一眼看懂
封面预览
研究 Vision-Language-Action (VLA) 模型中的 "错误完成"(False Completion) 失败模式,即策略过…
- 研究 Vision-Language-Action (VLA) 模型中的 "错误完成"(False Completion) 失败模式,即策略过…
- 识别问题根源为 模态不平衡(modality imbalance):模型过度依赖内部本体感觉状态而忽视视觉证据,导致"状态主导偏见(state…
- 提出 ReViP 框架,通过 视觉-本体感觉再平衡(Vision-Proprioception Rebalance) 增强视觉接地和在扰动下的…
Card 01
研究单位
研究单位
- 中山大学,中国
- 深圳循环区域研究所,中国
- 北京理工大学,中国
- 鹏城实验室,深圳,中国
- 机器智能与高级计算教育部重点实验室,中国
- 广东省信息安全技术重点实验室,中国
Card 02
论文概述
论文概述
- 研究 Vision-Language-Action (VLA) 模型中的 "错误完成"(False Completion) 失败模式,即策略过早终止或宣布成功,尽管目标尚未达成
- 识别问题根源为 模态不平衡(modality imbalance):模型过度依赖内部本体感觉状态而忽视视觉证据,导致"状态主导偏见(state-dominant bias)"
- 提出 ReViP 框架,通过 视觉-本体感觉再平衡(Vision-Proprioception Rebalance) 增强视觉接地和在扰动下的鲁棒性
Card 03
核心贡献
核心贡献
- 识别并系统研究 VLA 模型中的 错误完成 失败模式,揭示其由模态不平衡导致的状态主导偏见
- 构建首个 False-Completion Benchmark Suite,包含 8 个任务和三种受控扰动(Object Drop、Distractor Swap、Relayout)
- 提出 ReViP 框架,包含 Task-Stage Observer 用于提取进度感知的视觉线索,以及 Task-Stage Enhancer 通过 TS-FiLM 进行特征级模态再平衡
- 在 LIBERO、RoboTwin 2.0 和真实世界实验中取得 SOTA 性能,比 π₀ 模型提升 26%
Card 04
方法描述
方法描述
- Task-Stage Observer (TSO):使用外部 VLM(如 Qwen2.5-VL)对当前观察和指令进行任务相关推理,提取进度感知的视觉线索,反映任务进度和环境状态
- Task-Stage Enhancer (TSE):将 TSO 提取的线索通过 Vision-Proprioception Feature-wise Linear Modulation (TS-FiLM) 注入策略,自适应地平衡语义感知和本体感觉动态
- 动作预测采用 Flow Matching 方法,基于调制的特征预测动作块
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO(空间、目标、目标、长程)、RoboTwin 2.0(双臂)、自建的 False-Completion Benchmark
- 骨干模型:π₀ (pi_0)
- TSO 模型:Qwen2.5-VL-3B(ReViP)、Qwen2.5-VL-72B(ReViP*)
- 训练资源:8×H100 GPUs (80GB),batch size 32,60k 训练步
Card 06
评估与结果
评估与结果
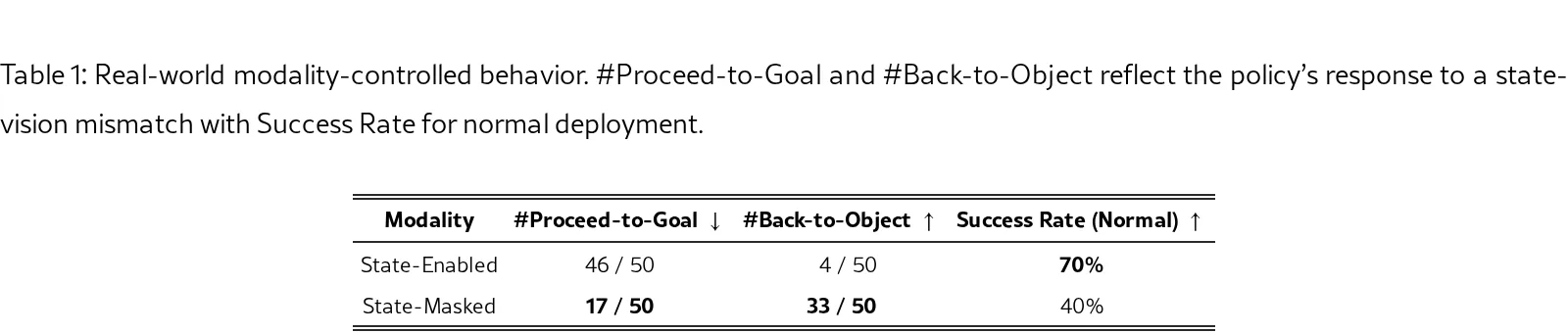
- False-Completion Benchmark:ReViP 达到 59% 成功率,ReViP* 达到 62%,比 π₀-Fast(44%)高 18%,比 π₀(36%)高 26%
- LIBERO:ReViP 平均 95.9% 成功率,ReViP* 达到 96.7%(最高),超越 π₀ 的 94.2%
- RoboTwin 2.0(双臂):ReViP 平均 21% 成功率,显著领先 RDT 和 π₀
- 在 Object Drop、Distractor Swap、Relayout 三种扰动下均有效缓解错误完成