一眼看懂
封面预览
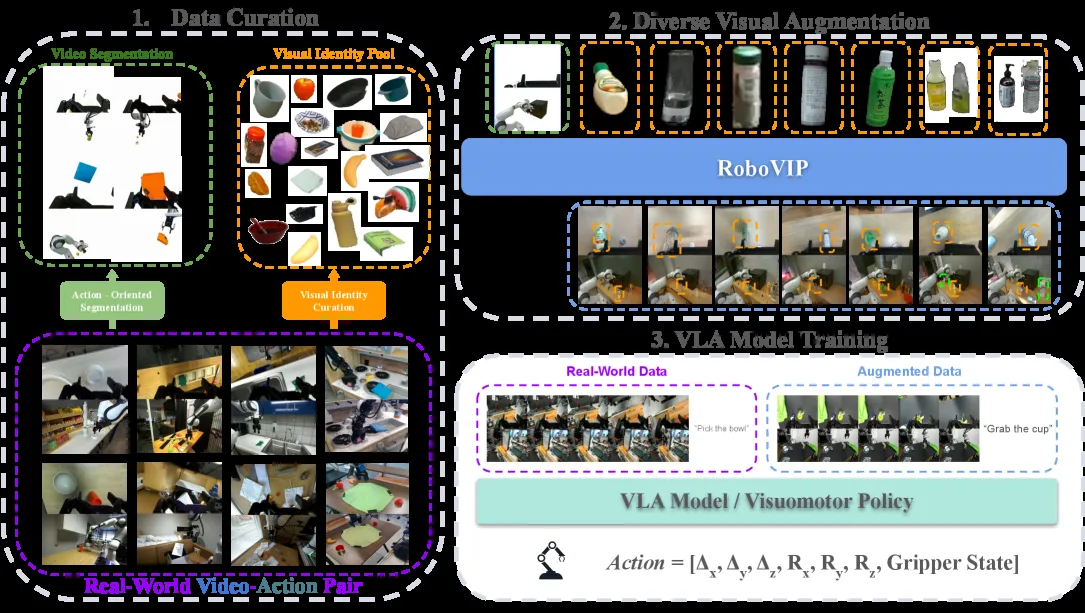
论文提出 RoboVIP,一个多视角视频生成增强框架,通过视觉身份提示(Visual Identity Prompting)来扩充机器人操作数据
- 论文提出 RoboVIP,一个多视角视频生成增强框架,通过视觉身份提示(Visual Identity Prompting)来扩充机器人操作数据
- 解决现有数据增强方法无法生成多视角、时间一致观察结果的问题;解决仅依赖文本提示无法准确指定场景设置的问题
- 核心创新在于使用示例图像作为条件输入,引导生成符合语义和低层次一致性的内容,而非仅依赖文本描述
Card 01
研究单位
研究单位
- Shanghai AI Laboratory(上海人工智能实验室)
- Tsinghua University(清华大学)
- Shanghai Jiao Tong University(上海交通大学)
- University of Michigan(密歇根大学)
Card 02
论文概述
论文概述
- 论文提出 RoboVIP,一个多视角视频生成增强框架,通过视觉身份提示(Visual Identity Prompting)来扩充机器人操作数据
- 解决现有数据增强方法无法生成多视角、时间一致观察结果的问题;解决仅依赖文本提示无法准确指定场景设置的问题
- 核心创新在于使用示例图像作为条件输入,引导生成符合语义和低层次一致性的内容,而非仅依赖文本描述
Card 03
核心贡献
核心贡献
- 提出多视角视频级别增强框架,支持动态移动手腕相机视图的生成
- 设计动作引导分割管道,利用夹爪状态信息定位交互对象时间窗口
- 构建百万规模的自动化视觉身份提示池,通过全景分割和多重过滤筛选
- 提出视觉身份提示方法,将示例图像作为条件输入引导视频扩散模型
- 在模拟环境和真实机器人上验证了方法对 VLA 模型(Octo、π₀)和视觉运动策略(Diffusion Policy)的性能提升
Card 04
方法描述
方法描述
- 基础模型:基于 Wan2.1 14B 参数的图视频扩散模型
- 微调策略:采用 LoRA(Low-Rank Adaptation)进行高效微调
- 多视角处理:使用结构化垂直拼接策略,将不同视角的帧在同一时间戳进行通道级拼接
- 分割管道:结合动作信息(夹爪状态变化)定位交互对象,使用 Cosmos-Reason1 VLM 推理对象语义,SAM2 进行视频分割跟踪
- 视觉身份提示:通过全景分割从大规模数据集中提取对象图像,经过质量筛选后构建提示池,推理时将多个身份图像打包编码后注入扩散过程
Card 05
数据集与资源
数据集与资源
- 训练数据:Bridge V1/V2 数据集、Droid 数据集
- 增强数据量:12K BridgeV2 轨迹用于 VLA 模型训练
- 下游策略模型:Octo-base(多帧条件策略)、π₀(单帧 VLA 策略)、Diffusion Policy(视觉运动策略)
- 训练资源:8 GPU,每 GPU 144GB 显存,有效批量大小 32
Card 06
评估与结果
评估与结果
- 仿真环境:SimplerEnv,4 个操作任务(Put spoon on towel、Put carrot on plate、Stack green cube on yellow cube、Put eggplant in basket)
- 评估指标:任务成功率、Grasp 成功率、条件 Put 成功率(Put = Success/Grasp)
- 主要结果:
- 视频生成质量:RoboVIP 达到 FID=39.97,FVD=138.4,MV-Mat.=2242.1(最优)
- Octo + RoboVIP (Text+ID):平均成功率 18.5%,Put 成功率 41.1%
- π₀ + RoboVIP (Text-only):平均成功率 29.0%,Put 成功率 55.0%
- 真实机器人实验:DP + RoboVIP 在 clutter 环境下达到 9/10 成功率(基线为 0/10)
- 关键发现:视觉身份提示和视频级生成对多帧条件策略尤为重要;RoboVIP 在 6 帧历史条件下仍保持性能,而基线方法性能降为 0