一眼看懂
封面预览
论文提出 DuoCore-FS,一种真正异步的快慢双系统视觉-语言-动作(VLA)框架,用于全身机器人操控
- 论文提出 DuoCore-FS,一种真正异步的快慢双系统视觉-语言-动作(VLA)框架,用于全身机器人操控
- 解决现有VLA系统中VLM推理速度慢限制控制频率的问题,实现高频动作生成与丰富语义推理的解耦
- 针对全身操控任务(25自由度、动态视角变化)对实时性和控制稳定性的高要求
Card 01
研究单位
研究单位
- Astribot Team (astribot_ai@astribot.com)
Card 02
论文概述
论文概述
- 论文提出 DuoCore-FS,一种真正异步的快慢双系统视觉-语言-动作(VLA)框架,用于全身机器人操控
- 解决现有VLA系统中VLM推理速度慢限制控制频率的问题,实现高频动作生成与丰富语义推理的解耦
- 针对全身操控任务(25自由度、动态视角变化)对实时性和控制稳定性的高要求
Card 03
核心贡献
核心贡献
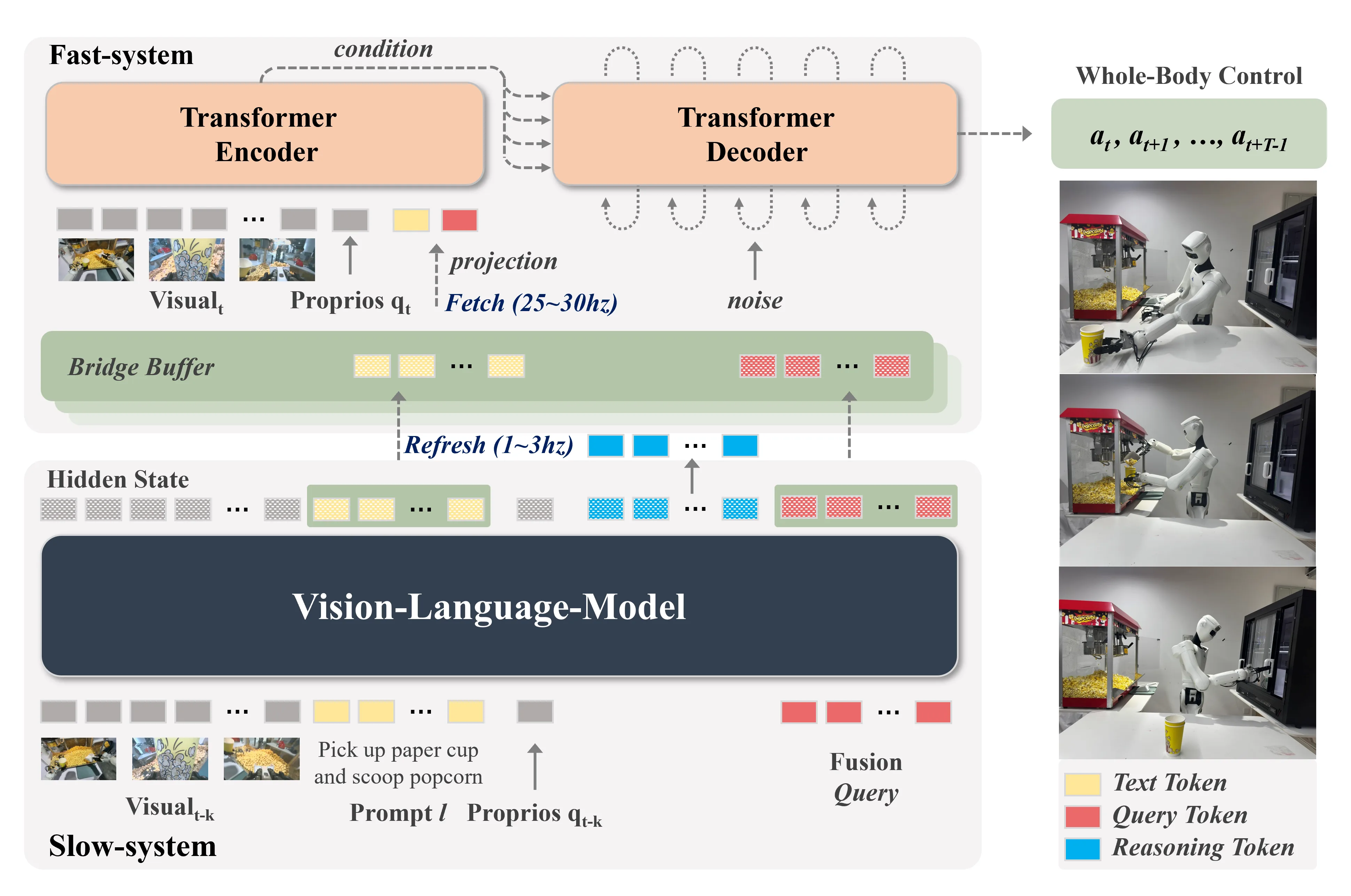
- 真正并行异步的快慢执行架构:慢系统(1-3 Hz)进行语义推理,快系统(25-30 Hz)生成连续全身动作,两者完全并行运行
- 桥接缓冲区(Bridge Buffer)机制:存储VLM产生的语义和推理表征,实现快慢系统间的异步信息传递
- 全身动作分词器(Whole-Body Action Tokenizer):基于RVQ-VAE的紧凑统一表示,支持25自由度全身关节配置
- 端到端联合训练:快慢系统同时优化,保持语义-控制对齐,无需手工设计模块
- 跨时间尺度协同训练策略:模拟真实部署中的异步时序特性,消除训练-推理不匹配
Card 04
方法描述
方法描述
- 慢系统:使用3B参数VLM(如PaliGemma-3B、Qwen2.5-VL)生成语义隐状态、推理特征和可学习的融合查询
- 快系统:基于Transformer的扩散策略解码器,以Pi0-small风格建模条件向量场,生成连续动作块
- 桥接缓冲区:可微分接口,存储指令嵌入和融合查询嵌入,支持端到端训练
- 动作分词:将29维动作分解为位置、旋转(SO(3))、夹爪三个流,分别用1D卷积编码器和RVQ量化
- 推理加速:采用Jacobi风格并行解码策略降低慢系统延迟
Card 05
数据集与资源
数据集与资源
- 数据集:1,780条演示轨迹(10.22小时),来自商业爆米花售卖场景,包含长程爆米花舀取任务和短程饮料柜关门任务
- 模型规模:慢系统采用3B参数VLM(基于PaliGemma-3B的π0-FAST),快系统为轻量化扩散策略网络
- 训练资源:第一阶段24张NVIDIA H100 GPU训练30轮;第二阶段联合训练12轮
- 推理平台:NVIDIA RTX 4090 GPU,快系统编译为TensorRT BF16格式
Card 06
评估与结果
评估与结果
- 评估基准:真实世界Astribot S1平台(双臂7-DoF + 4-DoF躯干 + 2-DoF头部 + 3-DoF移动底座)
- 主要指标:各子任务条件成功率、整体任务成功率、推理频率(Hz)
- 关键结果:
- 推理速度:DuoCore-FS达到32.3 Hz,约为π0(12.5 Hz)的3倍,慢系统单独仅3.27 Hz
- 分布内任务:整体成功率90%(vs. π0的85%),在保持精度的同时实现显著加速
- 分布外泛化:整体成功率50%(vs. π0的10%),慢系统的自回归推理增强泛化能力
- 语言遵循能力:42.9%成功率(vs. π0的14.3%),慢系统的token-by-token推理提升指令理解
- 异常场景鲁棒性:95.8%检测恢复成功率(vs. π0的91.7%)