精确任务跟随方面
- 部署设计:支持 Green 人形机器人统一上半身控制(手臂、手、头、躯干),同时兼容其他形态和标准模拟器