一眼看懂
封面预览
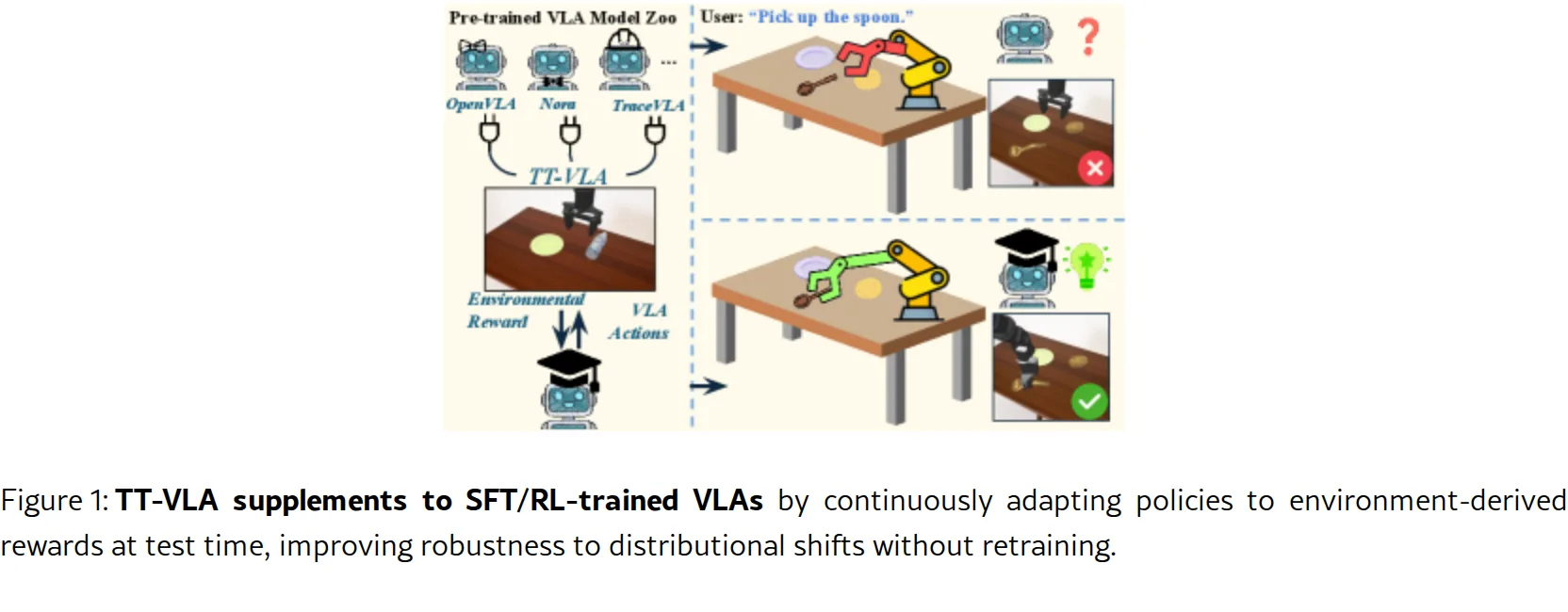
提出 TT-VLA(Test-Time Reinforcement Learning for VLAs) 框架,解决视觉-语言-动作(VLA)…
- 提出 TT-VLA(Test-Time Reinforcement Learning for VLAs) 框架,解决视觉-语言-动作(VLA)…
- 针对现有 VLA 模型主要通过监督微调(SFT)或训练时强化学习(RL)预训练,部署后策略固定、无法应对分布偏移的局限,提出测试时强化学习方法
- 采用密集的进度奖励机制,利用任务进度信号在推理过程中持续优化策略,保持 SFT/RL 预训练 priors 的同时实现自适应能力
Card 01
研究单位
研究单位
- University of Missouri–Kansas City(密苏里大学堪萨斯城分校)
- Hong Kong University of Science and Technology (Guangzhou)(香港科技大学(广州))
- U. S. Naval Research Laboratory(美国海军研究实验室)
- Lamar University(拉马尔大学)
- Meta AI
- Rochester Institute of Technology(罗切斯特理工学院)
Card 02
论文概述
论文概述
- 提出 TT-VLA(Test-Time Reinforcement Learning for VLAs) 框架,解决视觉-语言-动作(VLA)模型在部署后无法自适应动态环境的问题,实现推理阶段的在线策略微调
- 针对现有 VLA 模型主要通过监督微调(SFT)或训练时强化学习(RL)预训练,部署后策略固定、无法应对分布偏移的局限,提出测试时强化学习方法
- 采用密集的进度奖励机制,利用任务进度信号在推理过程中持续优化策略,保持 SFT/RL 预训练 priors 的同时实现自适应能力
Card 03
核心贡献
核心贡献
- 提出 TT-VLA 框架,首个针对 VLA 的测试时强化学习方法,支持在单 episode 内进行在线策略自适应,无需重训练
- 设计 密集进度奖励机制,使用 VLAC(Vision-Language-Action-Critic)模型估计任务进度 p_t,奖励定义为 r_t = p_t - p_{t-1},提供逐步骤反馈
- 提出 无值函数 PPO 变体,设置 γ=0 和 λ=0,将 GAE 简化为一步形式 Â_t = r_t,避免在单 episode 内学习值函数
- 提供 理论分析,证明标准 GAE 在进度差分奖励下会退化为零(Proposition 1),并导出Corollary 1 展示负偏差问题
- 在多种 VLA backbone(Nora、OpenVLA、OpenVLA-RL、TraceVLA)上验证方法有效性,显著提升任务成功率
Card 04
方法描述
方法描述
- 问题建模:将机器人操作建模为部分可观察马尔可夫决策过程(POMDP),VLA 策略接收视觉观测和语言指令,输出动作序列
- 密集进度奖励:使用预训练的 VLAC 模型作为进度估计器 Φ,计算任务进度 p_t = Φ(o_{0:t+1}, l}),奖励 r_t = p_t - p_{t-1}
- 无值函数 PPO:移除价值函数学习(c₁=0, c₂=0),仅保留裁剪的代理目标 L(θ) = E[L^{CLIP}_t(θ)],设置 λ=0 和 γ=0 使优势估计简化为即时奖励
- 推理流程:每个时间步执行动作后,计算进度和奖励,更新策略参数 θ,然后使用更新后的策略生成后续动作
Card 05
数据集与资源
数据集与资源
- VLA backbone:Nora、OpenVLA、OpenVLA-RL、TraceVLA
- 进度估计器:VLAC(Vision-Language-Action-Critic)预训练模型
- 实验环境:模拟环境(BridgeData V2、LIBERO 等)和真实机器人平台
- 测试场景:目标位置变化、机器人姿态变化、物体替换、视觉干扰(纹理、噪声)等分布偏移条件
Card 06
评估与结果
评估与结果
- 评估指标:任务成功率(%)
- 模拟环境结果:TT-VLA 在多种 VLA backbone 上持续提升性能,如 Nora 平均提升 14.85%(相对增益),OpenVLA 平均提升 9.54%
- 真实机器人结果:在未见过的任务和环境下,TT-VLA 显著增强 VLA 的适应性和稳定性
- 关键发现:TT-VLA 对不同 VLA 架构均有效,包括经过 RL 微调的模型(如 OpenVLA-RL),验证其作为现有 SFT/RL 方法的有效补充