一眼看懂
封面预览
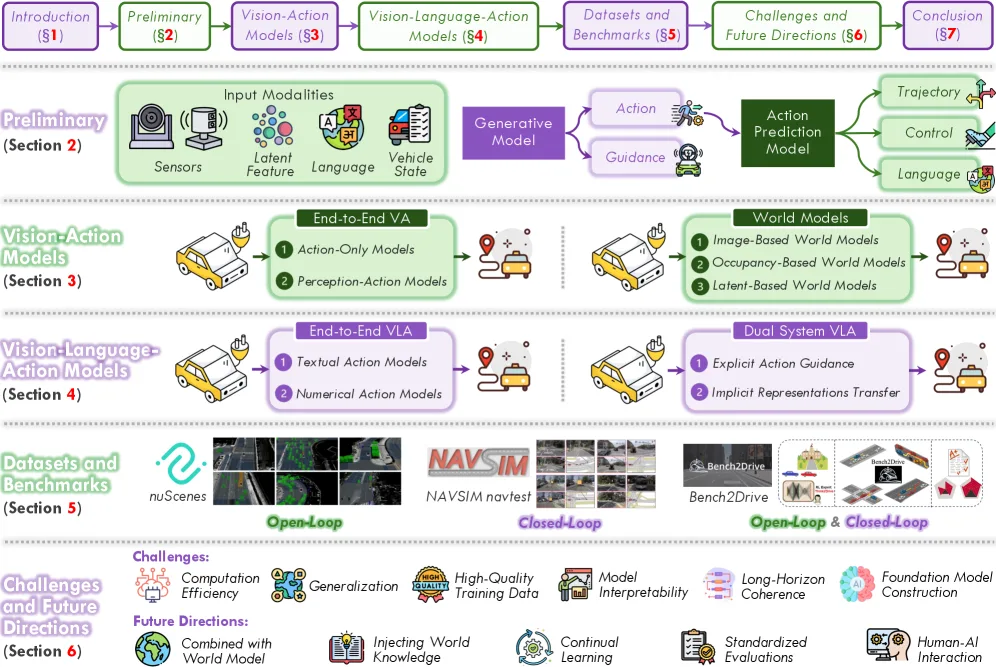
本文系统综述了Vision-Language-Action (VLA) 模型在自动驾驶领域的演进历程,从早期的 Vision-Action (…
- 本文系统综述了Vision-Language-Action (VLA) 模型在自动驾驶领域的演进历程,从早期的 Vision-Action (…
- 旨在解决传统模块化自动驾驶系统中手工设计接口、规则驱动组件在复杂长尾场景下的局限性,以及 VA 模型缺乏可解释性、推理能力和人机交互的问题
- 提出了统一的 VLA 范式分类体系,涵盖端到端 VLA 和双系统 VLA 两大架构,为构建更可解释、可泛化、人机对齐的自动驾驶策略提供理论基础
Card 01
研究单位
研究单位
- HKUST(香港科技大学)
- Zhejiang University(浙江大学)
- National University of Singapore(新加坡国立大学)
- HKUST(GZ)(香港科技大学广州校区)
- DAMO Academy, Alibaba(阿里巴巴达摩院)
- University of California, Los Angeles(加州大学洛杉矶分校)
- Xiaomi EV(小米汽车)
- Xi'an Jiaotong University(西安交通大学)
- Nanyang Technological University, Singapore(新加坡南洋理工大学)
- WorldBench Team
Card 02
论文概述
论文概述
- 本文系统综述了Vision-Language-Action (VLA) 模型在自动驾驶领域的演进历程,从早期的 Vision-Action (VA) 模型发展到现代 VLA 框架
- 旨在解决传统模块化自动驾驶系统中手工设计接口、规则驱动组件在复杂长尾场景下的局限性,以及 VA 模型缺乏可解释性、推理能力和人机交互的问题
- 提出了统一的 VLA 范式分类体系,涵盖端到端 VLA 和双系统 VLA 两大架构,为构建更可解释、可泛化、人机对齐的自动驾驶策略提供理论基础
Card 03
核心贡献
核心贡献
- 追溯从 VA 模型到 VLA 框架的演进路径,提供历史背景和技术脉络
- 提出层次化分类体系,将 VLA 架构划分为端到端 VLA(单系统)和双系统 VLA(慢思考+快执行),并进一步细分为文本动作生成器、数值动作生成器、显式/隐式引导机制等子类
- 系统整理 VLA 自动驾驶相关的数据集和评估基准,支持开放环和闭环驾驶智能评估
- 识别 VLA 实际部署的关键挑战,包括模型架构效率、数据泛化、核心能力与可信度,并展望下一代模型范式、智能适应能力和安全部署生态等未来方向
- 建立项目页面、GitHub 仓库和 HuggingFace 排行榜,促进社区协作与标准化评估
Card 04
方法描述
方法描述
- VLA 统一框架:基于公式 a_t = H(F(x\|θ)),包含多模态输入(视觉图像、LiDAR、BEV/占用栅格、语言指令、车辆状态)、VLM 主干网络(视觉编码器+LLM 解码器+桥接网络)、动作预测头(语言头 LH、回归 REG、轨迹选择 SEL、轨迹生成 GEN)
- 端到端 VLA:VLM 直接生成动作,包括文本动作生成器(输出自然语言或离散动作 token)和数值动作生成器(输出连续控制信号或轨迹点)
- 双系统 VLA:分离高层推理与低层执行,包括显式动作引导(VLM 生成文本理由或结构化意图,由下游规划器转为轨迹)和隐式表征迁移(VLM 输出潜在表征指导动作专家)
- 动作表示:涵盖离散轨迹(航点序列)、连续轨迹(速度/曲率函数)、直接控制(转向/油门/刹车)和语言表示四种范式
Card 05
数据集与资源
数据集与资源
- Vision-Action 数据集:CARLA、NoCrash、ProcGen、Lyft、nuScenes、Bench2Drive、NAVSIM、OpenOcc、OpenDV、nuPlan、Occ3D、Cam4DOcc 等
- Vision-Language-Action 数据集:涵盖带语言标注的驾驶指令、推理链、人机对话数据
- 评估基准:nuScenes Benchmark、WOD-E2E Benchmark、NAVSIM Benchmark、Bench2Drive Benchmark
- 开源资源:项目页面 https://worldbench.github.io/vla4ad、GitHub 仓库 https://github.com/worldbench/awesome-vla-for-ad、HuggingFace 排行榜 https://huggingface.co/spaces/worldbench/vla4ad
Card 06
评估与结果
评估与结果
- 评估指标:轨迹级动作评估(L2 距离、碰撞率、通过率、舒适度指标)和文本级动作评估(语言指令跟随准确率、推理链正确性、可解释性评分)
- 代表性模型性能:涵盖 LBC、Latent-DRL、NEAT、Roach、WoR、TCP、Urban-Driver、LAV、TransFuser、GRI、BEVPlanner、Raw2Drive、RAD、TrajDiff 等 VA 模型,以及 DriveMLM、GPT-Driver、LMDrive、DriveLM、DriveGPT4、AutoVLA、DriveVLM、VLP、Diff-VLA、InsightDrive 等 VLA 模型
- 关键发现:VLA 模型在可解释性、指令跟随、长尾场景泛化方面显著优于纯 VA 模型,但端到端 VLA 面临实时性与安全性的权衡,双系统 VLA 通过分离推理与执行有效缓解该问题