一眼看懂
封面预览
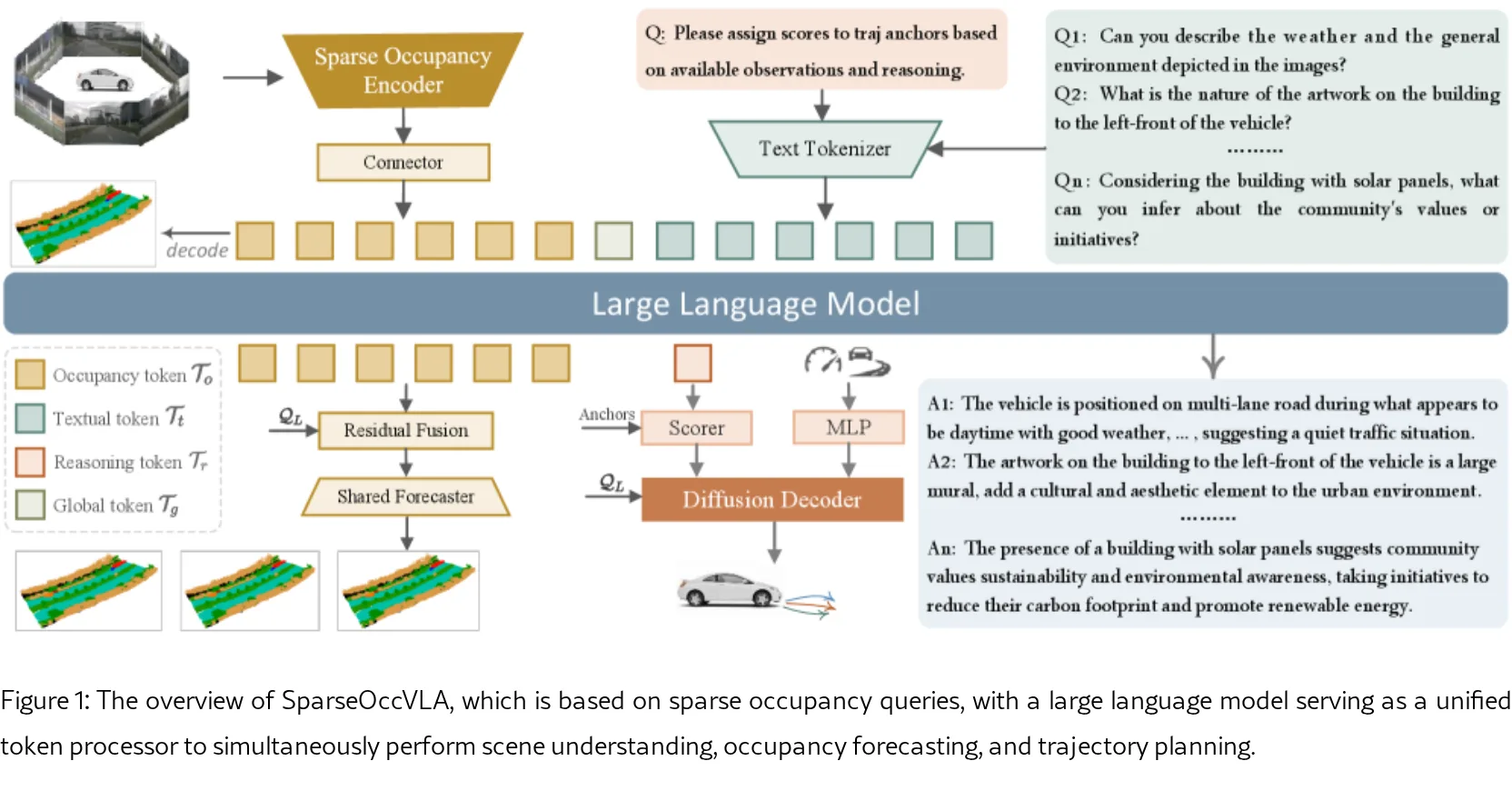
提出 SparseOccVLA,首个真正面向occupancy的端到端VLA模型,统一实现场景理解、occupancy预测和轨迹规划
- 提出 SparseOccVLA,首个真正面向occupancy的端到端VLA模型,统一实现场景理解、occupancy预测和轨迹规划
- 解决视觉语言模型(VLM)与语义occupancy之间的gap:传统VLM存在token爆炸和时空推理受限问题,而occupancy表示过于稠…
- 核心思路:利用稀疏occupancy查询作为视觉与语言之间的桥梁,生成紧凑且信息丰富的token表示
Card 01
研究单位
研究单位
- 华中科技大学 (Huazhong University of Science and Technology)
- 小米汽车 (Xiaomi EV)
- 清华大学 AIR 研究院 (Institute for AI Industry Research (AIR), Tsinghua University)
Card 02
论文概述
论文概述
- 提出 SparseOccVLA,首个真正面向occupancy的端到端VLA模型,统一实现场景理解、occupancy预测和轨迹规划
- 解决视觉语言模型(VLM)与语义occupancy之间的gap:传统VLM存在token爆炸和时空推理受限问题,而occupancy表示过于稠密难以与VLM高效融合
- 核心思路:利用稀疏occupancy查询作为视觉与语言之间的桥梁,生成紧凑且信息丰富的token表示
Card 03
核心贡献
核心贡献
- 首次提出真正面向occupancy的端到端VLA模型,统一理解、预测和规划三大任务
- 设计稀疏occupancy编码器,生成仅几百个稀疏查询即可有效连接occupancy表示与场景理解,性能远超传统视觉-语言连接器
- 提出LLM引导的锚点扩散规划器,解耦锚点评分与去噪,同时发挥LLM决策能力和扩散模型回归能力的优势
- 在场景理解、occupancy预测和规划任务上均取得SOTA性能
Card 04
方法描述
方法描述
- 稀疏Occupancy编码器:可学习查询嵌入与多尺度图像特征交互,生成紧凑的occupancy查询(仅几百个),通过特征级蒸馏和全局查询机制促进跨模态对齐
- 统一大语言模型:将occupancy tokens与文本tokens结合输入LLM进行统一理解和未来occupancy预测;引入残差融合机制合并LLM推理后的tokens与原始occupancy查询
- LLM引导的锚点扩散规划器:LLM为轨迹锚点分配高层评分,扩散解码器实现跨模态轨迹-条件融合和噪声预测;解耦锚点评分与去噪过程
Card 05
数据集与资源
数据集与资源
- 数据集:nuScenes、OmniDrive-nuScenes(场景理解)、Occ3D-nuScenes(occupancy预测)
- 模型规模:
- 图像编码器:ResNet-50 + CLIP-336(蒸馏)
- LLM:Vicuna-7B(32层,token维度4096)
- Occupancy查询数:600(可减少至300仍保持良好性能)
- 全局查询数:12
- 锚点轨迹数:18
- 训练资源:8张NVIDIA H20 GPU,总batch size 16,三阶段训练(36+6+12 epochs)
Card 06
评估与结果
评估与结果
- 场景理解:CIDEr达到0.796(600查询)/0.795(300查询),相比HERMES提升7%
- Occupancy预测:平均mIoU 13.71,相比SparseWorld提升0.51
- 轨迹规划:nuScenes上建立新的SOTA开环规划性能,L2误差和碰撞率均优于所有竞争对手
- 消融实验验证:occupancy监督、位置编码、全局查询、残差融合机制、蒸馏损失和LLM引导规划均对最终性能有显著贡献