一眼看懂
封面预览
LaST0 是一种用于机器人操作的视觉-语言-动作(VLA)模型,通过潜在时空思维链(LaST CoT) 实现高效的"先推理后行动"(reas…
- LaST0 是一种用于机器人操作的视觉-语言-动作(VLA)模型,通过潜在时空思维链(LaST CoT) 实现高效的"先推理后行动"(reas…
- 旨在解决显式思维链(explicit CoT)VLA 方法面临的两大核心挑战:推理延迟高和语言空间的表征瓶颈——难以准确捕捉难以言喻的物理属性
- 通过在紧凑的潜在空间中进行推理,捕获细粒度的物理和机器人动力学信息,同时支持时间一致建模
Card 01
研究单位
研究单位
- 北京大学(多媒体信息处理国家重点实验室,计算机科学学院)
- 北京人形机器人创新中心
- 香港中文大学(CUHK)
- Simplexity Robotics
Card 02
论文概述
论文概述
- LaST0 是一种用于机器人操作的视觉-语言-动作(VLA)模型,通过潜在时空思维链(LaST CoT) 实现高效的"先推理后行动"(reason-before-act)行为范式
- 旨在解决显式思维链(explicit CoT)VLA 方法面临的两大核心挑战:推理延迟高和语言空间的表征瓶颈——难以准确捕捉难以言喻的物理属性
- 通过在紧凑的潜在空间中进行推理,捕获细粒度的物理和机器人动力学信息,同时支持时间一致建模
Card 03
核心贡献
核心贡献
- 提出LaST0统一VLA模型,利用潜在时空思维链在紧凑潜在空间中执行推理,捕获难以用语言描述的细粒度物理和机器人动态特性
- 设计时空潜在CoT空间,可自回归建模未来语义、几何和本体感觉信息,使模型能够以时间一致的方式进行物理动态推理
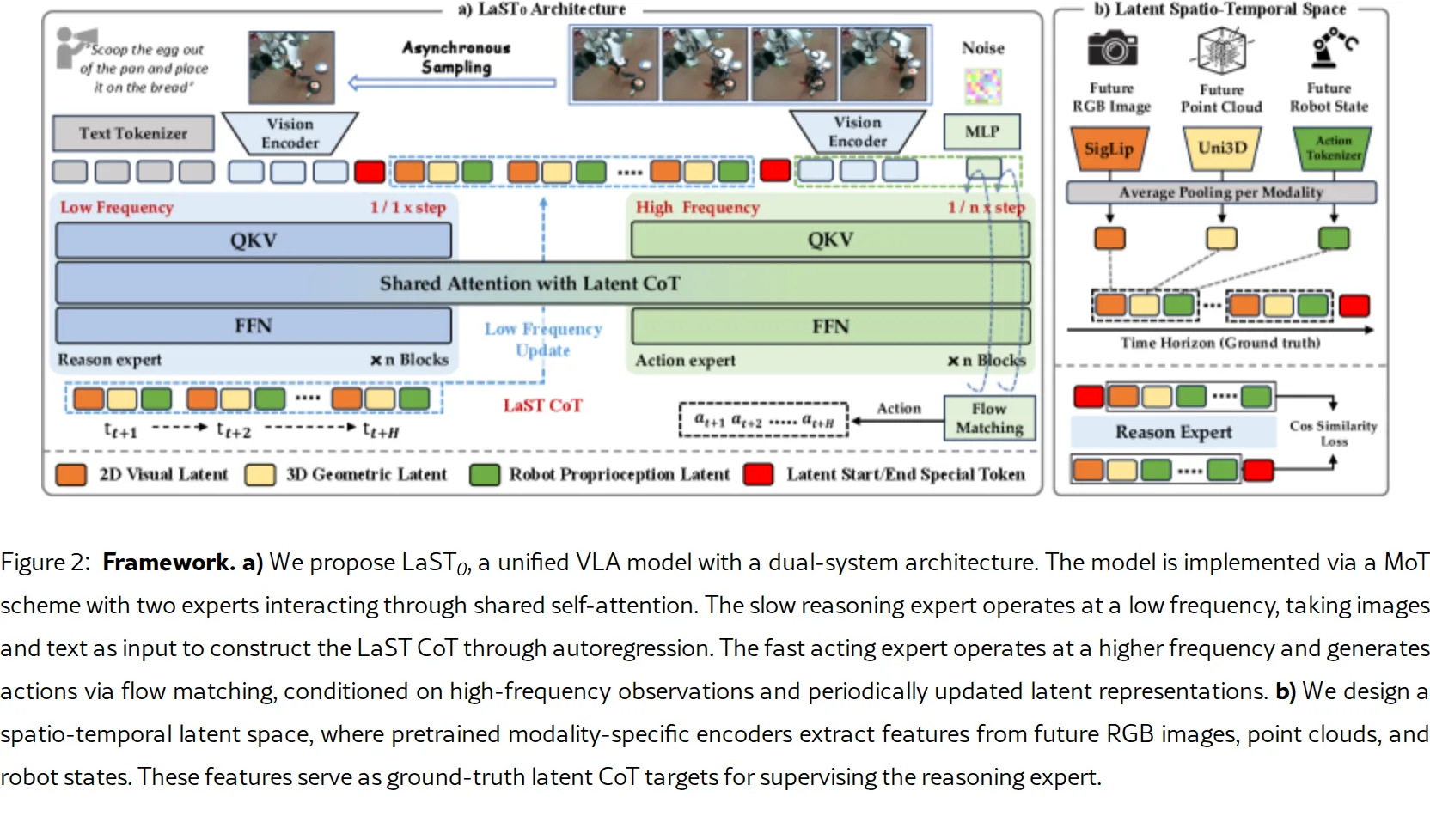
- 引入双系统VLA架构(通过MoT混合Transformer实现),协调低频潜在推理与高频动作生成,实现实时机器人操作
- 构建多模态潜在嵌入(融合2D图像、3D点云和机器人本体状态),通过共享自注意力机制实现潜在CoT空间与动作空间的长期上下文交互
Card 04
方法描述
方法描述
- 潜在CoT构建:使用预训练的SigLIP-Large编码器提取未来RGB帧特征,Uni3D编码器提取3D点云几何特征,通过动作tokenizer处理机器人状态;应用平均池化压缩为单一token表示
- 双系统架构:慢速推理专家(slow reasoning expert)以低频运行,进行潜在推理捕获时空依赖性;快速动作专家(fast acting expert)以高频运行,基于周期性更新的潜在表示生成动作
- 异步频率协调:采用更新比率κ控制两专家协作频率(如1:1、1:2、1:4),推理时使用1:4比率
- 训练策略:从Janus-Pro初始化,在大规模机器人操作数据集上预训练;联合优化潜在回归损失和Flow Matching动作损失;训练时混合不同快慢操作频率
Card 05
数据集与资源
数据集与资源
- 预训练数据:Open-X-Embodiment、DROID、ROBOMIND等数据集,超过40万条机器人操作轨迹
- 评估基准:RLBench仿真环境(10个任务),10个真实世界任务涵盖桌面单/双臂、移动操作和灵巧手操作
- 模型规模:基于DeepSeek-LLM 1.5B backbone(Janus-Pro初始化)
- 训练硬件:8块NVIDIA A800 GPU
- 推理硬件:NVIDIA 4090 GPU
Card 06
评估与结果
评估与结果
- 仿真实验(RLBench):LaST0平均成功率达82%,超越最强基线HybridVLA-7B(74%)8个百分点;推理速度15.4 Hz,比CoT-VLA(1.1 Hz)快约14倍
- 真实世界实验:在Franka平台上平均成功率72%,较SpatialVLA(41%)提升31个百分点,较π₀.₅(59%)提升13个百分点,较CoT-VLA(50%)提升22个百分点
- 移动操作和灵巧手任务:在AgileX移动操作和TienKung灵巧手任务中分别提升14%和14%
- 消融实验:验证了三种模态(图像、点云、机器人状态)的必要性、每模态单token足够、扩展时间覆盖可提升性能、混合训练策略可增强鲁棒性