一眼看懂
封面预览
论文重新审视了Vision-Language-Action (VLA) 模型中基础Vision-Language Model (VLM)的选择…
- 论文重新审视了Vision-Language-Action (VLA) 模型中基础Vision-Language Model (VLM)的选择…
- 提出了 VLM4VLA 框架,这是一个最小化的适配管道,仅引入不到1%的新参数即可将通用VLM转换为VLA策略
- 通过在三个基准测试(Calvin、SimplerEnv、Libero)上的大规模实证研究,揭示了VLM能力与VLA性能之间存在显著差距
Card 01
研究单位
研究单位
- 清华大学交叉信息研究院
- 阿里云通义千问团队
Card 02
论文概述
论文概述
- 论文重新审视了Vision-Language-Action (VLA) 模型中基础Vision-Language Model (VLM)的选择和能力如何影响下游VLA策略的性能
- 提出了 VLM4VLA 框架,这是一个最小化的适配管道,仅引入不到1%的新参数即可将通用VLM转换为VLA策略
- 通过在三个基准测试(Calvin、SimplerEnv、Libero)上的大规模实证研究,揭示了VLM能力与VLA性能之间存在显著差距
Card 03
核心贡献
核心贡献
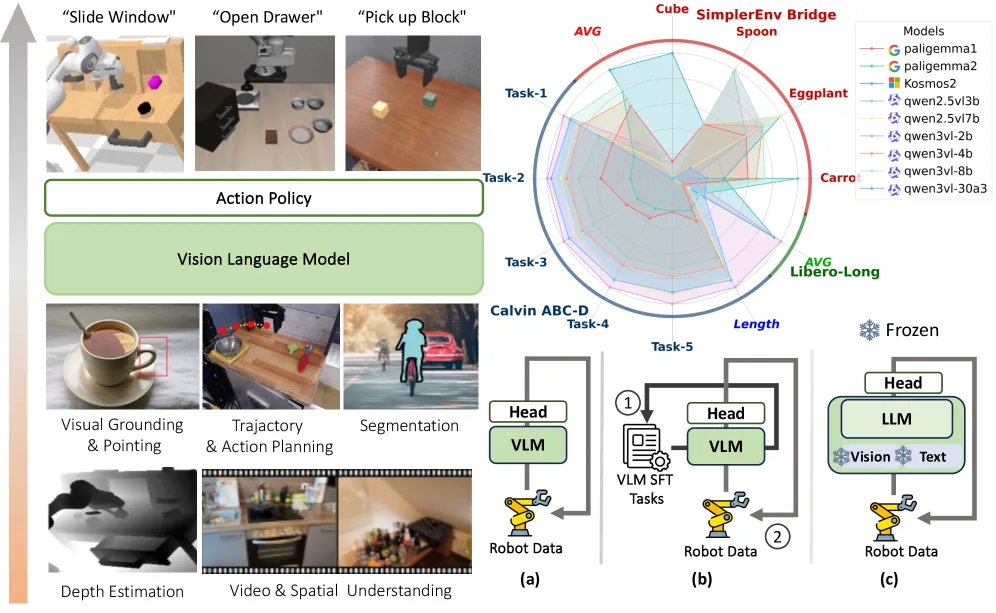
- 设计了公平、可复现的VLA评估框架VLM4VLA,使用简单MLP头和L1/L2损失,避免扩散损失的随机性
- 在三种环境下评估了24种不同的VLM(包括Qwen2.5VL、Qwen3VL、Paligemma、Kosmos-2系列),参数量从1B到31B
- 发现VLM的通用能力(VQA基准测试成绩)是下游任务表现的不良预测因子,不同基准测试结果之间存在不一致性
- 发现针对特定具身任务的辅助微调(如Robopoint、Vica-332k、Robo2vlm等)并不能提升VLA性能
- 通过模态级消融实验,识别出视觉编码器而非语言组件是主要性能瓶颈,并验证了注入控制相关信息到视觉编码器可获得一致性收益
Card 04
方法描述
方法描述
- 网络设计:引入可学习的动作查询令牌(ActionQuery),从VLM中提取具身相关知识,使用小型MLP策略头将令牌表示解码为动作块
- 训练目标:采用最大似然模仿学习目标,使用Huber损失优化末端执行器相对位置,二元交叉熵损失优化末端执行器离散状态
- 输入处理:统一使用224×224分辨率的单帧图像作为视觉输入,不使用本体感知状态信息
- 训练设置:全参数微调VLM所有组件(视觉编码器、词嵌入、LLM和策略头)
Card 05
数据集与资源
数据集与资源
- 评估基准:Calvin ABC-D、SimplerEnv Bridge、Libero-Long (-10)
- 测试VLM模型:Qwen2.5VL-3B/7B、Qwen3VL-2B/4B/8B/30B-A3B、Paligemma-1/2、Kosmos-2
- 模型规模:1.7B至31.1B参数
- 训练硬件:8块NVIDIA A100 GPU(Qwen3VL-30B使用32块)
Card 06
评估与结果
评估与结果
- Calvin基准:QwenVL系列表现最佳,Qwen3VL-2B达到4.142平均完成任务数,与先进VLA模型相当
- SimplerEnv Bridge:Kosmos-2(最小模型)达到最高成功率60.4%,Paligemma系列表现优于Qwen2.5VL
- Libero-Long:ThinkAct(使用本体感知状态)达到70.9%显著领先
- 关键发现:VLM通用能力与VLA性能相关性低(Calvin与VQA相关,但Simpler/Libero无明显相关);冻结视觉编码器导致性能大幅下降(Qwen2.5VL-7B下降1.234),而冻结词嵌入几乎无影响;视觉编码器微调对控制性能至关重要,存在明显的视觉-语言任务与低级动作控制之间的语义鸿沟