一眼看懂
封面预览
提出 LoLA(Long Horizon Latent Action Learning),一个用于长时程机器人操作的视觉-语言-动作(VLA)…
- 提出 LoLA(Long Horizon Latent Action Learning),一个用于长时程机器人操作的视觉-语言-动作(VLA)…
- 解决现有 VLA 模型在长时程任务中忽视历史信息、缺乏时间连贯性的问题
- 核心挑战包括:时间上下文理解、分布外状态累积、长序列计算开销
Card 01
研究单位
研究单位
- Institute of Microelectronics, Chinese Academy of Sciences
- University of Chinese Academy of Sciences
- Microsoft Research
Card 02
论文概述
论文概述
- 提出 LoLA(Long Horizon Latent Action Learning),一个用于长时程机器人操作的视觉-语言-动作(VLA)框架
- 解决现有 VLA 模型在长时程任务中忽视历史信息、缺乏时间连贯性的问题
- 核心挑战包括:时间上下文理解、分布外状态累积、长序列计算开销
Card 03
核心贡献
核心贡献
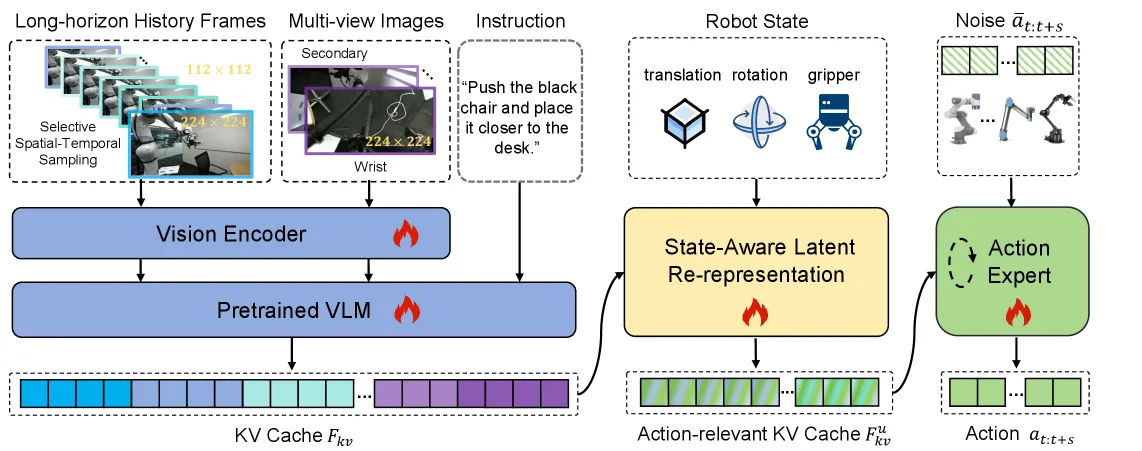
- 提出 State-Aware Latent Re-representation (SALR) 模块,将视觉-语言嵌入显式锚定到机器人本体感知空间
- 设计选择性时空采样策略,平衡高保真当前观测与下采样历史运动编码
- 引入可学习掩码操作,抑制动作无关噪声,提取关键动作信号
- 在模拟基准(SIMPLER、LIBERO)和真实机器人(Franka、Bi-Manual Aloha)上验证有效性
- 在长时程任务上显著超越现有 SOTA 方法(如 π₀)
Card 04
方法描述
方法描述
- 视觉编码:使用预训练 VLM(Qwen2.5-VL)处理多视角图像,包括高分辨率当前观测编码和下采样历史运动编码
- SALR 模块:通过 State Transformer 与 VLM 并行运行,利用外积融合将机器人状态查询与 VLM 的 Key-Value 缓存进行状态感知的多plicative 融合
- 动作专家:基于条件流匹配(CFM)的 Transformer 解码器,从 SALR 输出的对齐表征生成多步动作序列
- 采用 25 帧历史信息作为默认配置
Card 05
数据集与资源
数据集与资源
- 预训练数据:OXE 数据集和 AgiBot 数据集,共 110 万真实机器人片段(约 6200 万时间步)
- 真实世界数据:28 个 Franka 长时程任务(含 22 个原子子任务和 6 个端到端任务,平均时长 2.3 分钟),以及 BusyBox Bi-Manual Aloha 数据集
- 训练资源:32 张 NVIDIA A100 GPU,批次大小 1280
Card 06
评估与结果
评估与结果
- SIMPLER 基准:在 Google Robot 上平均成功率 61.5%(Visual Matching)和 54.6%(Variant Aggregation),在 WidowX Robot 上达 71.9%,相对 π₀ 提升 20.6%
- LIBERO 基准:平均成功率 96.2%,在长时程 LIBERO-Long 任务上达 88.2%,超越 π₀(92.2% / 85.4%)
- 真实世界 Franka:单步任务平均成功率 46.1%,多步长时程任务成功率最高达 33.1%(相对 π₀ 提升 2.67 倍)
- Bi-Manual Aloha:平均成功率 46.7%,显著优于 π₀(30.0%)和 Diffusion Policy(8.3%)
- 消融实验:验证历史帧(MF)和 SALR 模块的关键作用,使用机器人状态信息可将平均成功率从 84.7% 提升至 91.2%