一眼看懂
封面预览
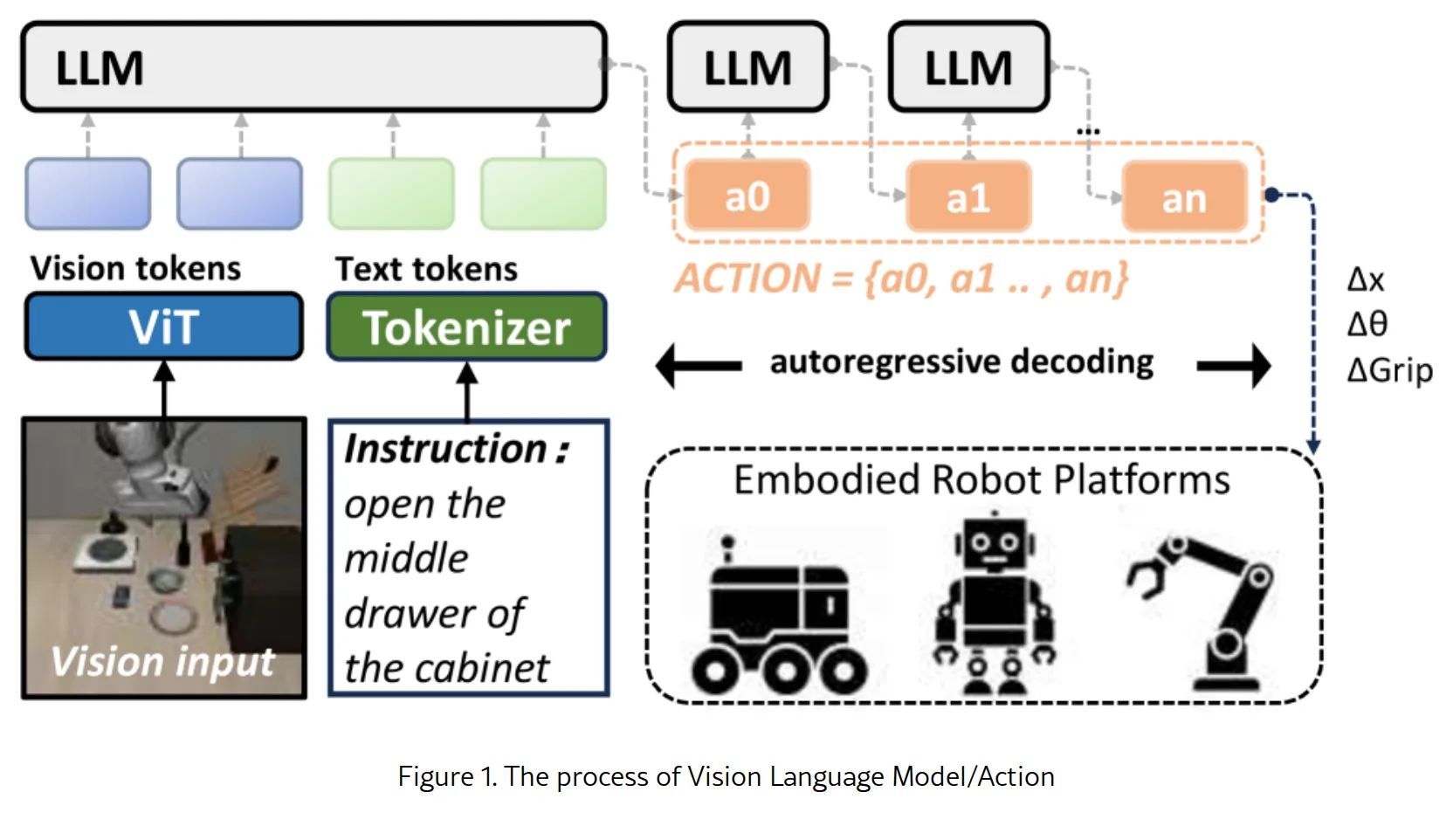
针对 Vision-Language-Action (VLA) 模型在边缘设备上推理延迟过高的问题,提出系统级优化框架 ActionFlow
- 针对 Vision-Language-Action (VLA) 模型在边缘设备上推理延迟过高的问题,提出系统级优化框架 ActionFlow
- 解决 VLA 模型在边缘设备上仅能达到 3-5 FPS,远低于机器人实时控制所需的 20-30 Hz 的瓶颈
- 核心思想是通过 Cross-Request Pipelining 策略,将内存受限的 Decode 阶段与计算密集的 Prefill 阶段进行…
Card 01
研究单位
研究单位
- University of Science and Technology of China(中国科学技术大学):Yuntao Dai、Hang Gu、Qianyu Cheng、Yifei Zheng、Lei Gong、Xuehai Zhou 所属单位
- Suzhou Institute for Advanced Research, University of Science and Technology of China(中国科学技术大学苏州高等研究院):Teng Wang、Wenqi Lou 所属单位
- IEIT SYSTEMS Co., Ltd.(浪潮电子信息产业股份有限公司):Zhiyong Qiu 所属单位
Card 02
论文概述
论文概述
- 针对 Vision-Language-Action (VLA) 模型在边缘设备上推理延迟过高的问题,提出系统级优化框架 ActionFlow
- 解决 VLA 模型在边缘设备上仅能达到 3-5 FPS,远低于机器人实时控制所需的 20-30 Hz 的瓶颈
- 核心思想是通过 Cross-Request Pipelining 策略,将内存受限的 Decode 阶段与计算密集的 Prefill 阶段进行跨请求批处理,提升硬件利用率
Card 03
核心贡献
核心贡献
- 提出 Cross-Request Pipelining 策略,将单个 VLA 任务视为宏流水线,对内部 Prefill 和 Decode 微请求进行批处理
- 设计并实现 Cross-Request State Packed Forward 算子,将多个内存受限的矩阵-向量操作融合为单个计算密集的矩阵-矩阵操作
- 提出 Unified KV Ring Buffer 机制,通过内核融合高效管理 KV 缓存,消除 CPU-GPU 同步开销
- 构建端到端推理框架 ActionFlow,专门针对资源受限的边缘设备优化,无需重新训练即可实现加速
Card 04
方法描述
方法描述
- Cross-Request Pipelining:将连续 K 个时间步的请求组成流水线,当前请求的 Prefill 阶段与历史请求的 Decode 阶段并行执行
- Cross-Request State (CRS):聚合 K 个不同阶段的输入为单一张量,实现打包执行
- 内核融合优化:通过 FusedRoPEAndWriteKV 和 InPlaceKVShift 两个融合内核,避免动态内存分配和数据拷贝
- Unified KV Ring Buffer:使用环形缓冲区物理连续存储所有活跃请求的 KV 状态,支持变长注意力机制
Card 05
数据集与资源
数据集与资源
- 模型:OpenVLA-7B(70 亿参数的视觉-语言-动作模型)
- 硬件平台:NVIDIA Jetson AGX Orin (64GB)(边缘嵌入式设备)、NVIDIA RTX 5090(高性能边缘工作站)
- 软件栈:PyTorch 2.6.0、Transformers 4.49.0、CUDA 12.6
- 评估基准:LIBERO 基准测试套件(包含 spatial、object、goal、long 等任务类别)
Card 06
评估与结果
评估与结果
- 核心指标:FPS(每秒帧数)、任务成功率(Success Rate)
- 主要结果:在 Jetson AGX Orin 上达到 3.20 FPS(2.56× 加速),在 RTX 5090 上达到 19.45 FPS(2.55× 加速)
- 消融实验:相比未融合内核的 Naive Pipe 版本,ActionFlow 在 AGX Orin 上额外提升 18.5%,在 RTX 5090 上额外提升 24.7%
- 负载敏感性:在重负载场景(K=32, 长 Prefill)下,加速比可达 4.06×(RTX 5090)和 4.36×(AGX Orin)
- 功能正确性:在 LIBERO 基准上,ActionFlow 与基线模型的任务成功率相当,证明优化无损模型精度