一眼看懂
封面预览
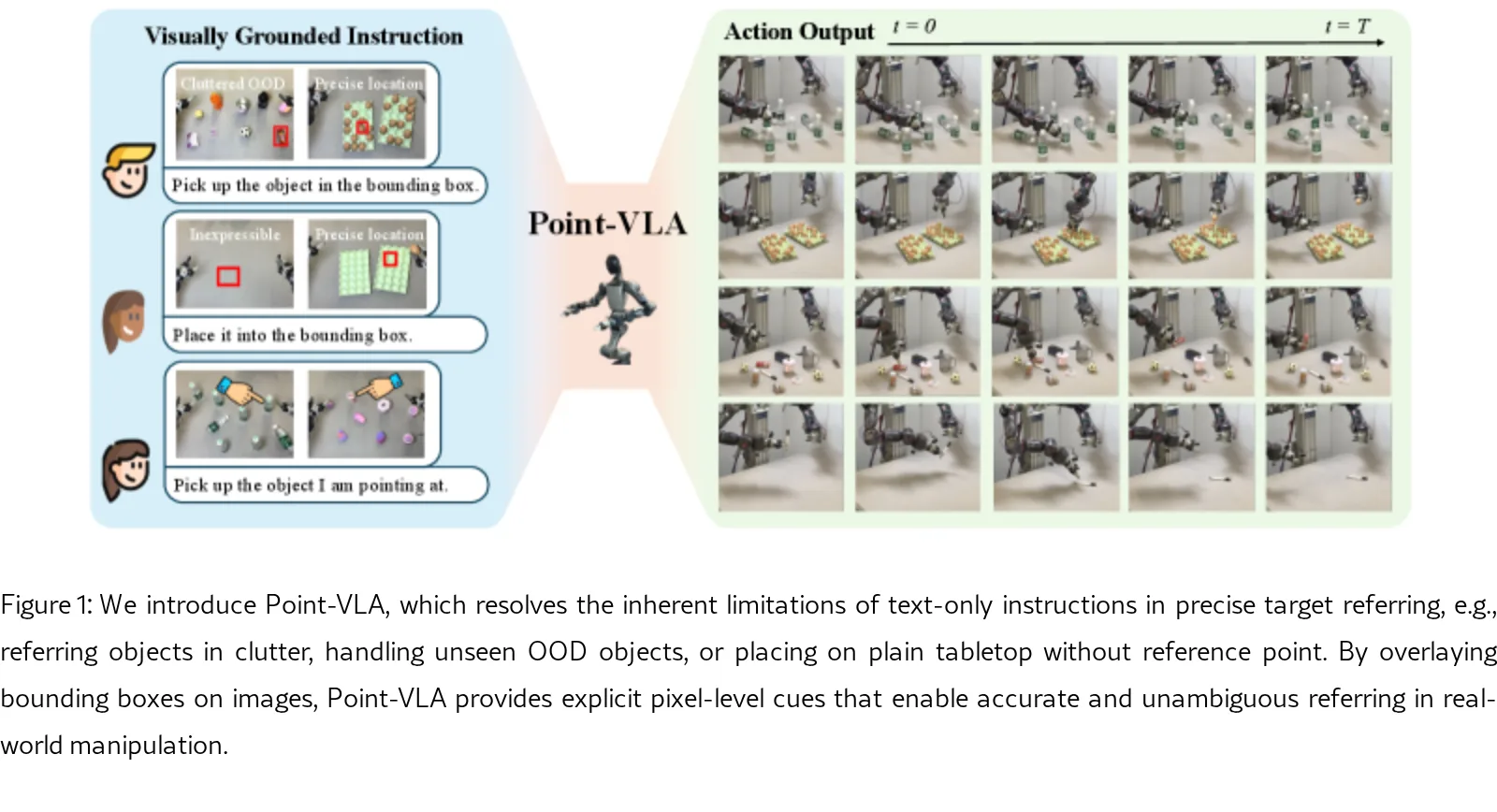
提出 Point-VLA,一种通过显式视觉提示(如边界框)增强语言指令的视觉-语言-动作(VLA)策略,解决纯文本指令在复杂场景中的指代歧义问题
- 提出 Point-VLA,一种通过显式视觉提示(如边界框)增强语言指令的视觉-语言-动作(VLA)策略,解决纯文本指令在复杂场景中的指代歧义问题
- 针对 VLA 模型在杂乱场景(cluttered scenes)和分布外(OOD)场景中难以通过文本精确定位目标的局限性,实现像素级的视觉 g…
- 开发自动化数据标注流程,利用多模态大语言模型(MLLM)从演示视频中自动生成视觉 grounding 监督信号,降低人工标注成本
Card 01
研究单位
研究单位
- Tongji University (同济大学)
- Shanghai Jiao Tong University (上海交通大学)
- Spirit AI
- Tsinghua University (清华大学)
Card 02
论文概述
论文概述
- 提出 Point-VLA,一种通过显式视觉提示(如边界框)增强语言指令的视觉-语言-动作(VLA)策略,解决纯文本指令在复杂场景中的指代歧义问题
- 针对 VLA 模型在杂乱场景(cluttered scenes)和分布外(OOD)场景中难以通过文本精确定位目标的局限性,实现像素级的视觉 grounding
- 开发自动化数据标注流程,利用多模态大语言模型(MLLM)从演示视频中自动生成视觉 grounding 监督信号,降低人工标注成本
Card 03
核心贡献
核心贡献
- 提出 Point-VLA 统一策略,支持纯文本和视觉 grounding 两种指令模式,通过 co-training 实现无缝切换
- 设计基于边界框的视觉 grounding 机制,将语言指令与像素级目标显式绑定,解决语言表达不可描述的空间引用问题
- 构建四阶段自动化数据标注流水线(场景理解、关键时刻定位、俯视目标定位、结构化 JSON 输出),实现规模化数据构建
- 提出两种 grounding 感知数据增强策略:随机平移(random translation)和局部 CutMix,提升模型对空间变化和新颖外观的泛化能力
- 在真实世界机器人平台上验证,在 6 项指代敏感操作任务上平均成功率达 92.5%,相比纯文本基线提升 60.1 个百分点
Card 04
方法描述
方法描述
- 视觉 grounding 指令形式:在第一帧俯视图像上叠加边界框,与多视角观测共同输入 VLA 主干网络
- 自动标注流水线:利用 Gemini ER1.5 MLLM 分析多视角视频,自动输出目标边界框和任务元信息
- 数据增强策略:
- 随机平移:使场景和边界框共同移动,学习相对位置而非绝对坐标
- 局部 CutMix:在边界框内替换 ImageNet 图像块,防止对特定外观过拟合
- 联合训练策略:以 1:1 比例混合纯文本指令数据和视觉 grounding 指令数据进行 co-training
Card 05
数据集与资源
数据集与资源
- 数据集:真实世界机器人演示数据,涵盖 12 个不同场景,每个任务约 2 小时演示
- 模型主干:主要基于 π₀.₅ VLA 模型,同时验证 π₀ 模型
- 机器人平台:
- 双臂固定机器人(配备 1 个俯视 RGB 相机 + 2 个腕部相机)
- 全身人形机器人(带主动腰部和腿部控制)
- 训练设置:每任务微调 20k 步,使用官方优化配置
Card 06
评估与结果
评估与结果
- 评估任务:6 项真实世界操作任务,包括不规则物体抓取、OOD 物体抓取、杂乱场景抓取、蛋托精细抓取、平面放置、蛋托精细放置
- 主要指标:任务成功率(success rate),每项任务 30+ 次独立试验
- 关键结果:
- 平均成功率 92.5%,相比 Text VLA 基线(32.4%)提升 60.1%
- 相比 Interleave-VLA 基线(40.0%)提升 52.5%
- 最难任务(蛋托抓取)提升超过 75 个百分点
- OOD 物体抓取提升 35 个百分点
- 跨平台验证:在 π₀.₅ 和 π₀ 两种主干、双臂和全身两种机器人形态上均保持显著优势