一眼看懂
封面预览
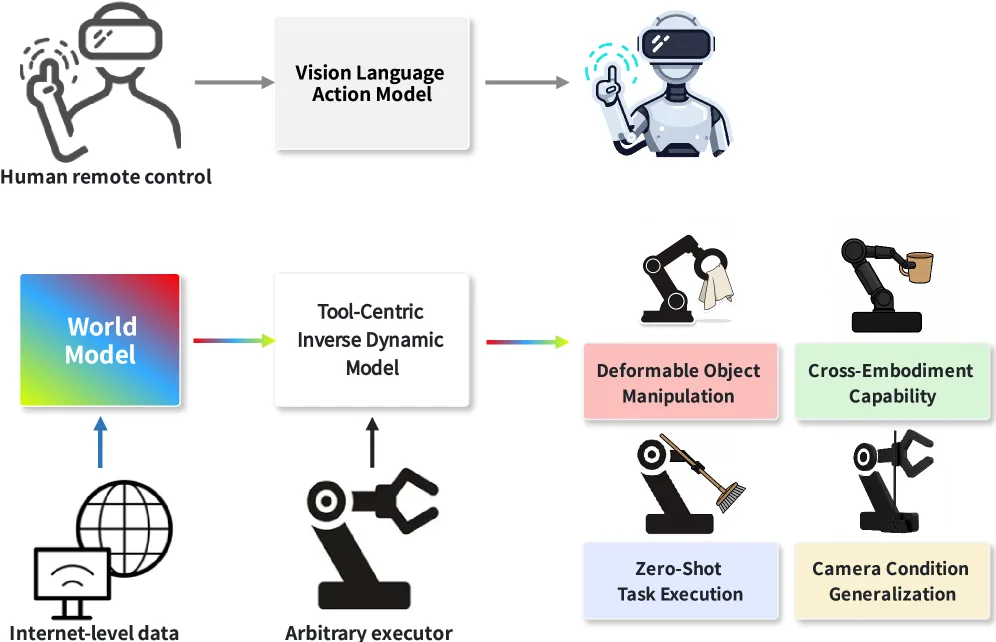
研究旨在解决生成式世界模型(world models)的像素级视觉规划与物理可执行机器人动作之间的"最后一英里"差距
- 研究旨在解决生成式世界模型(world models)的像素级视觉规划与物理可执行机器人动作之间的"最后一英里"差距
- 提出 TC-IDM(Tool-Centric Inverse Dynamics Model),以工具/夹爪的轨迹作为中间表示,连接高层视觉规划…
- 采用"计划-翻译"(plan-and-translate)范式,支持多种末端执行器和零样本泛化
Card 01
研究单位
研究单位
- 北京的人形机器人创新中心(Beijing Innovation Center of Humanoid Robotics)
- 北京大学计算机学院多媒体信息处理国家重点实验室(State Key Laboratory of Multimedia Information Processing, School of Computer Science, Peking University)
- 香港科技大学(Hong Kong University of Science and Technology)
Card 02
论文概述
论文概述
- 研究旨在解决生成式世界模型(world models)的像素级视觉规划与物理可执行机器人动作之间的"最后一英里"差距
- 提出 TC-IDM(Tool-Centric Inverse Dynamics Model),以工具/夹爪的轨迹作为中间表示,连接高层视觉规划与低层物理控制
- 采用"计划-翻译"(plan-and-translate)范式,支持多种末端执行器和零样本泛化
Card 03
核心贡献
核心贡献
- 提出 TC-IDM 框架,利用工具轨迹作为关键中间表示,桥接世界模型规划与机器人控制
- 通过分离的臂部和工具策略头,分别利用物理运动线索和语义视觉特征,有效解耦并利用异构信息流
- 进行了全面的真实世界实验,验证了方法的有效性,并建立了生成式世界模型在物理机器人上部署的新基准
Card 04
方法描述
方法描述
- 时空预测:使用世界模型生成 RGB 视频序列,采用 VGGT 生成深度图和相机位姿,通过尺度和平移对齐获得度量深度
- 解耦动作翻译:
- 视觉驱动状态生成:使用 DINOv3 提取语义特征,通过 Gripper MLP Head 预测 1-DoF 夹爪控制信号
- 几何接地姿态生成:使用 SAM 3 生成夹爪掩码,利用 3D 点跟踪器(SpatialTrackerv2)提取密集轨迹,通过刚体对齐恢复 6-DoF 末端执行器动作
Card 05
数据集与资源
数据集与资源
- 测试的世界模型:WoW、CogVideo、Cosmos-1、Wan2.1、Hailuo、Kling、Cosmos2
- 相机:Intel RealSense D457(训练)、Apple Pro、Realsense D435i(泛化测试)
- 机器人平台:Franka(单臂)、UR(双臂)
- 灵巧手:BrainCo、Inspire-Robots
Card 06
评估与结果
评估与结果
- 平均成功率:61.11%
- 简单任务:77.7%(Easy tasks)
- 零样本可变形物体任务:38.46%
- 在多种难度任务上显著优于端到端 VLA 基线和其他逆动力学模型(IDMs)
- 泛化实验涵盖:误差范围分析、相机视角变化、可变形物体、长视野任务、跨 embodiment 迁移