一眼看懂
封面预览
提出 STORM (Search-Guided Generative World Models),一种用于机器人操作的新型时空推理框架,统一了…
- 提出 STORM (Search-Guided Generative World Models),一种用于机器人操作的新型时空推理框架,统一了…
- 解决现有视觉-语言-动作 (VLA) 模型依赖语言组件或抽象潜在动态进行推理的局限性,通过显式视觉推演实现更可解释、更鲁棒的长程规划
- 提出 STORM 框架,集成扩散式 VLA、生成式视频世界模型和 MCTS 规划器,实现显式时空推理
Card 01
研究单位
研究单位
- Sun Yat-sen University, Guangzhou, China
Card 02
论文概述
论文概述
- 提出 STORM (Search-Guided Generative World Models),一种用于机器人操作的新型时空推理框架,统一了扩散式动作生成、条件视频预测和基于搜索的规划
- 解决现有视觉-语言-动作 (VLA) 模型依赖语言组件或抽象潜在动态进行推理的局限性,通过显式视觉推演实现更可解释、更鲁棒的长程规划
Card 03
核心贡献
核心贡献
- 提出 STORM 框架,集成扩散式 VLA、生成式视频世界模型和 MCTS 规划器,实现显式时空推理
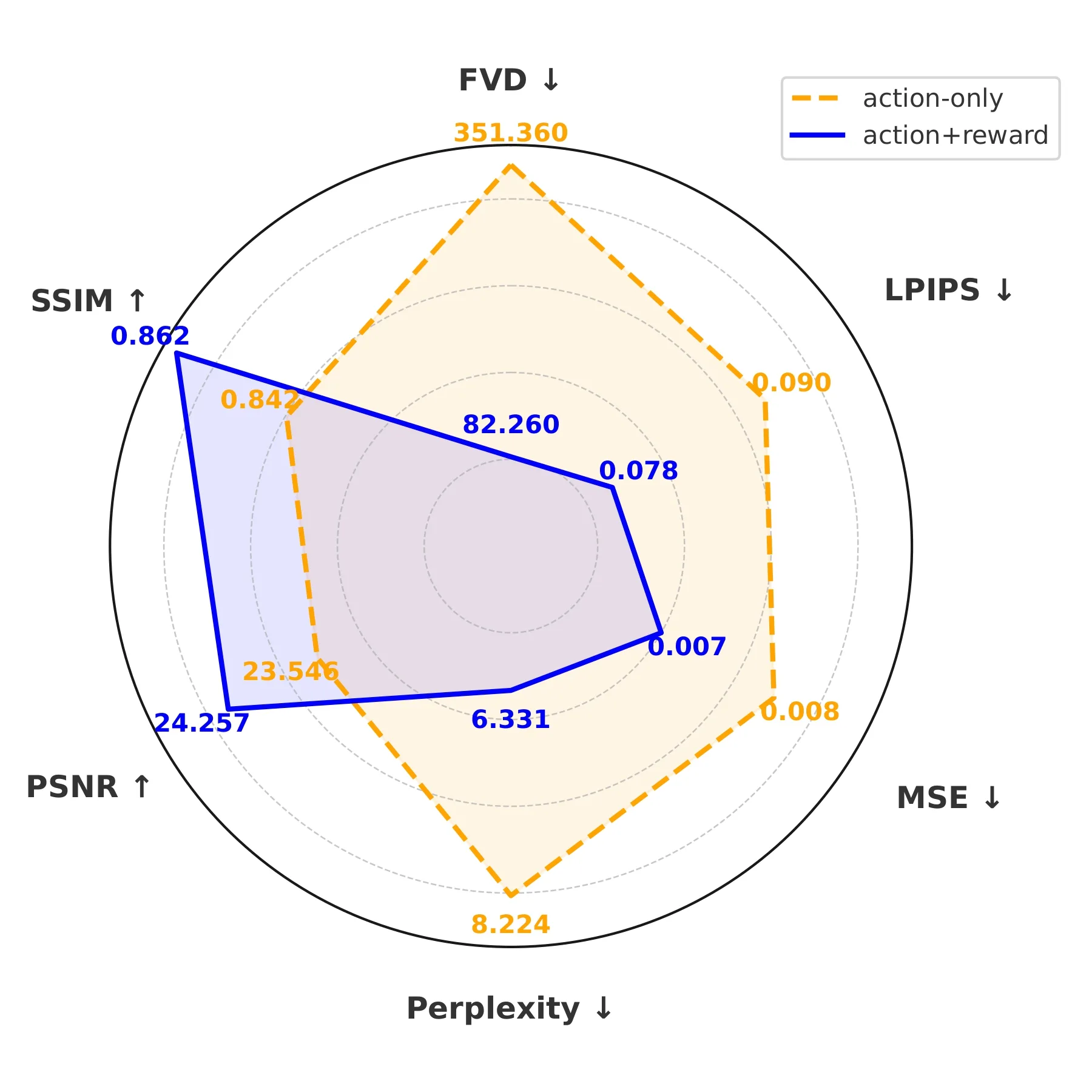
- 证明奖励增强的视频预测器作为高效生成世界模型,显著提升动作条件视觉推演的保真度和任务相关性
- 在 SimplerEnv 基准上达到 51.0% 平均成功率,超越 CogACT (47.9%) 等强基线
- 展示 STORM 的故障恢复能力,通过重新规划逃离反应式策略陷入的重复错误循环
- 奖励监督使 FVD 降低超过 75%,学习任务感知的因果动态结构
Card 04
方法描述
方法描述
- 扩散式 VLA 策略 (π_vla):基于 CogACT-Base (7B),生成多样化动作候选,建模多模态动作分布
- 生成式视频世界模型 (M_w):基于 iVideoGPT-medium,使用 VQ-VAE 编码和自回归 Transformer,通过混合损失(视频重建 + 奖励预测)进行微调
- MCTS 规划:执行选择、扩展、评估、反向传播循环,使用 PUCT 算法平衡探索与利用,支持在线重新规划
- 创新点:用显式视觉推演替代抽象潜在空间规划,VLA 作为黑盒提议策略实现模块化设计
Card 05
数据集与资源
数据集与资源
- 数据集:Bridge dataset 用于训练,SimplerEnv 用于评估
- 模型规模:VLA 使用 CogACT-Base (7B 参数),视频预测器基于 iVideoGPT-medium
- 训练资源:2× NVIDIA A100 (80GB),约 120,000 步,批量大小 36,AdamW 优化器,学习率 5e-4
- MCTS 参数:N_sim = 8 次模拟,深度 D = 3,折扣因子 γ = 0.9,探索常数 c_puct = 1.0,候选动作数 K = 8
Card 06
评估与结果
评估与结果
- 评估环境:SimplerEnv 模拟器,WidowX 机械臂,4 项操作任务(Put Spoon on Towel、Put Carrot on Plate、Stack Green on Yellow Block、Put Eggplant in Basket)
- 评估指标:任务成功率、FVD、LPIPS、PSNR、SSIM
- 关键结果:
- 平均成功率 51.0%,超越 CogACT (47.9%)、Octo-Small (26.7%)、OpenVLA (4.2%)
- 奖励增强视频预测在 FVD 上比纯动作模型降低 75% 以上
- 案例研究显示 STORM 能从失败中恢复,而 CogACT 陷入重复循环