一眼看懂
封面预览
论文介绍了 Moxin 7B,一个完全开源的大型语言模型,遵循 Model Openness Framework (MOF) 标准,超越仅共享…
- 论文介绍了 Moxin 7B,一个完全开源的大型语言模型,遵循 Model Openness Framework (MOF) 标准,超越仅共享…
- 基于 Moxin 开发了三个多模态变体:Moxin-VLM(视觉语言模型)、Moxin-VLA(视觉语言动作模型)和 Moxin-Chines…
- 旨在解决当前开源模型"伪开源"(openwashing)问题,促进可复现、透明和可用的 AI 研究环境
Card 01
研究单位
研究单位
- Northeastern University (美国东北大学)
- Harvard University (哈佛大学)
- Cornell University (康奈尔大学)
- Tulane University (杜兰大学)
- University of Washington (华盛顿大学)
- Roboraction.ai
- Futurewei
- AIBAO LLC
Card 02
论文概述
论文概述
- 论文介绍了 Moxin 7B,一个完全开源的大型语言模型,遵循 Model Openness Framework (MOF) 标准,超越仅共享模型权重,实现训练过程、数据集和实现细节的完全透明
- 基于 Moxin 开发了三个多模态变体:Moxin-VLM(视觉语言模型)、Moxin-VLA(视觉语言动作模型)和 Moxin-Chinese(中文增强模型)
- 旨在解决当前开源模型"伪开源"(openwashing)问题,促进可复现、透明和可用的 AI 研究环境
Card 03
核心贡献
核心贡献
- 开发了 Moxin-VLM,采用 DINOv2 和 SigLIP 作为视觉骨干网络,Moxin-7B-Base 作为 LLM 骨干,在多个 VLM 基准上优于 LLaVA v1.5、Llama-2 和 Mistral 等基线模型
- 开发了 Moxin-VLA,基于 OpenVLA-OFT 微调范式,采用并行解码和动作分块技术,在 LIBERO 仿真环境中实现卓越的机器人控制性能
- 开发了 Moxin-Chinese,通过扩展词表至约 57k 个 token 并持续预训练,显著提升中英翻译和中文理解能力
- 完全开源所有模型权重、训练代码和数据集,推动真正的开放科学协作
Card 04
方法描述
方法描述
- Moxin-VLM:基于 Prismatic VLMs 框架,采用双视觉骨干(DINOv2 提取低级空间特征 + SigLIP 提取高级语义特征),单阶段训练投影层和语言模型
- Moxin-VLA:在 Moxin-VLM 基础上,使用 OpenVLA-OFT 高效微调配方,采用 LoRA (r=32) 进行参数高效微调,支持并行动作解码和动作分块(action chunking)以降低延迟
- Moxin-Chinese:使用 SentencePiece 训练中文 BPE 词表,融合多源高质量中文词汇,在 WanJuan、gutenberg-books、Chinese-Data-Distill-From-R1 等数据集上持续预训练
Card 05
数据集与资源
数据集与资源
- VLM 训练数据:LLaVA v1.5 数据混合(558K 图像描述 + 665K 多模态指令微调),包括 Conceptual Captions、LAION、GQA、TextCaps、RefCOCO、Visual Genome、ShareGPT 等
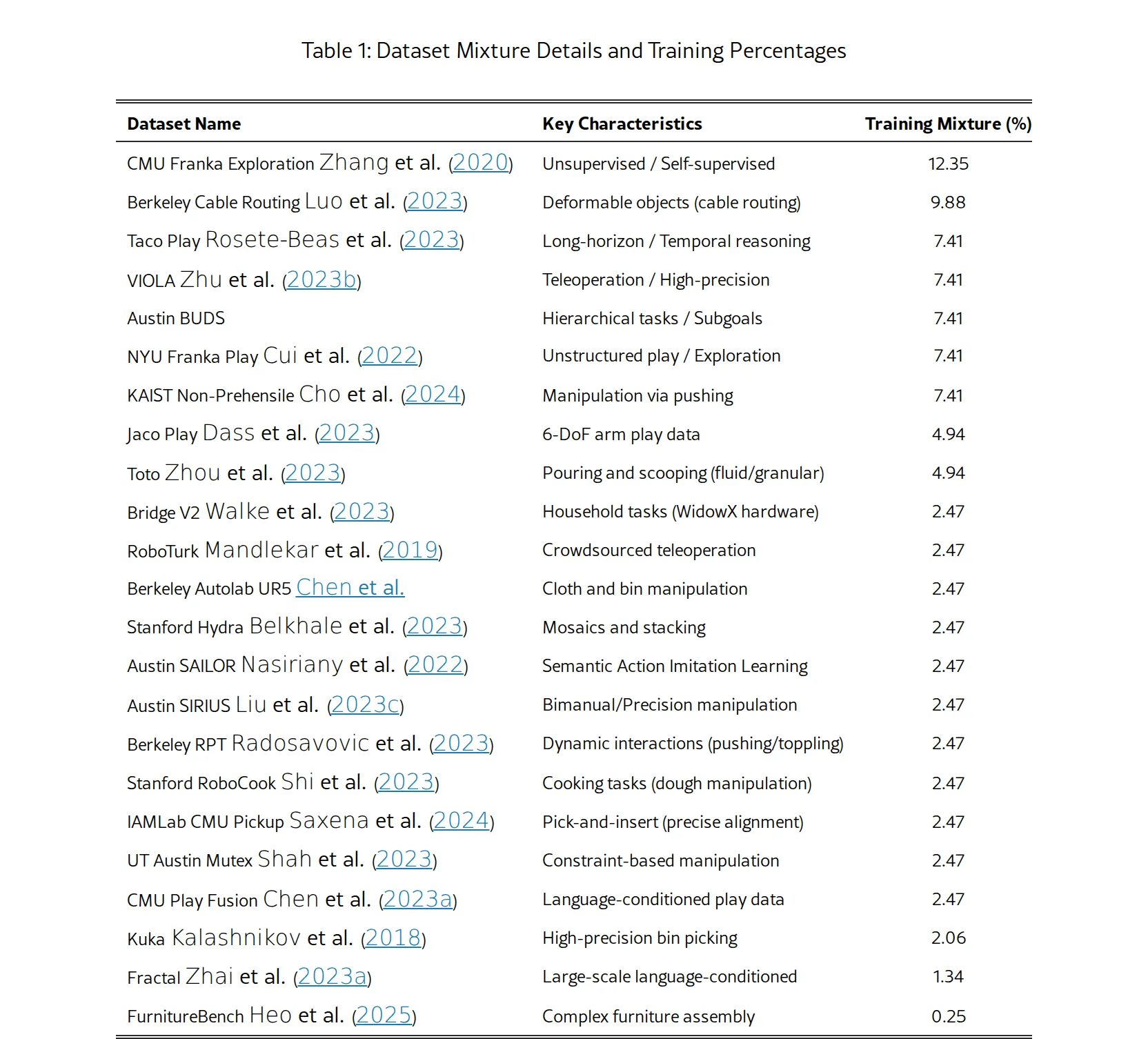
- VLA 训练数据:Open X-Embodiment (OXE) 数据集,超过 100 万条真实机器人轨迹,涵盖 22 种机器人形态,以 CMU Franka Exploration (12.35%)、Berkeley Cable Routing (9.88%) 等为主
- 中文训练数据:WanJuan、gutenberg-books、Chinese-Data-Distill-From-R1、Garsa3112/ChineseEnglishTranslationDataset 等
- 计算资源:8x H100 GPU 单节点,VLM 训练 2 个 epoch,VLA 训练 90k 步(约两周),使用 LoRA 高效微调
Card 06
评估与结果
评估与结果
- VLM 评估:在 GQA、VizWiz、RefCOCO+、OCID-Ref、VSR、POPE、TallyQA 等基准上测试,平均准确率 64.68%,超越 Mistral 7B (62.83%)、Llama-2 7B (61.63%) 和 LLaVA v1.5 7B (57.21%)
- VLA 评估:在 LIBERO 仿真环境(Spatial、Object、Goal、Long 四个任务集)上测试:
- 有机器人预训练版本:91.95% 平均成功率,Spatial 任务达 98.0%(最优)
- 无机器人预训练版本:92.5% 平均成功率,Object (98.4%)、Goal (92.0%)、Long (87.8%) 均为最优,超越 OpenVLA-OFT (91.9%) 和 NORA-Long (87.9%)
- 中文评估:在 CMMLU 和 CEVAL 基准上,Moxin-Chinese 分别达到 45% 和 45.76%,优于 Chinese-LLaMA-2-13B (39.9%/42.48%) 和 Chinese-LLaMA-Alpaca-2-13B (43.2%/44.3%)