一眼看懂
封面预览
论文提出 V-VLAPS(Value Vision-Language-Action Planning and Search)框架,旨在解决 V…
- 论文提出 V-VLAPS(Value Vision-Language-Action Planning and Search)框架,旨在解决 V…
- 核心方法是将蒙特卡洛树搜索(MCTS)与可学习的价值函数相结合,为搜索提供对未来回报的显式估计,纠正 VLA 先验不准确时的动作选择偏差
- 在 LIBERO 机器人操作任务套件上评估,验证了价值引导搜索的有效性
Card 01
研究单位
研究单位
- University of British Columbia(不列颠哥伦比亚大学)
- 作者:Ali Salamatian(项目负责人)、Ke (Steve) Ren、Kieran Pattison、Cyrus Neary
Card 02
论文概述
论文概述
- 论文提出 V-VLAPS(Value Vision-Language-Action Planning and Search)框架,旨在解决 Vision-Language-Action(VLA)模型在分布偏移下的脆弱性问题
- 核心方法是将蒙特卡洛树搜索(MCTS)与可学习的价值函数相结合,为搜索提供对未来回报的显式估计,纠正 VLA 先验不准确时的动作选择偏差
- 在 LIBERO 机器人操作任务套件上评估,验证了价值引导搜索的有效性
Card 03
核心贡献
核心贡献
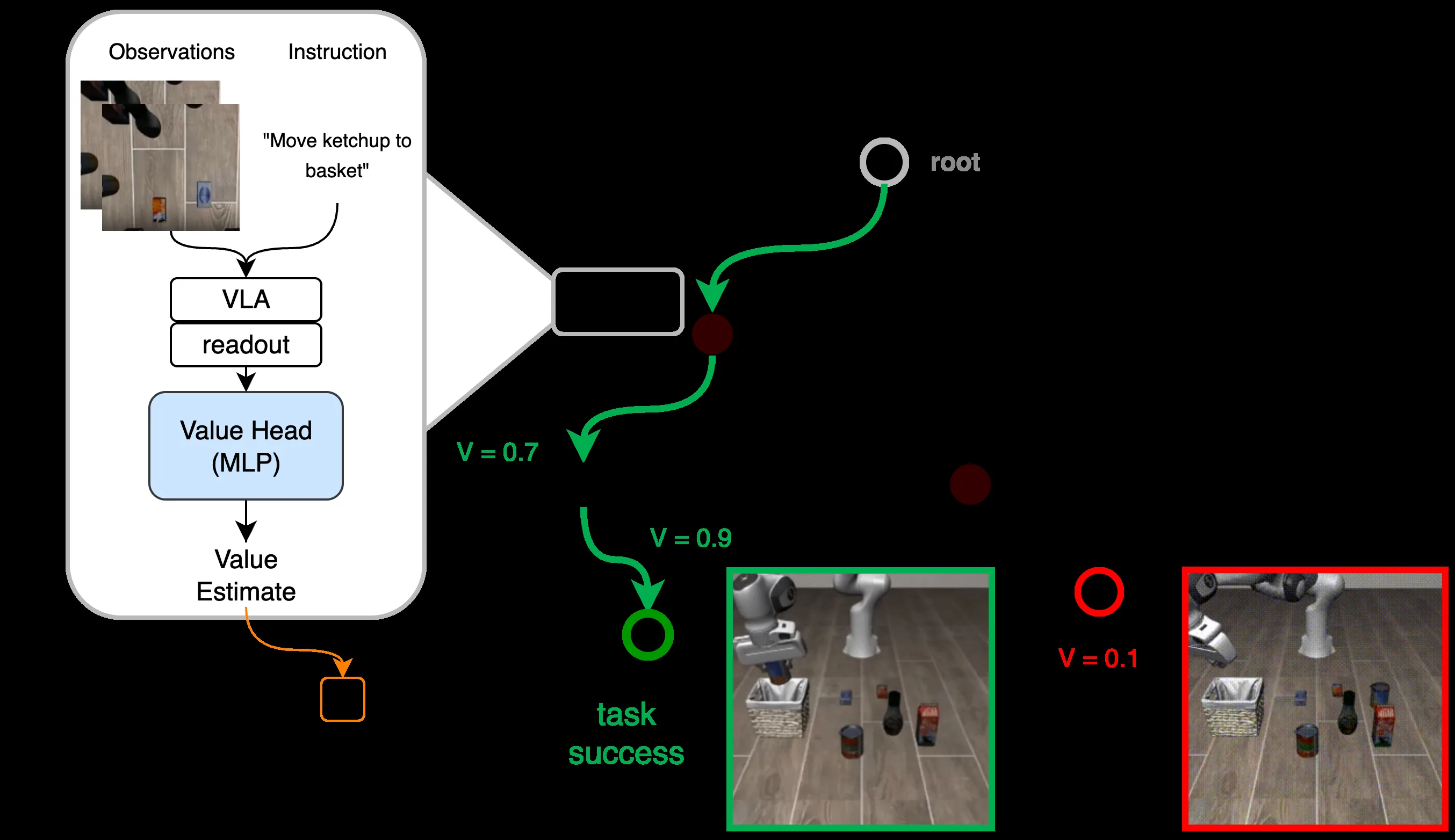
- 提出在 VLAPS 的 MCTS 中集成轻量级可学习价值函数(3层 MLP),利用冻结的 Octo VLA 主干网络的潜在表示进行训练
- 通过在 VLA 回滚轨迹上计算蒙特卡洛价值目标来训练价值头,使用折扣因子 γ=0.99 的稀疏终端奖励
- 将价值估计整合到 PUCT 风格的节点选择评分规则中:SCORE = V_θ(readout(s')) + VLAPS_SCORE
- 在 LIBERO 任务上实现成功率提升超过 5 个百分点,同时减少 5-15% 的 MCTS 模拟次数
Card 04
方法描述
方法描述
- 数据收集:在 LIBERO 任务上运行预训练的 Octo VLA 策略,收集决策步骤序列 (o_0, c_0, o_1, c_1, ..., o_T),提取每个状态的潜在 readout 向量 h_t
- 价值头训练:将 h_t 输入到 3 层 MLP,预测蒙特卡洛价值目标 G_t(成功时为 γ^(T-t),失败时为 0),使用 MSE 损失训练
- 价值集成:使用价值估计替代传统的 Q 值,结合 VLA 动作先验和访问次数,探索-利用平衡
Card 05
数据集与资源
数据集与资源
- 数据集:LIBERO 机器人操作套件(包括 Spatial 和 Object 两个子集)
- 训练任务:Spatial (任务 1, 6, 8)、Object (任务 0, 1, 2, 3, 4, 6, 8)
- 样本数量:训练集 524,157 个样本,测试集 58,239 个样本
- 成功轨迹平均长度:37.80 步
- VLA 主干模型:Octo(开源通用机器人策略)
Card 06
评估与结果
评估与结果
- 评估环境:LIBERO 模拟机器人操作环境,每个任务 10 次回滚,初始状态 0-9
- 关键指标:成功率(%)、MCTS 模拟次数
- 主要结果:
- Spatial 套件:V-VLAPS 成功率达 87.2%,比 VLAPS 提升 5.2%;MCTS 模拟减少 5%
- Object 套件:V-VLAPS 成功率达 82.6%,比 VLAPS 提升 2.8%;MCTS 模拟减少 14%
- 特别案例:Spatial 任务 9(VLA 完全失败),V-VLAPS 比 VLAPS 提升 31%
- 定性分析:t-SNE 可视化显示 Octo 潜在表示成功和失败轨迹有明显区分模式