一眼看懂
封面预览
提出 GeoPredict,一个几何感知的视觉-语言-动作(VLA)框架,通过预测运动学和几何先验增强连续动作策略
- 提出 GeoPredict,一个几何感知的视觉-语言-动作(VLA)框架,通过预测运动学和几何先验增强连续动作策略
- 解决现有VLA模型主要基于2D图像空间、缺乏显式3D空间建模的问题,提升需要精确3D推理的机器人操作任务性能
- 引入 GeoPredict 框架,将未来感知的运动学和几何先验注入连续动作VLA策略
Card 01
研究单位
研究单位
- The Chinese University of Hong Kong, Shenzhen (Jingjing Qian, Chen Shi, Long Yang, Li Jiang)
- Hunan University (Boyao Han)
- LiAuto Inc. (Lei Xiao)
- Voyager Research, Didi Chuxing (Shaoshuai Shi)
Card 02
论文概述
论文概述
- 提出 GeoPredict,一个几何感知的视觉-语言-动作(VLA)框架,通过预测运动学和几何先验增强连续动作策略
- 解决现有VLA模型主要基于2D图像空间、缺乏显式3D空间建模的问题,提升需要精确3D推理的机器人操作任务性能
Card 03
核心贡献
核心贡献
- 引入 GeoPredict 框架,将未来感知的运动学和几何先验注入连续动作VLA策略
- 提出轨迹级运动学预测模块,编码并预测多步机器人关键点运动轨迹
- 提出预测性3D高斯几何模块,通过轨迹引导的细化机制将几何容量分配到任务相关的交互区域
- 预测模块仅在训练时使用,推理时无需调用任何3D解码,保持高效性
- 在 RoboCasa Human-50、LIBERO 和真实世界任务上显著超越强VLA基线
Card 04
方法描述
方法描述
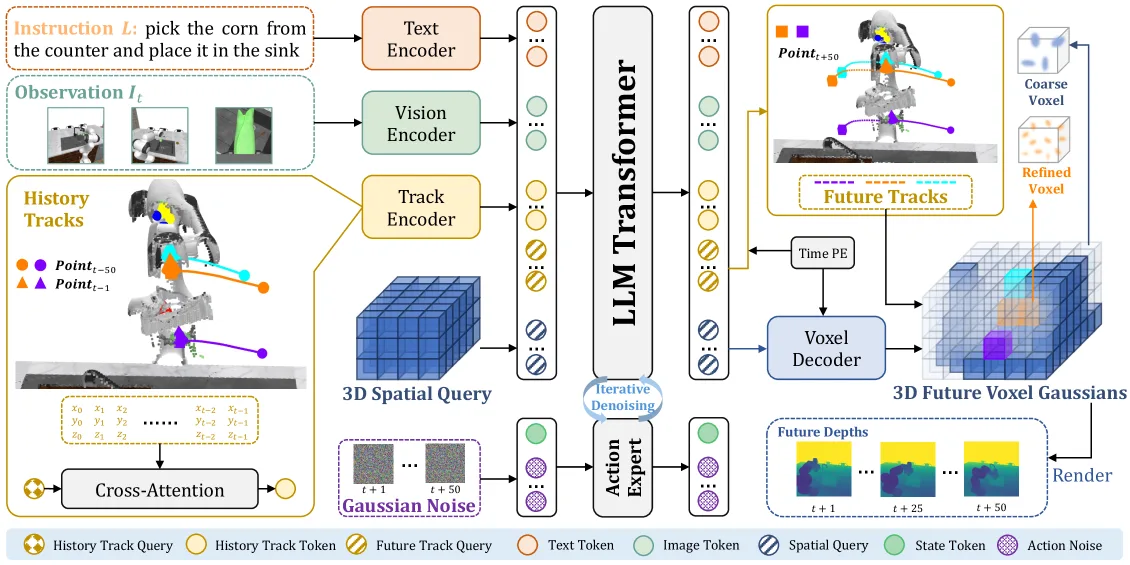
- 基于 π₀ 构建,采用 PaliGemma VLM(SigLIP视觉编码器+Gemma变换器)和动作专家
- 轨迹级运动学预测:Track Encoder压缩运动历史,Future Track Query预测多步3D关键点轨迹(H=50步)
- 预测性3D高斯几何:3D空间查询通过Voxel Decoder解码为高斯基元,轨迹引导细化机制在预测轨迹附近增加高斯密度
- 块级因果注意力机制:2D Token → 3D Token → 3D Query → State Token → Action Noise 的分层结构
- 深度渲染监督:通过可微分alpha合成从3DGS渲染深度图进行监督,无需颜色建模
Card 05
数据集与资源
数据集与资源
- RoboCasa Human-50:24个复杂长程厨房任务,每任务50个人类演示
- LIBERO:4个评估套件(Spatial/Object/Goal/Long),每任务50个演示
- 真实世界评估:空间泛化、几何泛化、视觉鲁棒性三类任务
- 模型规模:token维度C=2048,voxel特征维度C'=256
- 训练资源:8张 NVIDIA H20 GPU,总batch size 32,训练40,000迭代
Card 06
评估与结果
评估与结果
- RoboCasa:平均成功率 52.4%,较π₀基线(42.3%)提升 10.1%
- LIBERO:平均成功率 96.5%,超越当前SOTA方法UniVLA(95.2%),其中Long套件达94.0%
- 消融实验:历史Track Encoder(+2.5%)、Future Track Query(+2.4%)、深度监督(+2.2%)、轨迹引导细化(+1.9%)逐步提升性能
- 真实世界实验:在空间泛化、几何泛化和视觉鲁棒性任务上均表现优异