一眼看懂
封面预览
提出利用人类第一视角(egocentric)视频作为桥梁,将视觉语言模型(VLM)的能力迁移到物理智能(Physical Intelligen…
- 提出利用人类第一视角(egocentric)视频作为桥梁,将视觉语言模型(VLM)的能力迁移到物理智能(Physical Intelligen…
- 核心挑战在于:传统VLM依赖第三人称训练数据,而人形机器人需要第一视角感知;收集大规模机器人数据成本高昂且难以扩展,而人类第一视角视频虽丰富但…
- 提出Egocentric2Embodiment Translation Pipeline,将原始人类第一视角视频转换为多层级、模式驱动的具身监…
Card 01
研究单位
研究单位
- The Hong Kong University of Science and Technology (Guangzhou)
- Zhongguancun Academy
- Zhongguancun Institute of Artificial Intelligence
- DeepCybo
- Harbin Institute of Technology
- Huazhong University of Science and Technology
Card 02
论文概述
论文概述
- 提出利用人类第一视角(egocentric)视频作为桥梁,将视觉语言模型(VLM)的能力迁移到物理智能(Physical Intelligence),解决机器人第一视角感知与行动中的视角鸿沟问题
- 核心挑战在于:传统VLM依赖第三人称训练数据,而人形机器人需要第一视角感知;收集大规模机器人数据成本高昂且难以扩展,而人类第一视角视频虽丰富但存在本体差异(embodiment mismatch)
Card 03
核心贡献
核心贡献
- 提出Egocentric2Embodiment Translation Pipeline,将原始人类第一视角视频转换为多层级、模式驱动的具身监督信号,包含规划分解、关键状态、交互约束和时间关系
- 构建大规模数据集E2E-3M(300万验证样本),覆盖家庭、工厂、实验室三大领域,提供结构化第一视角VQA监督
- 训练得到PhysBrain模型,在第一视角VLM基准(EgoThink、EgoPlan)和VLA基准(SimplerEnv、RoboCasa)上均取得显著性能提升
- 证明人类第一视角视频可作为有效的物理监督来源,实现从人类经验到机器人控制的样本高效迁移
Card 04
方法描述
方法描述
- 数据流程:场景感知时间分割 → 七模式VQA生成(时间、空间、属性、力学、推理、摘要、轨迹)→ 规则验证(证据锚定、第一视角一致性、时间逻辑)→ 结构化语料库
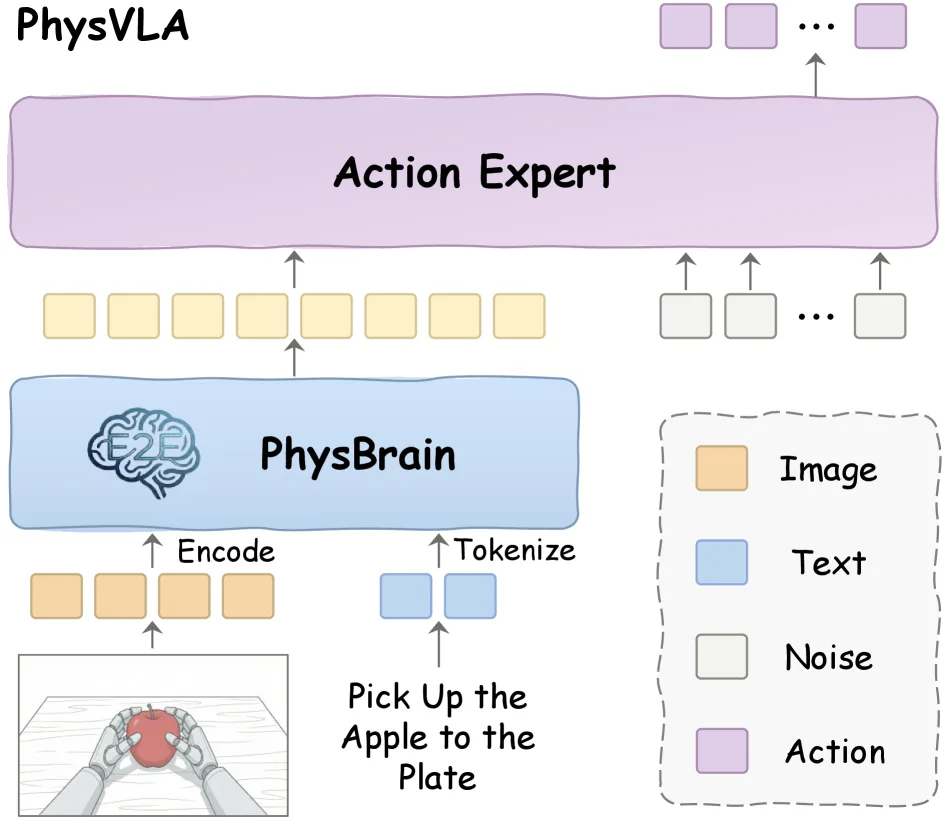
- 模型架构:基于Qwen3-VL进行监督微调,混合FineVision通用语料保持通用能力;VLA系统采用PhysVLA设计,VLM作为System 2生成高层表征,Flow-Matching扩散模型作为System 1生成连续动作
- 训练策略:双系统架构(VLM + DiT动作专家),使用8步去噪,动作块长度K=16
Card 05
数据集与资源
数据集与资源
- E2E-3M数据集:约300万验证样本,来源包括Ego4D、BuildAI、EgoDex
- 模型规模:PhysBrain-4B(基于Qwen3-VL-4B)、PhysBrain-8B(基于Qwen3-VL-8B)
- 领域覆盖:家庭环境(高物体多样性)、工厂环境(标准化流程)、实验室环境(精细操作)
- 多样性指标:ObjectDiv和VerbDiv量化分析,确保物体和动作语义覆盖
Card 06
评估与结果
评估与结果
- VLM评估基准:EgoPlan-B1/B2(多选题规划)、EgoThink(六维度第一视角理解,GPT-4评判)
- VLA评估基准:SimplerEnv(WidowX机器人4任务)、RoboCasa(GR1机器人24项桌面操作任务)
- 关键结果:
- EgoThink平均得分:PhysBrain-8B达69.7%,超越Qwen3-VL-8B(65.9%)及RoboBrain2.5(62.4%)
- EgoPlan-B1/B2:PhysBrain-8B达47.4%/46.9%,较基线提升+3.1/+6.4
- SimplerEnv:PhysBrain-8B平均成功率67.4%,与RoboBrain2.5(67.6%)相当,但无需机器人数据预训练
- RoboCasa:PhysBrain-8B平均成功率55.25%,超越Isaac-GR00T-N1.6(47.6%)及QwenGR00T(47.8%)